






让我们设计一个类似于Pastebin的web服务,用户可以在其中存储纯文本。使用这个服务的用户将输入一段文本,并获得一个随机生成的URL来访问它。类似服务:pastebin.com,pasted.co,hplapp.com
1.Pastebin是什么?
类似Pastebin的服务使用户能够通过网络(通常是Internet)存储纯文本或图像,并生成唯一的URL来访问上传的数据。这些服务也被用来快速地在网络上共享数据,因为用户只需传递URL就可以让其他用户看到它。如果您以前没有使用pastebin.com,请尝试在那里创建一个新的“粘贴”,并花一些时间浏览他们的服务提供的不同选项。这将对你理解这一章有很大帮助。
2.系统的要求和目标
我们的Pastebin服务应该满足以下要求:
功能需求:
1.用户应该能够上传或“粘贴”他们的数据,并获得一个唯一的URL来访问数据。
2.用户只能上传文本。
3.数据和链接将在特定的时间段后自动过期;用户还应该能够指定过期时间。
4.用户应该可以随意地为他们的粘贴选择一个自定义别名。
非功能性需求:
1.系统应高可靠,上传的任何数据不应丢失。
2.系统应高可用。这是必需的,因为如果我们的服务关闭,用户将无法访问他们的粘贴。
3.用户应该能够以最小的延迟实时访问他们的粘贴。
4.粘贴链接不应是可猜测的(不可预测的)。
拓展要求:
1.分析,例如,一个粘贴被访问了多少次?
2.我们的服务也应该可以通过REST API被其他服务访问。
3.一些设计考虑
Pastebin与URL缩短服务有一些相同的要求,但是我们还需要记住一些额外的设计注意事项。
用户一次可以粘贴的文本数量的限制应该是多少?
我们可以限制用户的粘贴不超过10 MB,以阻止滥用服务。
我们是否应该对自定义URL施加大小限制?
由于我们的服务支持自定义URL,用户可以选择他们喜欢的任何URL,但是提供自定义URL并不是强制性的。但是,对自定义URL施加大小限制是合理的(而且通常是可取的),以保证我们有一个一致的URL数据库。
4.容量估计和约束
我们的服务将是大量读取的;与paste的创建相比,将会有更多的读取。我们可以假设读写之间的比例为5:1。
流量估计:
Pastebin服务的流量预计不会与Twitter或Facebook类似,假设我们每天都有100万新的paste添加到我们的系统中。这使我们每天有五百万的读请求。
每秒产生的新paste数量:1M/(24小时*3600秒)~=12/秒
每秒读取的paste数量:5M/(24小时*3600秒)~=58/秒
存储估计:
用户最多可以上传10 MB的数据;通常类似Pastebin的服务用于共享源代码、配置或日志,这样的文本并不大,所以让我们假设每个paste平均包含10 KB。按照这个速率,我们将每天存储10 GB的数据。
1M*10 kb=>10 GB/日
如果我们想将这些数据存储十年,我们将需要36TB的总存储容量。
如果每天有100万paste,我们在10年内就会有36亿个paste。我们需要生成和存储密钥,以唯一地识别这些粘贴。如果我们使用base 64编码([A-Z,a-z,0-9,.,-]),我们需要6个字符串:
64^6~=687亿唯一字符串
如果存储一个字符需要一个字节,则存储3.6B键所需的总大小为:
3.6b*6=>22 GB
与36 TB相比,22 GB是可以忽略不计的。为了保持一定的空间,我们将假设一个70%的容量模型(意味着我们不想在任何时候使用超过70%的总存储容量),这将使我们的存储需求增加到51.4TB。
带宽估计:
对于写请求,我们期望每秒有12个新的paste,从而每秒产生120 kb的入口。
