






功利性得去找了下面试题库,发现一个讲面试题的教程,觉得讲得不错,教程地址
在这里总结一下学到的知识,打一下Java基础,算是挖一个新坑。
代码地址:源码地址
发现了个刷题的网站,题量大,有解析,暂未发现收费现象,社区氛围也不错,地址:网站地址
正在根据错题内容,逐渐重构完善本系列文章结构。
第三章 算法(二)
3. 数组相关
3.1 给出一个数组(可能包含负数),求 和最大的子序列
例:[1,-3,9,2,-3,5,-7,-1]
9+2+(-3)+5最大,子序列就是{9,2,-3,5}。
方法一:暴力穷举,三层循环,第一层遍历子序列的元素个数,第二层循环遍历子序列开始位置,第三层遍历子序列,求和。在第二层中把求和的结果与全局变量比较,更新最大的sum。
方法二:动态规划:初始数组:nums;定义一个sums数组,存储以i结尾的最大子序列的和,从0开始,sums[0]=nums[0],sums[1]的求法:判断sums[0]是否大于0,如果大于0则sums[1]=sums[0]+nums[1]……记录最大子序列起止角标的方法:以i结尾的子序列终止角标就是i,开始角标在sums数组生成的过程中一同产生,如果sums[i-1]是负数,则开始角标是i,如果sums[i-1]是正数或者0,则i的开始角标是i-1的开始角标。
3.2 数组去重排序
利用TreeSet,遍历一次原数组,把元素插入TreeSet中,自动去重排序,第二层遍历TreeSet,即可打印结果。
可以冒泡排序,双重循环
3.3 有序的数组去重排序
可以遍历数组,比较当前元素和后一个元素是否相等,如果不等则输出当前元素,最后输出最后一个元素。
可以利用HashSet的add方法返回值,遍历原数组,将数组元素add到新建的HashSet中,判断add返回值是否为true,如果为true则打印。
3.4 带下标的数组排序
定义一个数组存储下标,在冒泡排序的基础上,交换原数组元素的同时,交换下标数组元素。
@Test
public void test5(){
int[] nums = {1,3,5,2,2,1,4,6,8,8,7,9};
int[] index = new int[nums.length];
for (int i = 0; i < index.length; i++) {
index[i]=i+1;
}
for (int i = 0; i < nums.length; i++) {
for (int j = i+1;j<nums.length;j++){
if(nums[i]>nums[j]){
int temp = nums[i];
nums[i]=nums[j];
nums[j]=temp;
temp=index[i];
index[i] = index[j];
index[j]=temp;
}
}
}
for (int i = 0; i < nums.length; i++) {
System.out.println(nums[i]+"index:"+index[i]);
}
}
3.5 奇偶调换
输入一个整数数组,将该数组的奇数放在前面,偶数放在后面,并且奇数之间,偶数之间的相对位置不变。
方法1:新建两个ArrayList,遍历原数组,分别把奇数偶数存到上面创建的List中,然后list1.addAll(list2),list1.toArray得到结果。
4. 时间复杂度/空间复杂度
T(n) = aT(n/b)+cn^k; T(1) = c
if (a > b^k) T(n) = O(n^(logb(a))); logb(a):b为底a的对数
if (a = b^k) T(n) = O(n^k*logn);
if (a < b^k) T(n) = O(n^k);
第四章 数据库
1.SQL语句
1.1 内连接,左外连接,右外连接
内连接:当on后面内容符合时,两个表里的记录会被叠加在一起。
use test;
select a.id,a.name,b.rid ,c.namezh
from `user` a
inner join admin_user_role b on a.id =b.uid
inner join admin_role c on c.id =b.rid
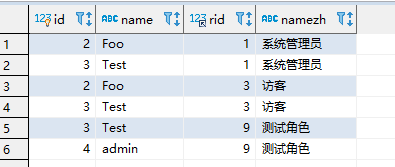
左外连接:from后面那个表所有记录都会显示,left join后面那个表只有符合on后面规则时才会叠加到后面,如果没有符合规范则用null叠在后面。
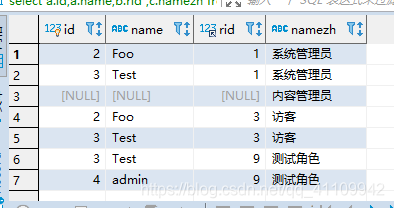
右外连接:同左外连接。
use test;
select a.id,a.name,b.rid ,c.namezh
from `user` a
right join admin_user_role b on a.id =b.uid
right join admin_role c on b.rid =c.id
1.2 查询语句(select)
1.2.1 模糊查询
use test;
select *
from book
where author like '倪%'
use test;
select count(*)
from book
where author like '倪%'
1.2.2 求平均
select avg(b.score),a.name
from student a
inner join score b on a.id = b.sid
group by a.id
select sid,avg(score)
from score
group by sid
having avg(score)>60
where是直接能查到的数据,限制条件。
having是计算出来的数据,限制条件。
1.2.3 求和
查询所有同学的学号,姓名,选课树,总成绩:
select st.id,st.name,count(sc.kid),sum(sc.score)
from st
left join sc on st.id = sc.sid
group by st.id
查询总成绩大于300的学生
select st.id,st.name,count(sc.kid),sum(sc.score)
from st
left join sc on st.id = sc.sid
group by st.id
having sum(sc.score)>300
1.2.4 没有XX的
没有选叶平的课的:
首先选了叶平课的:把选课表,教师表,课程表连起来。选出学生id
select course_select.sid
