







0. 前置环境
linux VMWare上搭建Centos7并配置网络用FinalShell连接(详细图文教程)
hadoop Centos7上搭建hadoop2.6.5详细图文教程
1. 安装scala环境
Master节点
将scala-2.11.8.tgz下载好后,上传至虚拟机,解压安装。
安装至/usr/local/src/

在~/.bashrc中添加scala环境
# set scala environment
export SCALA_HOME=/usr/local/src/scala-2.11.8
export PATH=$PATH:${SCALA_HOME}/bin
生效环境
[root@master src]# source ~/.bashrc
完成后,将scala和配置文件分发到slave1和slave2
[root@master src]# scp -r /usr/local/src/scala-2.11.8 root@slave1:/usr/local/src/
[root@master src]# scp -r /usr/local/src/scala-2.11.8 root@slave2:/usr/local/src/
[root@master src]# scp -r ~/.bashrc root@slave1:~/
[root@master src]# scp -r ~/.bashrc root@slave2:~/
同理,生效slave中的环境
2. 安装spark
Master节点
将spark-2.0.2-bin-hadoop2.6.tgz下载好后,上传至虚拟机,解压安装。
安装至/usr/local/src/
进入conf,拷贝一个spark-env.sh
[root@master spark-2.0.2-bin-hadoop2.6]# cd conf
[root@master conf]# cp spark-env.sh.template spark-env.sh
修改spark-env.sh文件,增加java、scala、hadoop和spark环境及配置信息
export JAVA_HOME=/usr/local/src/jdk1.8.0_172
export SCALA_HOME=/usr/local/src/scala-2.11.8
export HADOOP_HOME=/usr/local/src/hadoop-2.6.5
export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop
SPARK_MASTER_IP=master
SPARK_LOCAL_DIR=/usr/local/src/spark-2.0.2-bin-hadoop2.6
SPARK_DRIVER_MEMORY=1G
在conf中,拷贝一个slaves
[root@master conf]# cp slaves.template slaves
修改环境
slave1
slave2

完成后,将spark分发到slave1和slave2
[root@master src]# scp -r spark-2.0.2-bin-hadoop2.6/ root@slave1:/usr/local/src/
[root@master src]# scp -r spark-2.0.2-bin-hadoop2.6/ root@slave2:/usr/local/src/
3. 启动spark
Master节点
启动完Hadoop后,再启动spark
[root@master spark-2.0.2-bin-hadoop2.6]# sbin/start-all.sh
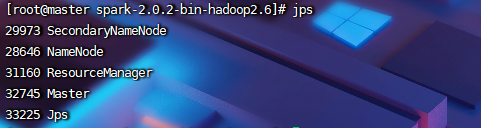
Spark安装成功!
















 915
915











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