12*10 kb=>120 KB/s
至于读取请求,我们预计每秒有58个请求。因此,总数据出口(发送给用户)将为0.6MB/s。
58*10 kb=>0.6 MB/s
虽然总出入口不是很大,但是在设计我们的服务时,我们应该记住这些数字。
内存估计:
我们可以缓存一些经常被访问的热门paste。按照80-20规则,即20%的热paste产生80%的流量,我们希望缓存这20%的paste。既然我们每天有500万次阅读请求,要缓存其中20%的请求,我们就需要:
0.2*5m*10 kb~=10 GB
5.系统API
我们可以使用SOAP或REST API来公开服务的功能。以下是创建/检索/删除paste的API的定义:
addPaste(api_dev_key, paste_data, custom_url=None user_name=None, paste_name=None, expire_date=None)
参数:
api_dev_key(string):一个注册帐户的API Developer key。除其他外,这将用于根据用户被分配到的配额来对用户限流。
paste_data(string):paste的文本数据
custom_url(string):可选的自定URL
user_name(string):用于生成URL的可选用户名
paste_name(string):可选的paste名称
expire_date(string):可选的paste过期日期
返回:(string)
成功的插入返回可以访问paste的URL,否则它将返回一个错误代码。
同样地,我们可以得到检索和删除paste的API:
getPaste(api_dev_key, api_paste_key)
其中,“api_dev_key”是一个字符串,表示要检索的paste键。此API将返回paste的文本数据。
deletePaste(api_dev_key, api_paste_key)
成功的删除返回“true”,否则返回“false”。
6.数据库设计
关于我们正在存储的数据的性质的一些观察:
1.我们需要储存数十亿份记录。
2.我们存储的每个元数据对象都很小(小于100个字节)。
3.我们存储的每个paste对象都可以是中等大小的(可以是几MB)。
4.记录之间没有任何关系,除非我们想存储哪个用户创建了什么paste。
5.我们的服务读取量很大.
数据库模式:我们需要两个表,一个用于存储有关粘贴的信息,另一个用于存储用户的数据。
Paste表:
URLHash:PK varchar(16)
ContentKey: varchar(512)
ExpirationDate: datatime
CreationDate:datetime
用户表
UserID: PK int
Name: varchar(20)
Email: varchar(32)
CreationDate:datetime
在这里,‘URlHash’是TinyURL的URL等效,‘ContentKey’是存储paste内容的对象键。
7.高层设计
在较高的层次上,我们需要一个应用程序层来服务所有的读写请求。应用层将与存储层对话以存储和检索数据。我们可以使用一个数据库隔离存储层,其中一个数据库存储与每个paste、用户等相关的元数据,而另一个数据库则将paste内容存储在某些对象存储中(如AmazonS 3)。这种数据划分也将使我们能够单独地扩大数据规模。
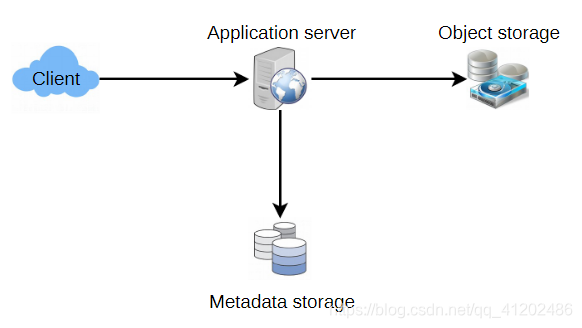
8.构件设计
A.应用层
我们的应用层将处理所有传入和传出请求。应用服务器将与后端数据存储组件进行通信,以满足请求。
如何处理写入请求?
