







目录
8、如果发现线程池中的线程经常处于空闲状态,但系统响应依然很慢,如何排查优化?
10、在大型分布式系统中,多个模块都使用了线程池,如何避免全局资源竞争和死锁的发生?
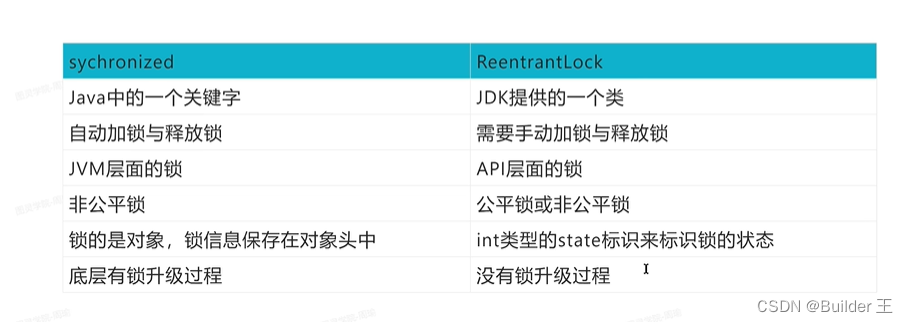
15、Sychronized 和 ReentrantLock有哪些不同点?
线程池相关
1、什么是线程池?使用线程池有什么好处?
线程池是一种池化管理线程的工具,线程类的顶层是excutor接口,主要解决的就是资源管理问题,
使用线程池具有以下好处:
1、降低资源消耗:通过池化技术重复利用已创建的线程,降低新建与销毁的开销
2、提高响应速度:任务直接到达可直接执行,无需等待
3、提高线程的可管理性,避免了线程无限制的创建
4、具备可拓展性
2、几种常用的线程池?

实际上这些线程池的底层都时ThreadPoolExcutor, 只不过提供了一些默认参数。根据阿里巴巴手册,在代码中我们应该直接使用ThreadPoolExcutor,自己来指定参数。

3、线程池的七大核心参数?
corePoolSize:核心线程数量,会一直存在,除非allowCoreThreadTimeOut设置为true
maximumPoolSize:线程池允许的最大线程池数量
keepAliveTime:线程数量超过corePoolSize,空闲线程的最大超时时间
unit:超时时间的单位
workQueue:工作队列,保存未执行的Runnable 任务
threadFactory:创建线程的工厂类
handler:当线程已满,工作队列也满了的时候,会被调用。被用来实现各种拒绝策略。
4、线程池的工作原理(执行流程)?

5、四种拒绝策略是什么?

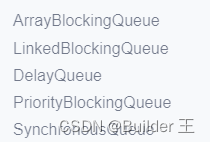
6、五种工作队列是什么?
7、如何合理设定线程池的参数?(重中之重)
7.1 如何设定核心线程数?(大多面试可能只问这一个)

7.2 如何选择拒绝策略?
企业级应用一般选择 callerRunsPolicy, 因为大多数场景都不需要丢弃任务,而且为了保证系统的稳定性和可靠性,避免出现OOM, 最大线程数和工作队列长度都不是Int.max_value,系统不能异常。所以abortPolicy不行,另外两种都会丢任务,所以只能选择callerRunsPolicy。
7.3 如何选择等待队列?
xxxxxx
7.4 自定义线程工厂
定义工厂的目的是规范线程名称,定义优先级,打印日志,这样便于后期系统分析与监控。
(最后总结点睛),目前为止,还没有一个能够适用于所有企业的线程池最佳使用实践以供参考,参数的设定其实也不是一成不变的,要根据公司实际情况不断做具体的测试和参数调整,目前来说最佳的方法就是使用美团的动态线程池,能够时刻监控线程池状态,动态调整各参数,且成本较低。
8、如果发现线程池中的线程经常处于空闲状态,但系统响应依然很慢,如何排查优化?

9、线上的线程池存在性能瓶颈,如何定位与优化?

10、在大型分布式系统中,多个模块都使用了线程池,如何避免全局资源竞争和死锁的发生?

