







1、什么是模块化?
- 到底什么是模块化、模块化开发呢?
- 事实上模块化开发最终的目的是将程序划分成一个个小的结构;
这个结构中编写属于自己的逻辑代码,有自己的作用域,定义变量名词时不会影响到其他的结构;- 这个结构可以将自己希望暴露的变量、函数、对象等导出给其结构使用;
- 也可以通过某种方式,导入另外结构中的变量、函数、对象等;
- 上面说提到的结构,就是模块;按照这种结构划分开发程序的过程,就是模块化开发的过程;
- 无论你多么喜欢JavaScript,以及它现在发展的有多好,它都有很多的缺陷:
- 比如var定义的变量作用域问题;
- 比如JavaScript的面向对象并不能像常规面向对象语言一样使用class;
- 比如JavaScript没有模块化的问题;
2、以前没有模块化时的实现方案
- ECMAScript没有推出来自己的模块化方案时,社区中常用的自己实现的模块化方案有:CommonJS/AMD/CMD。
- ES6(ES2015)推出自己的模块化方案:我们称之为ESModule
下面为自己实现的一个模块化方案简单示例:
// aaa.js
const moduleA = (function(){
let name = 'why'
let age = 18
let height = 1.88
return {
name,
age,
height
}
}())
// bbb.js
const moduleB = (function(){
let name = 'mary'
let age = 20
let height = 1.66
return {
name,
age,
height
}
}())
// util.js
console.log(moduleA.name); // why
console.log(moduleB.name); // mary
3、CommonJS规范和Node关系
- 我们需要知道CommonJS是一个规范,最初提出来是在浏览器以外的地方使用,并且当时被命名为ServerJS,后来为了体现它的广泛性,修改为CommonJS,平时我们也会简称为CJS。
- Node是CommonJS在服务器端一个具有代表性的实现;
- Browserify是CommonJS在浏览器中的一种实现;
- webpack打包工具具备对CommonJS的支持和转换;
- 所以,Node中对CommonJS进行了支持和实现,让我们在开发node的过程中可以方便的进行模块化开发;
- 在Node中每一个js文件都是一个单独的模块;
- 这个模块中包括CommonJS规范的核心变量:exports、module.exports、require;
- 我们可以使用这些变量来方便的进行模块化开发;
- 前面我们提到过模块化的核心是导出和导入,Node中对其进行了实现:
- exports和module.exports可以负责对模块中内容进行导出;
- require函数可以帮助我们导入其他模块(自定义模块、系统模块、第三方库模块)中的内容;
3.1、CommonJS基本用法
简单的实现:
// util.js
const UTIL_NAME = 'util_name'
function formatDate() {
return '2011-11-11'
}
exports.UTIL_NAME = UTIL_NAME
exports.formatDate = formatDate
// main.js
const {UTIL_NAME, formatDate} = require('./util.js')
console.log(UTIL_NAME); // util_name
console.log(formatDate()); // 2011-11-11
3.2、exports导出
- 注意:exports是一个对象,我们可以在这个对象中添加很多个属性,添加的属性会导出;
exports.name = name
exports.age = age
exports.sayHello = sayHello
- 另外一个文件中可以导入:
const bar = require('./bar')
- 上面这行完成了什么操作呢?理解下面这句话,Node中的模块化一目了然:
- 意味着main中的bar变量等于exports对象;
- 也就是require通过各种查找方式,最终找到了exports这个对象;
- 并且将这个exports对象赋值给了bar变量;
- bar变量就是exports对象了;
- 其本质就是做了对象的引用赋值;
3.3、module.exports导出
- 但是Node中我们经常导出东西的时候,又是通过module.exports导出的;
- module.exports和exports有什么关系或者区别呢?
- 我们追根溯源,通过维基百科中对CommonJS规范的解析:
- CommonJS中是没有module.exports的概念的;
- 但是为了实现模块的导出,Node中使用的是Module的类,每一个模块都是Module的一个实例,也就是module;
- 所以在Node中真正用于导出的其实根本不是exports,而是module.exports;
- 因为module才是导出的真正实现者;
- 但是,为什么exports也可以导出呢?