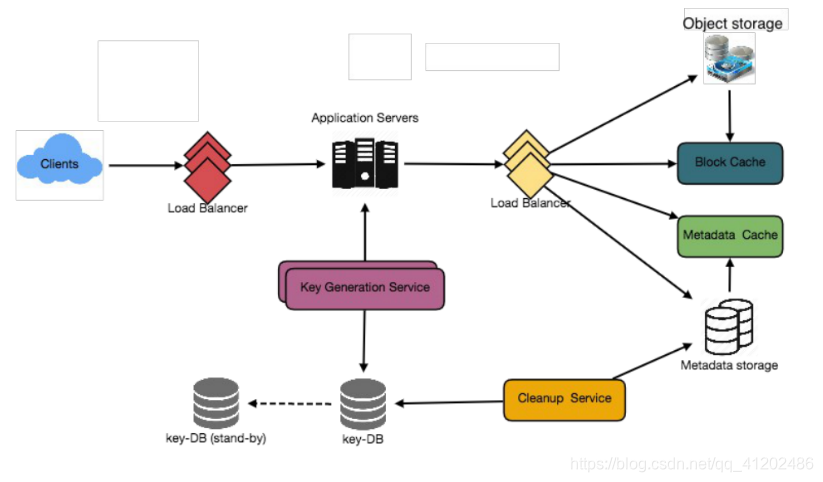
在接收到写请求后,我们的应用服务器将生成一个6个字母的随机字符串,作为paste的key(如果用户没有提供自定义key)。然后,应用服务器将在数据库中存储paste的内容和生成的key。成功插入后,服务器可以将key返回给用户。这里可能存在的一个问题是插入失败是因为键重复。由于我们正在生成一个随机key,所以新生成的key可能与现有key重复。在这种情况下,我们应该重新生成一个新的键,然后再试一次。我们应该继续重试,直到我们没有看到由于重复导致的键失败。如果用户提供的自定义key已经存在于我们的数据库中,我们应该向用户返回一个错误。
解决上述问题的另一个解决方案是运行一个独立key生成服务(KGS),该服务预先生成随机的6个字母字符串,并将它们存储在数据库中(让我们称之为key-DB)。当我们想要存储一个新的paste时,我们只需要使用一个已经生成的键就可以了。这种方法将使事情变得非常简单和快速,因为我们不会担心重复或碰撞。KGS将确保键DB中插入的所有键都是唯一的。KGS可以使用两个表来存储密钥,一个用于尚未使用的键,另一个用于所有已使用的键。一旦KGS给出了应用服务器的一些key,它就可以将这些键移动到已使用的键表中。KGS总是可以在内存中保存一些密钥,这样每当服务器需要它们时,它都可以快速地提供它们。一旦KGS在内存中加载了一些键,它就可以将它们移动到已使用的键表中,这样我们就可以确保每个服务器都得到唯一的键。如果KGS在使用内存中加载的所有key之前就挂了,我们将浪费这些key。我们可以忽略这些key,因为我们有大量的key。
KGS不是一个单点故障吗?
是的。为了解决这个问题,我们可以有一个KGS的备用副本,每当主服务器挂掉后,它就可以负责生成和提供key,每个应用服务器可以从key-DB缓存一些key吗?是的,这肯定能加快速度。尽管在这种情况下,如果应用程序服务器在使用所有key之前就挂了,我们最终会丢失这些键。这是可以接受的,因为我们有68B个唯一的6个字母键,这比我们需要的要多得多。它如何处理paste读取请求?在接收到读取paste请求时,应用程序服务层与数据存储进行联系,数据存储搜索key,如果找到,则返回paste的内容。否则,将返回错误代码。
B.数据存储层
我们可以将数据存储层分为两层:
1.元数据数据库:我们可以使用关系数据库,如mysql或像Dynamo或Cassandra这样的分布式键值存储。
2.对象存储:我们可以将内容存储在像Amazon S3那样的对象存储中。每当我们想在内容存储上充分发挥我们的能力时,我们可以通过增加更多的服务器来轻松地增加它。
9.清除或清除数据库请参见设计URL缩短服务。
10.数据分区和复制请参见设计URL缩短服务。
11.缓存和加载均衡器请参见设计URL缩短服务。
12.安全和权限请参见设计URL缩短服务。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









