







 本文探讨了AI编译器与传统编译器的区别及其在深度模型部署中的应用,重点介绍了MLIR作为统一IR格式的角色及其核心组件Dialect的详细工作原理。
本文探讨了AI编译器与传统编译器的区别及其在深度模型部署中的应用,重点介绍了MLIR作为统一IR格式的角色及其核心组件Dialect的详细工作原理。
文章目录
前言
一、AI编译器
传统编译器与AI编译器

传统编译器的作用是降低编程难度;
AI编译器的作用主要是为了提高网络的性能;
部署深度模型





二、TPU-MLIP
TPU-MLIP整体架构

在模型转换的过程中会进行推理保证模型转换的正确性。

以YOLOV5s的转换为例



三、MLIR上
什么是MLIR

IR中间表达



Tensorflow 团队较早时采用了多种IR的部署,但是这样导致软件碎片化较为严重,因此Tensorflow 就提出了MLIR,用于统一各类的IR格式,协调各类IR的转换,带来更高的转换效率。
Dialect
什么是Dialect?
从源程序到目标程序,要经过一系列的抽象以及分析,通过Lowering Pass来实现从一个IR到另一个IR的转换,但是IR之间的转换需要统一格式,统一IR的第一步就是要统一“语言”,因此MLIR提出了Dialect,各种IR可以转换为对应的mlir Diaect,不仅方便了转换,而且还能随意扩展。
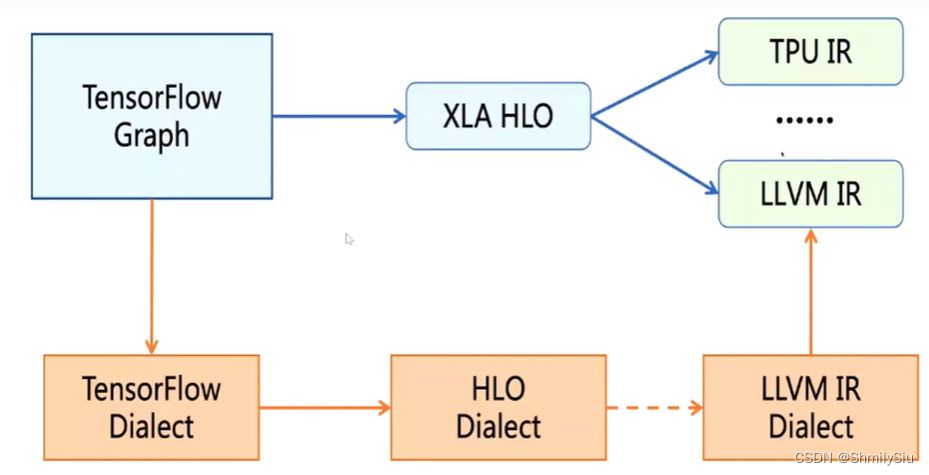
dialect是怎么工作的?
dialect将所有的IR放在了同一个命名空间中,分别对每个IR定义对应的产生式绑定相应的操作,从而生成一个MLIR模型。每种语言的dialect(如TensorFlow dialect、HLO dialect、LLVM IR dialect)都是继承自mlir::dialect,并注册了属性、操作和数据类型,也可以使用虚函数来改变一些通用性行为。
整个的编译过程:从源语言生成AST(Abstract Syntax Tree)抽象语法树,借助dialect遍历AST,产生MLIR表达式(此处可为多层IR通过Lowering Pass依次进行分析),最后经过MLIR分析器,生成目标硬件程序。

Dialect的内容
Dialect主要包括以下几个方面:
dialect主要是自定义的Type、Attribute、Interface以及operation构成。operation细分为attribute、type、constraint、interface、trait(属性、类型、限制、接口、特征)。同时存在ODS和DRR两个重要的模块,这两个模块都是基于tableGen模块,ODS模块用于定义operation,DRR模块用于实现两个dailect之间的conversion。

Opeartion
Opeartion是Dialect的重要组成部分,是抽象和计算的核心单元,可以看成是方言语义的基本元素。
%t_tensor = "toy.transpose"(%tensor) {inplace = true} : (tensor<2x3xf64>) -> tensor<3x2xf64> loc("example/file/path":12:1)
下面的代码可以理解为:生成的结果是 %t_tensor,toy dialect,执行的是 transpose 操作,输入数据是 %tensor,能够将 tensor<2x3xf64> 的数据转换成tensor<3x2xf64> 的数据,该 transpose 的位置在 “example/file/path”,第12行,第1个字符。
结构分析如下:
(1)%t_tensor:定义结果名称,SSA值,由%和<t_tensor>构成,一般<t_tensor>是一个整数型数字。
(2)toy.transpose:操作的名称,指明为Toy Dialect的transpose操作。
(3)(%tensor):输入的操作数的列表,多个操作数之间用逗号隔开。
(4){inplace = true}:属性字典,定义一个名为inplace的布尔类型,其常量值为true。
(5)(tensor<2x3xf64>) -> tensor<3x2xf64>:函数形式表示的操作类型,前者是输入,后者是输出。<2x3xf64>号中间的内容描述了张量的尺寸2x3和张量中存储的数据类型f64,中间使用x连接。
(6)loc(“example/file/path”:12:1):此操作的源代码中的位置。
格式图如下所示:

创建新的dialect(添加新的operation)
MLIR中创建新的dialect有两种方式,分别是直接在C++中定义以及在ODS(Operation Definition Specification)中定义,直接在C++中定义需要我们继承Op基类并重写部分构造函数,每个Op都要编写相应的C++代码,缺点是冗余且可读性比较差,所以我们一般使用ODS定义,操作者只需要根据operation框架定义的规范,在一个.td文件中填写相应的内容,使用MLIR的TableGen工具就可以自动生成上面的C++代码。

