






 本文介绍了如何使用Python的xmind-sdk-python3库和Selenium爬虫工具,将网页数据抓取并绘制为思维导图。首先,通过pip安装xmind库,然后使用xmind创建或加载工作簿,设置工作表和根节点,创建分支节点。接着,利用Selenium爬取指定网页上的食物分类和种类信息。最后,遍历爬取的数据,生成对应的思维导图节点结构,并保存到xmind文件中。通过这种方式,实现了从数据抓取到思维导图绘制的自动化过程。
本文介绍了如何使用Python的xmind-sdk-python3库和Selenium爬虫工具,将网页数据抓取并绘制为思维导图。首先,通过pip安装xmind库,然后使用xmind创建或加载工作簿,设置工作表和根节点,创建分支节点。接着,利用Selenium爬取指定网页上的食物分类和种类信息。最后,遍历爬取的数据,生成对应的思维导图节点结构,并保存到xmind文件中。通过这种方式,实现了从数据抓取到思维导图绘制的自动化过程。
最近在整理测试用例的时候发现用例目前只存放在 Jira 网页上,为了方便就想到将数据导出到思维导图上,然后一不下心就实现啦 (* ̄︶ ̄)~
文章目录
1. install xmind
clone https://github.com/git-jhy/xmind-sdk-python3 到本地
在目录 xmind-sdk-python3-master 中使用命令安装 xmind 库:
python setup.py install
接着安装一个 XMind8,接下来就可以愉快的绘制思维导图啦 ~
2. XMind 库的使用
2.1 创建/打开 xmind 文件
- 通过 xmind.load() 创建或加载 workbook
- 通过 getPrimarySheet 获取当前工作表
- 通过 getRootTopic 定位思维导图的根节点
- 通过 setTitle 设置标题
import xmind
# load or create a new workbook
w = xmind.load("test.xmind")
s1 = w.getPrimarySheet() # get the first sheet
s1.setTitle("first sheet") # set its title
r1 = s1.getRootTopic() # get the root topic of this sheet
r1.setTitle("root node") # set its title
# create a new sheet
s2 = w.createSheet()
s2.setTitle("second sheet")
r2 = s2.getRootTopic()
r2.setTitle("root node")
2.2 创建分支节点
通过 addSubTopic 和 setTitle创建子分支:
t1 = r1.addSubTopic()
t1.setTitle("title")
其他 xmind 功能可以参考 clone 下来的目录中的 example.py 和 xmind 库源代码进行设置!
3. selenium + xmind
接下来尝试将网页中的数据爬取下来,绘制思维导图。
selenium 的使用可以参考 这篇文章 哦
3.1 selenium 爬取数据
以这个 页面 为例
首先,爬取数据并存储下来:
import time
from selenium import webdriver
driver = webdriver.Chrome()
driver.get('https://git-jhy.github.io/snake')
foods = {}
for i in range(1, 3):
categories = driver.find_elements_by_xpath('//body/div['+str(i)+']')
for category in categories:
categorie_name = category.find_element_by_css_selector('strong').text
foods[categorie_name] = []
items = category.find_elements_by_css_selector('li')
for item in items:
foods[categorie_name].append(item.text)
print(foods)
结果如下:
{
'Fruits': ['apple', 'banana', 'cherry', 'Durian'],
'Vegetable': ['cabbage', 'been', 'tomato']
}
3.2 生成 xmind
通过深度优先,遍历数据,创建思维导图:
import xmind
workbook = xmind.load('food.xmind')
sheet = workbook.getPrimarySheet()
sheet.setTitle("food")
# root node
root = sheet.getRootTopic()
root.setTitle("Food")
for key1, val1 in foods.items():
node1 = root.addSubTopic()
node1.setTitle(key1)
for elem in val1:
node2 = node1.addSubTopic()
node2.setTitle(elem)
xmind.save(workbook)
driver.close()
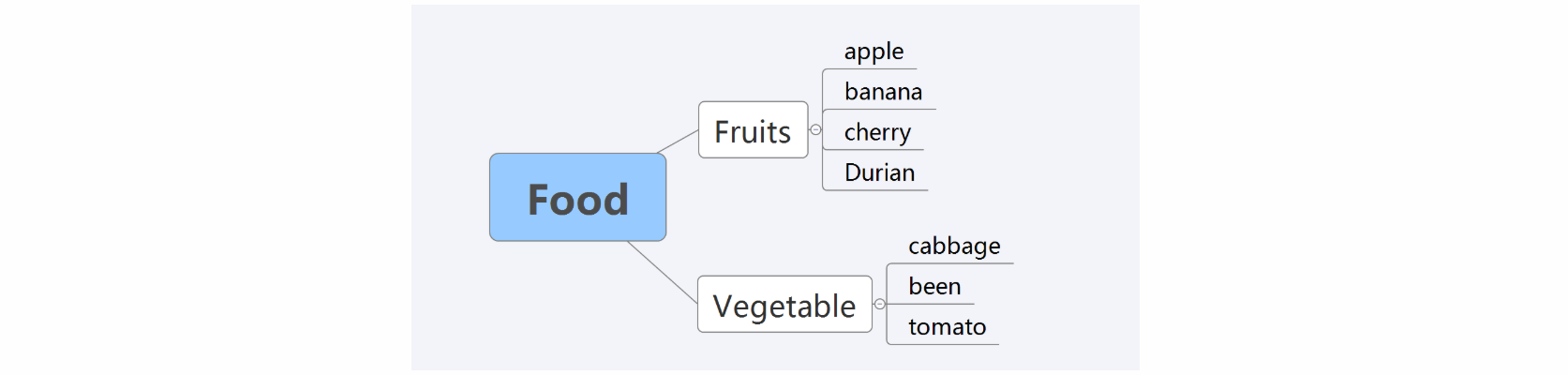
大功告成 ~
REFERENCE:
END

















 689
689

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