- 这是因为module对象的exports属性是exports对象的一个引用;
- 也就是说module.exports = exports = main中的bar;
3.3.1、module.exports默认写法
默认的写法下,module.exports和exports指向的是同一个对象:
const name = 'foo'
const age = 18
function sayHello() {
return 'sayHello'
}
// 1.在开发中使用的很少
// exports.name = name
// 2.将模块中的内容导出
// 结论:Node导出的本质是在导出module.exports对象
module.exports.name = name
module.exports.age = age
module.exports.sayHello = sayHello
console.log(exports.name); // foo
console.log(exports === module.exports); // true
3.3.2、module.exports开发中常见写法
不过下面这种写法新建了一个对象(module.exports跟exports不再指向同一个引用了),跟之前的exports对象不再有任何关系了:
// foo.js
const name = 'foo'
const age = 18
function sayHello() {
return 'sayHello'
}
module.exports = {
name,
age,
sayHello
}
exports.name = "哈哈哈哈"
module.exports.name = '嘿嘿嘿嘿'
// main.js
const foo = require('./foo.js')
console.log(foo.name); // 嘿嘿嘿嘿
3.4、require细节——查找规则
- 我们现在已经知道,require是一个函数,可以帮助我们引入一个文件(模块)中导出的对象。
- 那么,require的查找规则是怎么样的呢?
- 这里我总结比较常见的查找规则:
- 导入格式如下:require(X)
3.4.1、规则一——X是一个Node核心模块
情况一:X是一个Node核心模块时,比如path、http,直接返回核心模块,并且停止查找。
const path = require("path")
const http = require("http")
3.4.2、规则二——X是以./或…/或/(根目录)开头的
情况二:X是以./或…/或/(根目录)开头的
- 第一步:将X当做一个文件在对应的目录下查找;
- 1.如果有后缀名,按照后缀名的格式查找对应的文件
- 2.如果没有后缀名,会按照如下顺序:
√ 1> 直接查找文件X
√ 2> 查找X.js文件
√ 3> 查找X.json文件
√ 4> 查找X.node文件
- 第二步:没有找到对应的文件,将X作为一个目录
- 查找目录下面的index文件
√ 1> 查找X/index.js文件
√ 2> 查找X/index.json文件
√ 3> 查找X/index.node文件
- 如果没有找到,那么报错:not found
3.4.3、规则三——直接是一个X(没有路径),并且X不是一个核心模块
情况三:直接是一个X(没有路径),并且X不是一个核心模块。
- 第一步:会先在当面目录下的node_modules文件里面查找
- 第二步:没有node_modules目录或者有node_modules目录但目录下没有对应模块的话,会在上层目录的node_modules里面查找,依次找到根目录的node_modules,
- 最后,都没有的话报错:not found
3.5、模块的加载过程
- 结论一:模块在被第一次引入时,模块中的js代码会被运行一次
- 结论二:模块被多次引入时,会缓存,最终只加载(运行)一次
- 为什么只会加载运行一次呢?
- 这是因为每个模块对象module都有一个属性:loaded
- 为false表示还没有加载,为true表示已经加载
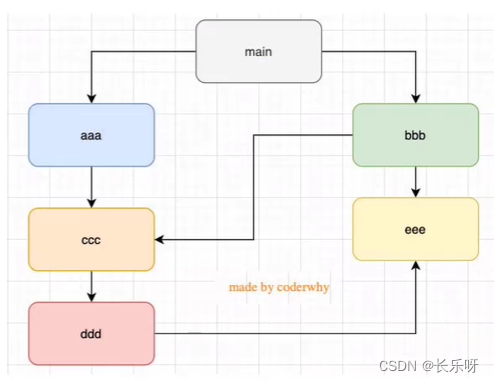
- 结论三:如果有循环引入,那么加载顺序是什么?
- 如果出现下图模块的引用关系,那么加载顺序是什么呢?
- 这个其实是一个数据结构:图结构
- 图结构在遍历的过程中,有深度优先搜索(DFS,depth first search)和广度优先搜索(BFS,breadth first search)
- Node采用的是深度优先算法:main -> aaa -> ccc -> ddd -> eee ->bbb
3.6、CommonJS规范缺点
- CommonJS加载模块是同步的:
- 同步的意味着只有等到对应的模块加载完毕,当前模块中的内容才能被运行;
- 这个在服务器不会有什么问题,因为服务器加载的js文件都是本地文件,加载速度非常快;
- 如果将它应用于浏览器呢?