下面将以Toy语言为例,学习构造Toy Dialect并添加相应的Operation的流程。
Toy语言是为了验证及演示MLIR系统的整个流程而开发的一种基于Tensor的语言。
Toy 语言具有以下特性:
- Mix of scalar and array computations, as well as I/O
- Array shape Inference
- Generic functions
- Very limiter set of operators and features
(1)定义Toy Dialect
①使用C++语言手动编写
class ToyDialect : public mlir::Dialect {
public:
explicit ToyDialect(mlir::MLIRContext *ctx);
static llvm::StringRef getDialectNamespace() { return "toy"; }
void initialize();
};
②使用ODS框架自动生成
在使用ODS定义操作的这些代码,都在Ops.td中,默认位置为
…/mlir/examples/toy/Ch2/include/toy/Ops.td
下面的代码块定义一个名字为Toy的Dialect在ODS框架中,使用let <…> = “…”/[{…}];方式依次明确 name、summary、description 和 cppNamespace各个字段的定义。
def Toy_Dialect : Dialect {
let name = "toy";
let summary = "A high-level dialect for analyzing and optimizing the "
"Toy language";
let description = [{
The Toy language is a tensor-based language that allows you to define
functions, perform some math computation, and print results. This dialect
provides a representation of the language that is amenable to analysis and
optimization.
}];
let cppNamespace = "toy";
}
然后在编译阶段,由框架自动生成相应的C ++代码,也可以使用下面的命令得到生成的C++代码。
${build_root}/bin/mlir-tblgen -gen-dialect-decls ${mlir_src_root}/examples/toy/Ch2/include/toy/Ops.td -I ${mlir_src_root}/include/
下图中右侧是 ODS 中的定义,左侧是自动生成的 C++ 代码。

(2)加载到MLIRContext中
定义好Dialect之后,需要将其加载到MLIRContext中,默认情况下,MLIRContext只加载内置的Dialect,若要添加自定义的Dialect,需要加载到MLIRContext。
// 此处的代码与官方文档中的稍有不同,但实际意义相同。
// 在代码文件 toyc.cpp 中,默认位置为 ../mlir/examples/toy/Ch2/toyc.cpp。
int dumpMLIR() {
...
// Load our Dialect in this MLIR Context.
context.getOrLoadDialect<mlir::toy::ToyDialect>();
...
}
(3)定义operation
有了上面的Toy Dialect,便可以定义操作(Operation)。
# 此操作没有输入,返回一个常量。
%4 = "toy.constant"() {value = dense<1.0> : tensor<2x3xf64>} : () -> tensor<2x3xf64>
①使用C++语言手动编写
operation类是继承于CRTP类,有一些可选的traits来定义行为,下面是ConatntOp的官方定义:
class ConstantOp : public mlir::Op<
ConstantOp, // The ConstantOp
mlir::OpTrait::ZeroOperands, // takes zero input operands
mlir::OpTrait::OneResult, // returns a single result.
mlir::OpTraits::OneTypedResult<TensorType>::Impl> {
public:
// Op inherit the constructors from the base Op class.
using Op::Op;
// Return a unique name of the operation
static llvm::StringRef getOperationName() { return "toy.constant"; }
// Return a value by fetching it from the attribute
mlir::DenseElementsAttr getValue();
// Operations may provide additional verification beyond what the attached traits provide.
LogicalResult verifyInvariants();
// Provide an interface to build this operation from a set of input values.
// mlir::OpBuilder::create<ConstantOp>(...)
// Build a constant with the given return type and `value` attribute.
static void build(mlir::OpBuilder &builder, mlir::OperationState &state,
mlir::Type result, mlir::DenseElementsAttr value);
// Build a constant and reuse the type from the given 'value'.
static void build(mlir::OpBuilder &builder, mlir::OperationState &state,
mlir::DenseElementsAttr value);
// Build a constant by broadcasting the given 'value'.
static void build(mlir::OpBuilder &builder, mlir::OperationState &state,
double value);
};
定义好 operation 的行为后,我们可以在 Toy Dialect 的 initialize 函数中注册(register),之后才可以正常在 Toy Dialect 中使用 ConstantOp。
// 位于../mlir/examples/toy/Ch2/mlir/Dialect.cpp
void ToyDialect::initialize() {
addOperations<ConstantOp>();
}
②使用ODS框架自动生成
首先在ODS中定义一个继承自Op类的基类Toy_Op。
关于Operation与Op的区别:
Operation:对于所有操作的建模,并提供通用接口给操作的实例。
Op:每种特定的操作都是由Op类继承来的,同时它还是Operation *的wrapper,这就意味着,当我们定义一个Dialect的Operation的时候,我们实际上是在提供一个Operation类的接口。
(4)创建流程总结
MLIR在OpBase.td文件中提供了一些公共结构帮助我们定义特定的Op:


TableGen语法简单学习:

Traits在MLIR中用于指定对象的特殊property及约束:

四、TPU-MLIR前端转换

TPU-MLIR前端转换的工作流程为:

其中在初始化Converter部分和生成MLIR文本部分,

前端转换示例:



总结
首先关于传统编译器与AI编译器的区别,我觉得很直接,传统编译器主要是将我们使用的c++、java、python语言编译成机器可以理解的二进制码,而AI编译器主要是用于对模型进行加速。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









