






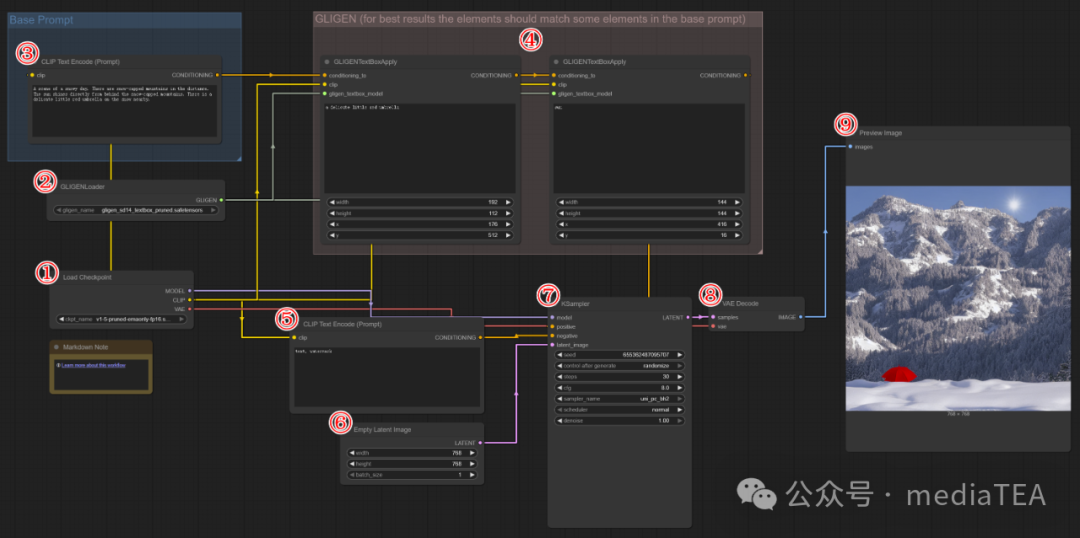
GLIGEN(Grounded Language-to-Image Generation)工作流是一种基于文本 + 空间信息的图像生成流程。
它允许你用基础提示词描述整张画面的整体语义,同时使用 GLIGENTextBoxApply 节点,通过文字 + 坐标精确控制某个物体出现在画面的什么位置和尺寸,最后整体生成图像,指定的物体将“定点”融合入场景之中。
这能更有目的地引导图像结构布局,在复杂构图、广告图、产品图、设计草图等场景中极具价值。
Checkpoint 加载器(简易)
Load Checkpoint 节点用于加载一个基础模型(如 SD1.5 的 pruned 版本),内部一般都包含三个核心组件:
MODEL:图像生成模型CLIP:用于解析文字提示的语言编码器VAE:用于潜空间图像与可视图像之间的转换基础模型负责大部分图像风格与生图能力。
② GLIGENLoader
GLIGEN 加载器
GLIGENLoader 节点用于加载 GLIGEN 专用模型,用于处理“指定位置”生成任务。
比如:
gligen_sd14_textbox_pruned.safetensors要注意的是,GLIGEN 模型必须与基础模型兼容,通常使用 SD1.4 或 SD1.5。
CLIP 文本编码
正向(Positive)提示词的 CLIP Text Encode 节点用于提供整体画面的描述,作为 Base Prompt(基础提示词)。
比如:
A scene of a snowy day. There are snow-capped mountains in the distance. The sun shines directly from behind the snow-capped mountains. There is a delicate little red umbrella on the snow.这段文字设定整个图像场景的主题、环境、风格,是全图的“语义基础”。
④ GLIGENTextBoxApply
GLIGEN 文本框应用
GLIGENTextBoxApply 节点用于将文本所描述的对象与具体空间位置绑定。
可以串联多个 GLIGENTextBoxApply 节点,每个节点控制一个元素的生成位置,它们都会基于基础提示词和 GLIGEN 模型进行“定向增强”。
文本框中输入的对象提示词,应该是基础提示词中所描述的对象之一。
CLIP 文本编码
反向(Negative)提示词的 CLIP Text Encode 节点用于输入一些不希望在图像中出现的内容。
比如:
text, watermark其作用是让模型尽量避免生成文字、水印或其它不需要的元素。
空 Latent 图像
Empty Latent Image 节点生成一个空的潜空间图像。
它并不直接可见,但为后续的采样器提供了一个指定尺寸的画布。
⑦ KSampler
K 采样器
KSampler 节点用于执行扩散生成过程,融合基础提示、位置控制与负面提示进行图像采样。
加载的模型(MODEL)正向提示(positive conditioning)反向提示(negative conditioning)潜空间图像(latent image)模型在这个阶段根据提示词在噪声图中“逐步绘图”,生成潜空间图像,为后续图像解码做准备。
VAE 解码
VAE Decode 节点通过 VAE 将其解码为 RGB 图像格式,使图像内容可以被视觉识别与保存。
⑨ Save Image / Preview Image
保存图像 / 预览图像
使用 Preview Image 或 Save Image 节点来查看或保存最终输出结果。
在结果图中,可看到生成的图像,符合基础提示词中的描述,并在指定的位置生成相应的图像元素。

“点赞行美意,赞赏是鼓励”

















 1186
1186

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