- 浏览器加载js文件需要先从服务器将文件下载下来,之后再加载运行;
- 那么采用同步的就意味着后续的js代码都无法正常运行,即使是一些简单的DOM操作;
- 所以在浏览器中,我们通常不使用CommonJS规范:
- 当然在webpack中使用CommonJS是另外一回事;
- 因为它会将我们的代码转成浏览器可以直接执行的代码;
- 在早期为了可以在浏览器中使用模块化,通常会采用AMD或CMD:
- 但是目前一方面现代浏览器已经支持ES Modules,另一方法借助于webpack等工具可以实现对CommonJS或者ES Module代码的转换;
- AMD和CMD已经使用非常少了;
4、AMD规范
- AMD主要是应用于浏览器的一中模块化规范:
- AMD是Asynchronous Module Definition(异步模块定义)的缩写;
- 它采用的是异步加载模块;
事实上AMD的规范还有早于CommonJS,但是CommonJS目前依然在被使用,而AMD使用的较少了;
- 我们提到过,规范只是定义代码应该如何去编写,只有有了具体的实现才能被应用:
- AMD实现的比较常用的库是require.js和curl.js;
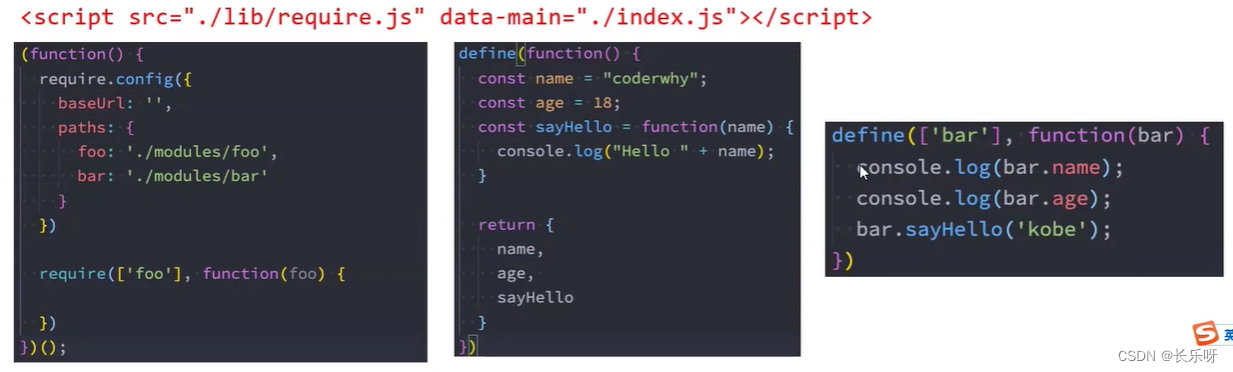
4.1、require.js的使用
- 第一步:下载require.js
- 下载地址:require.js下载地址
- 找到其中的require.js文件;
- 第二步:定义HTML的script标签引入require.js和定义入口文件
- data-main属性的作用是在加载完src的文件后会加载执行该文件
5、CMD规范
- CMD规范也是应用于浏览器的一直模块化规范:
- CMD是Common Module Definition(通用模块定义)的缩写;
- 它也采用的是异步加载模块,但是它将CommonJS的优点吸收了过来;
- 但是目前CMD使用也非常少了;
- CMD也有自己比较优秀的实现方案:
- SeaJS
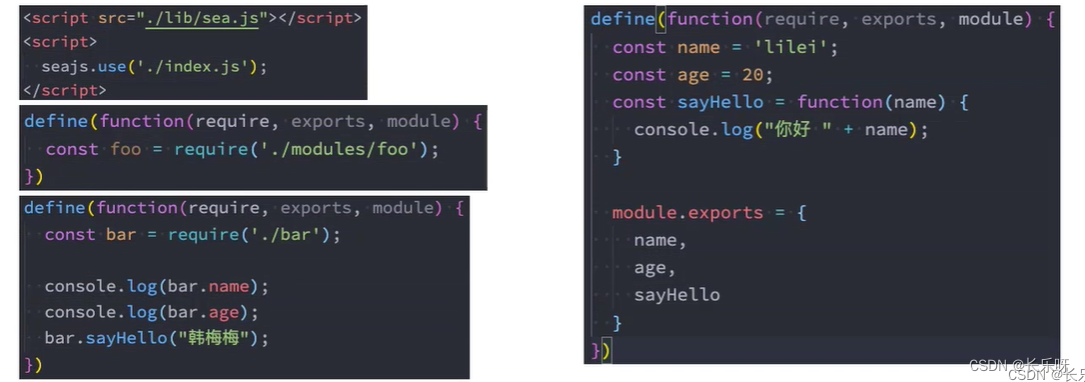
5.1、SeaJS的使用
- 第一步:下载SeaJS
- 下载地址:SeaJS下载地址
- 找到dist文件夹下的sea.js
- 第二步:引入sea.js和使用主入口文件
- seajs是指定主入口文件的















 749
749











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









