






1.给定100亿个整数,设计算法找到只出现一次的整数;
解题思路:有100亿个整数,一个整数4字节,共所占空间:100亿*4字节 = 10G*4 = 40G;所有整数的范围为0到42亿9千万;
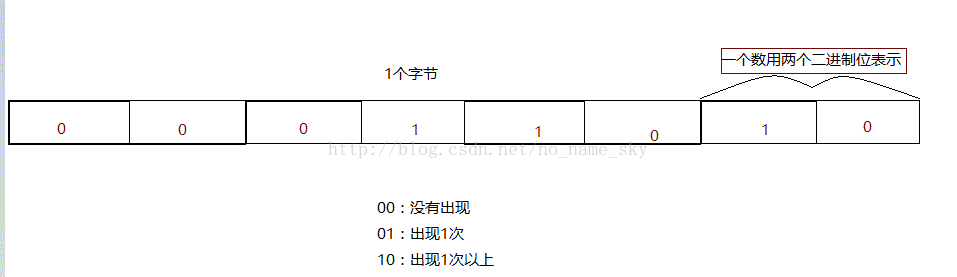
需要找到只出现一次的整数,那么我们就可以直接断定一个数出现的状态就有三个-------->没有出现,出现1次,出现1次以上。三种状态用两个二进制位足以表示;
使用位图的变形就可完成这个题的解答(由原来位图的1个位表示一个数,变形为2个位表示一个数);
40亿左右的整数,一个数用两个位表示,所占大约1G的空间;
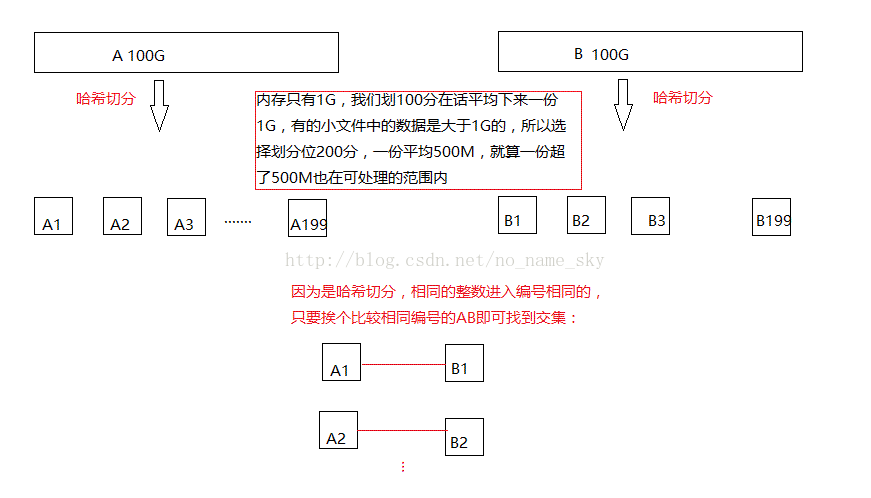
2.给两个文件,分别有100亿个整数,我们只有1G内存,如何找到两个文件交集?
3.1个文件有100亿个int,1G内存,设计算法找到出现次数不超过2次的所有整数?
4.给两个文件,分别有100亿个query,我们只有1G内存,如何找到两个文件交集?分别给出精确算法和近似算法?
1)给一个超过100G大小的log file,log中存着IP地址,设计算法找到出现次数最多的IP地址?(与如何知道top K的IP,如何使用Linux系统命令实现)
Hash分桶法:
将100G文件分成1000份,将每个IP地址映射到相应文件中:file_id = hash(ip) % 1000
在每个文件中分别求出最高频的IP,再合并Hash分桶法;
使用Hash分桶法把数据分发到不同的文件;
各个文件分别统计top K;
2)给定100亿个整数,设计算法找到只出现一次的整数。
Hash分桶法,将100亿个整数映射到不同的区间,在每个区间中分别找只出现一次的整数。
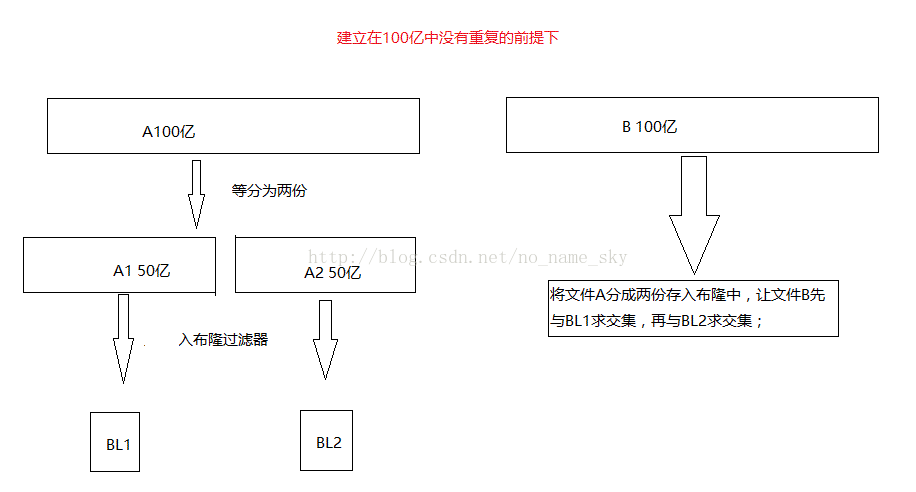
3)给两个文件,分别有100亿个整数,我们只有1G内存,如何找到两个文件交集
扫描每个整数是否出现过,节省内存方法使用bitmap。桶分 + bitmap。如果整数是32bit,直接使用bitmap的方法实现。所有整数共2^32种可能,每个数用两位表 示,00表示文件均没出现,10表示文件1出现过,01表示文件2出现过,11表示两文件均出现过,共需要2^32*2/8 = 1GB内存,遍历两个文件中的所有整数,然后寻 找bitmap中11对应的整数即是两个文件的交集,这样即可线性时间复杂度完成。
4)1个文件有100亿个int,1G内存,设计算法找大出现次数超过2次的所有整数。