11、为什么队列都是阻塞队列不是非阻塞队列?
阻塞队列可以保证任务队列中没有任务时阻塞获取任务的线程,使线程进入wait状态,释放cpu资源,而不是一直占用。这是核心目的。
不用阻塞队列,你就需要额外想办法达成这个目的,有好用的为啥不直接用呢。
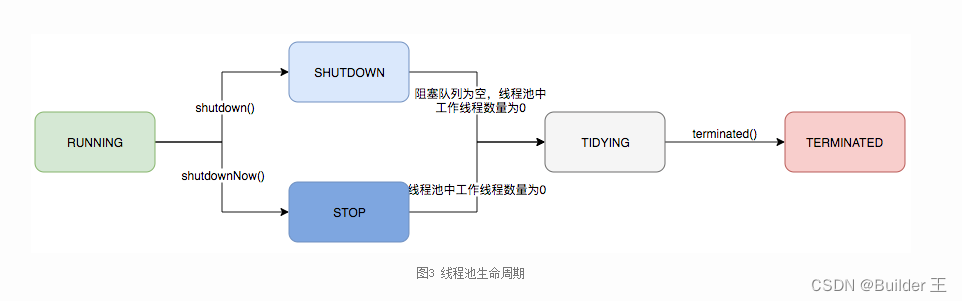
12、线程池的运行状态?(注意和线程的状态别搞混了)
1、runnning 2、shutdown 3、stop 4、tidying 5、terminated