from course_select
inner join course on course.id = course_select.cid
inner join teacher on teacher.id = course_select.tid
where teacher.name = '叶平'
接着将上述语句作为集合,可以where id not in ()作为判断条件,查询出学生信息。
1.2.5 满足XX条件的记录数多于2个的
count(*),count(1),count(主键)在没有where的情况下返回结果都是表内的记录数。
例:列出有两门以上不及格课程的学生的姓名及平均成绩。
首先查询满足条件的学生id
select sid
from student_score
where score<60
group by sid
having count(*)>=2
select avg(student_score.score),student.name
from student_score
inner join student on student_score.sid=student.id
where student_score.sid in(
select sid
from student_score
where score<60
group by sid
having count(*)>=2
)
group by student_score.sid
select course.*
from student_score
inner join course on course.id = student_score.cid
where score < 60
group by cid
having count(*)>2
1.2.6 查询数值最高的相关信息(分组)
每科成绩最高的学生,课程,成绩信息
select student.id,student.name,course.id,course.name,student_score.score
from student_score
inner join course on student_score.cid = course.id
inner join student on student_score.sid = student.id
inner join (
select max(score),cid
from student_score
group by cid
)t on student_score.cid = t.cid and student_score.score=t.score
1.2.7 同一张表关联查询
查询学生信息满足条件:该学生课程1的成绩比课程2成绩高。
select sl.sid
from student_score s1
inner join student_score s2 on s1.sid = s2.sid
where si.cid = 1 and s2.cid = 2 and s1.score>s2.score
1.2.8 查询数值最高的相关信息(不分组)
查询选修“叶平”老师课程的成绩最高的学生:
在成绩表把cid为叶平老师上的课程id记录全查出来(关联了成绩表,课程表,教师表),顺便关联学生表这样就可以看到学生的详细信息。用score降序排列,取第一个就是最高的分数。
select student.id,student.name,course.id,course.name,student_score.score
from student_score
inner join course on course.id=student_score.cid
inner join student on student.id = student_score.sid
inner join teacher on teacher.id = course.tid
where teacher.name='叶平'
group by score desc
limit 1
1.2.9 反向思维
查出每门课成绩都大于80的学生姓名:
查出每个学生的最低成绩,再取最低成绩大于80的学生信息:
select min(score),student.name
from student_score
inner join student on student.id = student_score.sid
group by sid
having min(score)>80
1.3 更新语句(update)
1.3.1 两表联合修改
update cardapply a,cardapply_detail b
set a.state='07',b.state='07'
where a.id = '123' and a.id = b.cid
1.4 删除语句(delete)
1.4.1 模糊删除
delete from cardapply_detail where name like '李%'
1.5 行转列
原表:
姓名|科目|成绩
张三|语文|90
张三|数学|80
目标表:
姓名|语文|数学
张三| 90 | 80
select '姓名',
min(case when '科目'='语文' then '成绩' end) '语文',
min(case when '科目'='数学' then '成绩' end) '数学'
from score
group by '姓名'
min(case when '科目'='语文' then '成绩' end)表示当科目对应的值为语文时,查出对应的成绩。
2. 数据库三级模式结构
内模式又称为存储模式,对应于物理级。三级模式结构包括外模式,内模式,模式。
①模式(schema):
模式也称逻辑模式,是数据库中全体数据的逻辑结构和特征的描述,是所有用户的公共数据视图。
②外模式(external schema):
外模式也称子模式(subschema)或用户模式,它是数据库用固话(包括应用程序员和最终用户)能够看见和使用的局部数据的逻辑结构和特征的描述,是数据库用户的数据视图,是与某一应用有关的数据的逻辑表示。
③内模式(internal schema):
内模式也称存储模式(storage schema),一个数据库只有一个内模式。它是数据物理存储和存储方式的描述,是数据在数据库内部的组织方式。
3. Mybatis
3.1 $和#
#{ }:解析为一个JDBC预编译语句(prepared statement)的参数标记符。(预编译效率高,占位符被替换时会自动加上引号)
一个#{ }被解析为一个参数占位符 ‘?’
