







- c和c++更适合 编程语言,就连java底层都是c++来写的
- 脚本语言是需要用到变量和函数来完成程序的
- 中间代码通常使用符号表来表示的,而 中间代码只是类似 三地址码,并且中间代码和具体的机器无关
- 语法分析的目的是分析数据类型是否合法
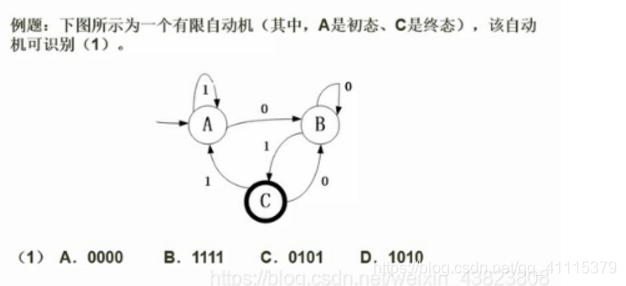
- 有限自动机:
好像就是可以按照四个选项的表达式一步一步推
由于A是初态,C是终态,我们代入验证四个选项中哪一个可以由初态走到终态,即为正确答案。
A选项:0000,从A开始,由0到达B;再由0,仍然到达B(因为在B这里,0只能是以自身循环),所以0000无法识别。
B选项:1111,从A开始,由1到达A;再由1,仍然到达A(因为在A这里,1只能是以自身循环),所以1111无法识别。
C选项:0101,从A开始,由0到达B;再由1,到达C;再由0,到达B;最后由1,到达终态C,所以0101可以识别。
D选项:1010,从A开始,由1到达A;再由0,到达B;再由1,到达C;最后由0,到达B,所以1010无法识别。
6. 命名对象包括 变量,函数和数据类型
7. 正规式表示:
- 词法分析:对单词字符进行扫描,识别出一个个单词符号,比如 关键字,标识符等等 语法分析:在词法分析基础上,将单词符号序列分解成各类语法单位,比如表达式 ,识别判断程序语句 语义分析:语法结构的含义 代码生成:就是生成代码
- 引用
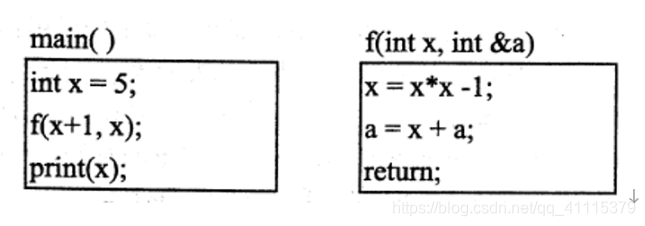
只有a的变换才会导致main函数里的变换,因为x就是把数值传递过去了,而a的话就是引用传递,吧本身传递过去了
x=xx-1 (5+1)(5+1)-1=35 a就是x 35+5=40
- 表达式的后缀表达式:
后缀就是左右根 ,所以看图就行了 - 字符串的长度是指 串中所含字符的个数
- 对于传值和传引用这两种,传值调用是被调用的函数内部对形参的修改不影响实参的值,引用调用是将实参的地址传递给形参的,所以修改形参就是修改了实参的值
文法类型:程序设计语言的语法基本上都是 上下文无关文法- 编译过程: 语法错误:非法字符,关键字或标识符拼写错误。词法错误 :语法结构出错,if endif不匹配 语义错误:死循环,零除数
- 编译方式和解释方式:编译就相当于是全文翻译,他不一定有 中间代码生成和代码优化,解释就相当于是同声翻译,所以他们的区别:1.解释程序是参与到用户程序的运行控制中,并且程序执行速度慢 2.解释程序不会产生目标程序(因为他已经直接参与进去了 不需要再产生目标了)
- 脚本语言:此命名起源于一个脚本“screenplay”,每次运行都会使对话框逐字重复。早期的脚本语言经常被称为批处理语言或工作控制语言。一个脚本通常是解释运行而非编译。
- 中间代码的表示形式 有 语法树,后缀式,三地址代码,还有四元式
- 全局变量,静态局部变量,静态全局变量全都存放在 静态数据存储区
- 递归下降分析方法是一种 自上而下的语法分析
- 中间代码:1.不依赖具体的机器 2.可以提高编译程序的可移植性 3.中间代码可以用树或者图来表示 最大的优点就是可以进行与机器无关的优化处理
- 编译过程中,对高级语言程序语名的翻译主要考虑声明语名和可执行语句。对声明语句,主要是将所需要的信息正确地填入合理组织的( 符号表 )中;对可执行语句,则是( 翻译成中间代码或者目标代码 )。
- C中如果引用了未赋初值的变量,是可以通过编译运行的,但是运行结果不一定是期望的结果
- 目标代码生成阶段的工作和目标机器的体系结构密切相关
- 面向机器的程序设计语言,使用汇编语言编写的程序,机器不能直接识别,要由一种程序将汇编语言翻译成机器语言,这种起翻译作用的程序叫汇编程序。汇编程序输入的是用汇编语言书写的源程序,输出的是用机器语言表示的目标程序。














 2489
2489











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