13、如何设计一个线程池?(最终最难最高级的面试题)?
基本上就是把以上内容全部融汇贯通了,并且能用伪代码实现的层次
其他
13、java有哪几种方式来创建线程执行任务?
1、继承thread类, 重写run方式,调用start方法
class MyThread extends Thread {
@override
public void run() {
log.info("执行任务逻辑")
}
}
public static void main(String []arg) {
MyThread test = new MyThread();
test.run();
}
// 优点: 实现简单
/**
*
* 缺点: java是单继承,如果该任务类已经继承了别的类,就不能这样使用了
*/2、实现runable类,重写run方法
class MyRunable implements Runable {
@override
public void run() {
log.info("执行任务逻辑")
}
}
public static void main() {
Thread myThread = new Thread(new MyRunable());
myThread.start();
}
// 优点: 相当于第一种方法,java类可以多实现,更为常用
// 另外一种写法
Thread thread = new Thread(()-> {
log.info("执行任务逻辑");
});
thread.start();
3、实现callable 类
class MyCallable implements Callable {
@override
public void call() {
log.info("执行代码逻辑");
}
public static void main() {
FatureTask<String> futureTask = new FatureTask<>(new MyCallable());
Thread thread = new Thread(futureTask);
thread.start();
String result = new futureTask.get();
log.info("子线程的执行结果为")
}
}
// 优点: 可以获取到线程的执行结果4、使用线程池
class MyRunable implements Runable {
@override
public void run() {
log.info("执行任务逻辑");
}
public static void main() {
ExcutorServide service = Excutors.newFixedThreadPool(10);
service.excute(new MyRunable());
}
}14、为什么不建议使用Excutors创建线程池?
1、使用Excutors 创建的线程池底层采用的是LinkedBlockingQueue, 请求会一直积压,具有OOM的风险。
2、使用Excutors 接触不到相关参数,不便于记录与控制
3、不够灵活
ExcuteService service = new ThreadPoolExcutor(
int corePoolSize, //核心线程数
int maximumPoolSize, // 最大线程数
long keepAliveTime, // 空闲线程存活时间
TimeUnit unit, // 时间单位
BlockingQueue<Runnable> workQueue, // 线程池任务队列
ThreadFactory threadFactory, // 创建线程池的工厂
RejectedExecutionHandler handler // 拒绝策略
)15、Sychronized 和 ReentrantLock有哪些不同点?
16、ReentrantLock 分为公平锁和非公平锁,那底层分别是如何实现的
首先,不管是公平锁还是非公平锁,他们的底层实现都是采用 AQS来进行排队的。
区别在于,在使用lock进行加锁时,如果是公平锁,则会先去AQS队列中判断是否存在线程排队,如果有,则当前线程也会排队。
非公平锁,则不会去检查是否有线程在排队,而是直接竞争锁。
但是不管是公平锁还是非公平过,竞争锁失败都会排队
16、如何优雅的停掉一个线程?
17、线程的常用方法
// 获取当前线程
Thread.currentThread();
18、代码实现生产者和消费者模型
一共有三种,第一种,通过sychronized和wait+notify实现
class ResourcePool {
private int maxSize;
private ArrayList<Integer> list;
public ResourcePool (int maxSize, ArrayList list){
this.maxSize = maxSize;
this.list = list;
}
public sychronized void add(Integer value) {
while(list.size() >= maxSize) {
try {
wait();
} catch (Exception e) {
log.error("程序add过程中发生异常", e);
}
}
list.add(value);
notifyAll();
}
public sychronized void increment(Integer value) {
while(list.size() <= 0) {
try {
wait();
} catch (Exception e) {
log.error("程序increment过程中发生异常", e);
}
}
list.removeFirst(value);
notifyAll();
}
}
class Product extends Thread{
private ResourcePool pool;
public Product (ResourcePool pool) {
this.pool = pool;
}
@Override
public void run() {
pool.add(1);
}
}
class Comsule extends Thread{
private ResourcePool pool;
public Product (ResourcePool pool) {
this.pool = pool;
}
@Override
public void run() {
pool.increment(1);
}
}
class client {
ResourcePool pool = new ResourcePool (10, new ArrayList());
public static void main() {
for(int i=0; i<10; i++) {
new Product(pool).start();
}
for(int i=0; i<10; i++) {
new Comsule(pool).start();
}
}
}第二种,lock + condition实现
class ResourceBuffer {
private int maxSize;
private List<Integer> list;
private Lock lock;
private Condition productCondition;
private Condition consumeCondition;
public ResourceBuffer (int maxSize, List<Integer> list) {
this.maxSize = maxSize;
this.list = list;
}
private void add (int value) {
try {
lock.lock();
while( list.size() >= maxSize ) {
try {
productCondition.await();
} catch (Exception e) {
e.printStackTrace();
}
}
list.add(value);
consumeCondition.signalAll();
} catch (Exception e) {
} finally {
lock.unLock();
}
}
public void consume() {
lock.lock();
try{
while (list.size() == 0) {
try {
consumerCondition.await();
} catch (InterruptedException e) {
e.printStackTrace();
}
}
Integer value = (Integer) list.removeFirst();
producerCondition.signalAll();
}catch (Exception e){
e.printStackTrace();
}finally {
lock.unlock();
}
}
}第三种 BlockingQueue
package 线程基础.生产者消费者模型.阻塞队列版本;
import java.util.concurrent.BlockingQueue;
import java.util.concurrent.LinkedBlockingQueue;
public class BufferResources {
private int maxSize = 10;
//阻塞队列作为缓冲区
private BlockingQueue buffer = new LinkedBlockingQueue(maxSize);
public void consume() {
try {
Integer value = (Integer) buffer.take();
System.out.println(Thread.currentThread().getName() + " 消费成功:" + value.toString() + " 当前缓冲区size = " + buffer.size());
} catch (InterruptedException e) {
e.printStackTrace();
}
}
public void product(Integer value) {
try {
buffer.put(value);
System.out.println(Thread.currentThread().getName() + " 生产成功:" + value.toString() + " 当前缓冲区size = " + buffer.size());
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
锁、AQS、CAS:
1、什么是公平锁,什么是非公平锁?什么是独占锁?共享锁?
公平锁:是指多个线程按照申请锁的顺序来获取锁,类似排队打饭,先来后到。
非公平锁:是指多个线程获取锁的顺序并不是按照申请锁的循序,有可能后申请的线程比先申请的线程优先获取锁。但是,在高并发的情况下,有可能会造成优先级反转或者饥饿现象。
非公平锁比公平锁吞吐量大,sychronized是非公平锁、reetrantLock默认是非公平锁,AQS是公平锁,内部维护的是一个FIFO的队列
独占锁:指锁只能被一个线程持有,sychronized、reetrantLock都是独占锁
共享锁:同一时刻可以被多个线程占有
2、什么是AQS?
3、什么是CAS?有没有缺点?
1、采用自旋方式,循环时间长,开销大
4、什么是Unsafe类?
5、sychrionize和lock的区别
4、lock提供了公平锁和非公平锁两种的支持,Synchronized 只是非公平锁
5、从性能方面来看,其实差别不大,synchronized 引入了偏向锁、轻量级锁、重量级锁以及锁升级的方式来 优化加锁的性能,而 Lock 中则用到了自旋锁的方式来实现性能优化
6、什么是死锁?
1、互斥条件 2、请求和保持条件 3、不可抢占 4、循环等待
7、Sychronized的锁升级过程?
锁升级就是无锁 —> 偏向锁 —> 轻量级锁 —> 重量级锁 的一个过程,注意,锁只能升级,不能降级。流程图如下:

- JVM 启动后,锁资源对象直到有第一个线程访问时,它都是无锁状态,此时 Mark Word 内容如下:

偏向锁标识为 0,锁标识为 01。
- 当锁对象首次被某个线程(假如为线程 A,id 为
1000001)时,锁就会从无锁状态升级偏向锁。偏向锁会在 Mark Word 中的偏向锁线程 id 存储当前线程的id(1000001),偏向锁标识为 1,锁标识为 01,如下:

如果当前线程再次获取该锁对象,只需要比较偏向锁线程 id 即可。
- 当有其他线程(假如为线程 B,id 为
1000002)来竞争该锁对象,此时锁为偏向锁,这个时候会比较偏向锁的线程 id 是否为线程 B1000002,我们可以判断不是,所以会利用 CAS 尝试修改 Mark Word,如果成功,则线程 B 获取偏向锁成功,此时 Mark Word 中的偏向锁线程 id 为线程 B id1000002:

- 但如果失败了,就说明当前环境可能存在锁竞争,则需要执行偏向锁撤销操作。等到全局安全点时,JVM 会暂停持有偏向锁的线程 A,检查线程 A 的状态,若线程 A状态为不活跃或者已经执行完了同步代码块,则设置锁对象为无锁状态(线程 ID 为空,偏向锁 0 ,锁标志位为01)重新偏向,同时恢复线程 A,继续获取偏向锁。如果线程 A 的同步代码块还没执行完,则需要升级为轻量级锁。
- 在升级为轻量级锁之前,持有偏向锁的线程 A是暂停的,JVM 首先会在线程 A 的栈中创建一个名为锁记录的空间(
Lock Record),用于存放锁对象目前的 Mark Word 的拷贝,然后拷贝对象头中的 Mark Word 到线程 A 的锁记录中(官方称之为 Displaced Mark Word ),若拷贝成功,JVM 将使用 CAS 尝试将对象头重的 Mark Word 更新为指向线程 A 的Lock Record的指针,成功,线程 A 获取轻量级锁,此时 Mark Word 的锁标志位为 00,指向锁记录的指针指向线程 A 的锁记录地址,如下图:

- 对于其他线程而言,也会在栈帧中建立锁记录,存储锁对象目前的 Mark Word 的拷贝。也利用 CAS 尝试将锁对象的 Mark Word 更正指向自身线程的 Lock Record,如果成功,表明竞争到轻量级锁,则执行同步代码块。如果失败,那么线程尝试使用自旋的方式来等待持有轻量级锁的线程释放锁。当然,它不会一直自旋下去,因为自旋的过程也会消耗 CPU,而是自旋一定的次数,如果自旋了一定次数后还是失败,则升级为重量级锁,阻塞所有未获取锁的线程,等待释放锁后唤醒。
线程安全
1、你是怎么理解线程安全问题的?
2、AbstractQueuedSynchronized 为什么采用双向链表?
- 双向链表可以保持线程加入等待队列的顺序,即先加入的线程排在队列前面,后加入的线程排在队列后面。这有助于实现公平性,即等待时间较长的线程更有机会先获得锁。
- 便于在两端进行操作:
- 双向链表支持在队列的两端进行高效的操作,例如在头部添加新节点、在尾部移除节点等。这对于在等待队列中的线程状态的管理和维护是非常有用的。
- 节点的前驱和后继信息
- 每个等待队列节点都有指向其前驱节点和后继节点的引用。这使得在等待队列中的线程状态的变化可以高效地传播,例如当前驱节点释放锁时,可以唤醒后继节点。这对于实现线程的唤醒和阻塞是关键的
- 简化队列操作
- 双向链表的结构可以简化在队列中的节点插入、删除和移动等操作,而这些操作是在多线程环境下需要高效完成的
3、volatile关键字的作用
1、保证多线程环境下共享变量的可见性
2、通过增加内存屏障防止指令重排















 94
94











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