例:select * from user where name = #{name} =>
select * from user where name = ?
${ }:直接替换成值
例:select * from user where name = ${name} =>
select * from user where name = Jack
能使用#{ }的地方就用#{ },相同的预编译sql可以重复利用,能避免SQL注入。表名(由于#{ }自动加了引号,而表名只能加``所以不能用#{ })、字段名需要动态替换的时候用${ },其他情况不用 ${ },可能会被SQL注入。
3.2 Mybatis缓存
一级缓存:同一个SqlSession对象,在参数和SQL完全一样的情况下,只执行一次SQL语句,默认开启,不能关闭。
二级缓存:二级缓存在SqlSessionFactory生命周期中,需要手动开启。
缓存场景:查询频率很高,更新频率很低时使用。
4. 数据库连接池
4.1 加载JDBC驱动方法
1.Class.forName(“com.microsoft.sqlserver.jdbc.SQLServerDriver”);
2. DriverManager.registerDriver(new com.mysql.jdbc.Driver());
3.System.setProperty(“jdbc.drivers”, “com.mysql.jdbc.Driver”);
4.2 工作机制
服务器启动时会建立一定数量的池连接,并一直维持不少于此数目的池连接。
客户端程序需要连接时,池驱动程序会返回一个未使用的池连接并将其标记为忙。
如果当前没有空闲连接,池驱动程序就新建一定数量的连接,新建连接的数量由配置参数决定。
当使用的池连接调用完成后,池驱动程序将此连接表标记为空闲,其他调用就可以使用这个连接。
5. 脏读、不可重复读、幻读
脏读:读了没有提交的数据。
不可重复读:前后两次读数据,发现数据被人改过了。
幻读:数据的记录个数变动了。
事务隔离等级:Read uncommitted、Read committed 、Repeatable read、Serializable四种隔离级别并行性能依次降低,安全性依次提高。
后三个等级逐步解决上面的三个问题。
RR和RC隔离级别都存在幻读,RR隔离级别幻读可以通过next-key lock避免。
RR隔离级别下,有读锁但没有范围锁,其他事物无法修改在读的,但可以增加数据,也就是说RR级别下可以返回插入值
6. 关系数据库/非关系数据库(NoSQL)
关系型数据库:是指采用了关系模型来组织数据的数据库,关系模型指的就是二维表格模型。
常见的关系型数据库:Oracle,SQL Server,Sybase,DB2,Access,MySql,VFP,INGRES
非关系型数据库,以键值对进行存储,常见的非关系型数据库(NoSQL):SQLite, Redis ,MongoDB ,Cassandra , Voldemort, CouchDB, LevelDB
6.1 Redis
redis一共包含5种数据类型
①字符串 String (最基本的类型,可包含任意数据)
②哈希 Hash (String类型的field、value映射表)
③列表 List (字符串列表,有序不唯一)
④集合 set (字符串集合,无序唯一)
⑤集合排序 zset (字符串集合,可以通过设置分数score进行排序)
Redis主要消耗内存资源
Redis集群之间是异步复制的
分区可以让Redis管理更大的内存
Redis Cluster在设计中没有使用一致性哈希(Consistency Hashing),而是使用数据分片引入哈希槽(hash slot)来实现














 317
317











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