Bitmap扩展:用2个bit表示状态,0表示未出现,1出现过1次,2出现过2次或以上。
5)给两个文件,分别有100亿个query,我们只有1G内存,如何找到两个文件交集?分别给出精确算法和近似算法?
精确算法:Hash分桶法
将两个文件中的query hash到N个小文件中,并标明query的来源;
在各个小文件中找到重合的query
将找到的重合query汇总
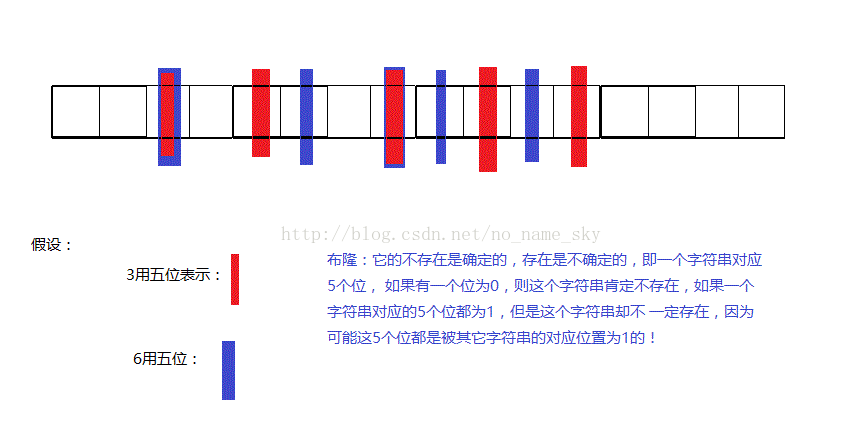
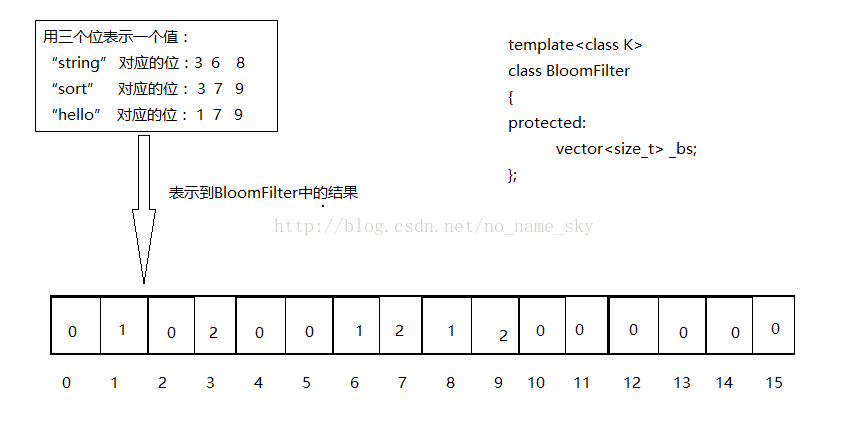
近似算法:BloomFilter算法
6)如何扩展BloomFilter使得它支持删除元素的操作
将BloomFilter中的每一位扩展为一个计数器,记录有多少个hash函数映射到这一位;删除的时候,只有当引用计数变为0时,才真正将该位置为0。
7)如何扩展BloomFilter使得它支持计数操作?
将BloomFilter中的每一位扩展为一个计数器,每个输入元素都要把对应位置加1,从而支持计数操作。计数个数为所有映射到的位置计数的最小值。
8)给上千个文件,每个文件大小为1K-100M。给n个词,设计算法对每个词找到所有包含它的文件,你只有100K内存。
1 : 首先把n个词分成x份。对每一份用生成一个布隆过滤器(因为对n个词只生成一个布隆过滤器,内存可能不够用)。把生成的所有布隆过滤器存入外存的一个文件Filter中。
2:将内存分为两块缓冲区,一块用于每次读入一个布隆过滤器,一个用于读文件(读文件这个缓冲区使用相当于有界生产者消费者问题模型来实现同步),大文件可以分为更小的文件,但需要存储大文件的标示信息(如这个小文件是哪个大文件的)。
3:对读入的每一个单词用内存中的布隆过滤器来判断是否包含这个值,如果不包含,从Filter文件中读取下一个布隆过滤器到内存,直到包含或遍历完所有布隆过滤器。如果包含,更新info 文件。直到处理完所有数据。删除Filter文件。
备注:
1:关于布隆过滤器:其实就是一张用来存储字符串hash值的BitMap.
2:可能还有一些细节问题,如重复的字符串导致的重复计算等要考虑一下。
9)一个词典,包含N个英文单词,现在任意给一个字符串,设计算法找出包含这个字符串的所有英文单词。
5.如何扩展BloomFilter使得它支持计数操作?















 1164
1164

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









