






目录
是什么
可以查看查询语句的执行计划,是查询性能优化的重要工具。
如何使用
explain select * from staffs where name='z3'and age=22 and pos='manager';从explain语句能获取哪些信息
- sql语句的执行顺序
- 数据读取操作的操作类型
- 哪些索引可能被使用到
- 哪些索引被实际使用
- 索引的哪些列被使用到
- 表之间的引用
- 每张表有多少行优化器查询
怎么分析(各个字段的含义)
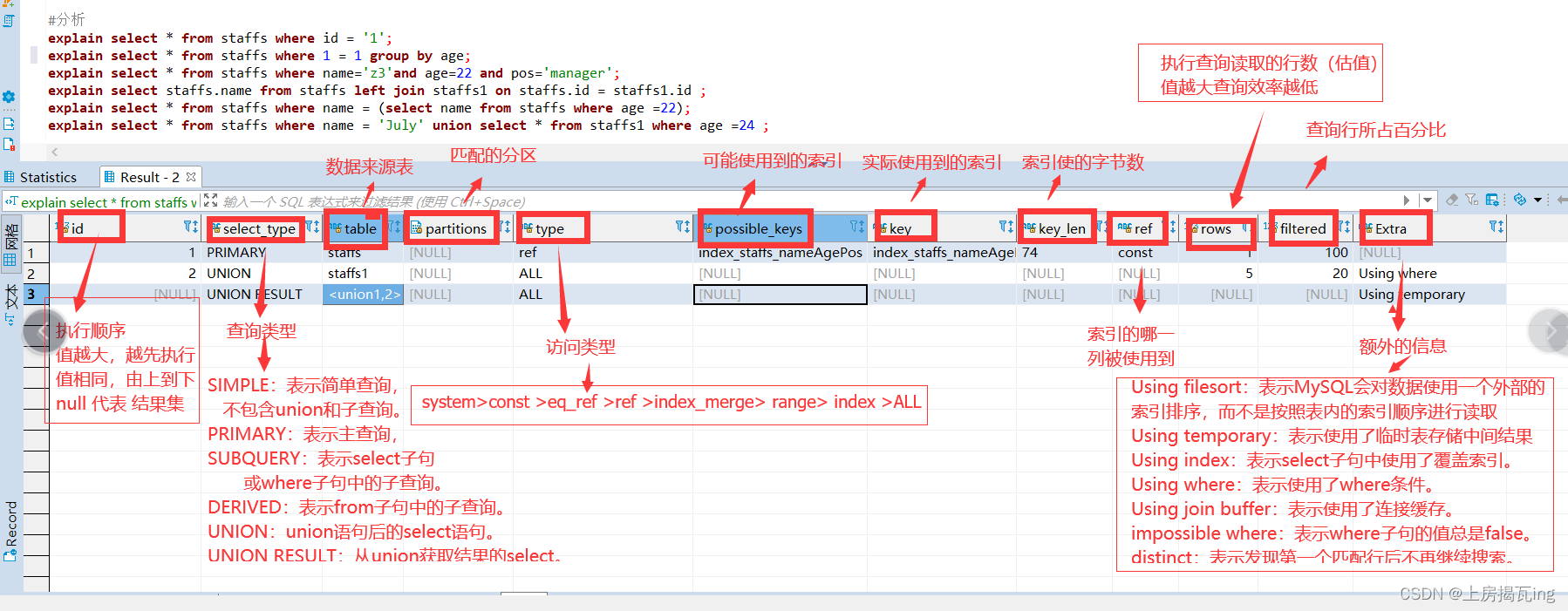
(1)id:执行顺序
id代表SQL语句的执行顺序。
id越大,优先级越高,越先被执行。
id相同,执行顺序由上至下。
id列为null:表示这是一个结果集,不需要使用它来进行查询。
(2)select_type:查询类型
- SIMPLE:表示简单查询,不包含union和子查询。
- PRIMARY:表示主查询,查询语句中如果包含子查询,其最外层查询为主查询。
- SUBQUERY:表示select子句或where子句中的子查询。
- DERIVED:表示from子句中的子查询。
- UNION:union语句后的select语句被标记为UNION。
- UNION RESULT:从union获取结果的select。
(3)table:数据来源表
(4)partitions:匹配的分区
(5)type:访问类型
可用于判断查询是否高效,由优到劣。
system>const >eq_ref >ref >index_merge> range> index >ALL
system:表只有一行记录,const类型的特例
const: 针对主键或唯一索引的等值查询扫描,表示通过索引一次就找到了,最多只返回一行数据
eq_ref :表示联表查询时,按联表的主键或唯一键联合查询
ref: 此类型通常出现在多表的 join 查询,针对于非唯一或非主键索引
range: 表示使用索引范围查询
index: 表示全索引扫描(full index scan),和 ALL 类型类似,只不过 ALL 类型是全表扫描,而 index 类型则仅仅扫描所有的索引, 而不扫描数据
ALL: 表示全表扫描
(6)possible_keys
mysql 在查询时,可能使用到的索引。
(7)key
查询实际使用的哪个索引
(8)key_len
索引使用的字节数。
(9)ref
显示索引的哪一列被使用。
(10)rows
执行查询读取的行数,数值越大表示查询效率越差。(估算值)
(11)filtered
查询的表行占表的百分比
(12)Extra
额外的信息,不适合在其它列显示但十分重要的信息
Using filesort:表示MySQL会对数据使用一个外部的索引排序,而不是按照表内的索引顺序进行读取,MySQL中无法利用索引完成的排序操作称为“文件排序”。
Using temporary:表示使用了临时表存储中间结果,常见于order by和group by子句。
Using index:表示select子句中使用了覆盖索引。
Using where:表示使用了where条件。
Using join buffer:表示使用了连接缓存。
impossible where:表示where子句的值总是false。
distinct:表示发现第一个匹配行后不再继续搜索。
使用实例
可以在数据库中玩一下

示例sql --包括建表语句
CREATE TABLE staffs(
id INT PRIMARY KEY AUTO_INCREMENT,
`name` VARCHAR(24) NOT NULL DEFAULT'' COMMENT'姓名',
`age` INT NOT NULL DEFAULT 0 COMMENT'年龄',
`pos` VARCHAR(20) NOT NULL DEFAULT'' COMMENT'职位',
`add_time` TIMESTAMP NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT'入职时间'
)CHARSET utf8 COMMENT'员工记录表';
#新增数据
INSERT INTO staffs(`name`,`age`,`pos`,`add_time`) VALUES('z3',22,'manager',NOW());
INSERT INTO staffs(`name`,`age`,`pos`,`add_time`) VALUES('July',23,'dev',NOW());
INSERT INTO staffs(`name`,`age`,`pos`,`add_time`) VALUES('2000',23,'dev',NOW());
#联合索引
ALTER TABLE staffs ADD INDEX index_staffs_nameAgePos(name,age,pos);
CREATE TABLE staffs1(
id INT PRIMARY KEY AUTO_INCREMENT,
`name` VARCHAR(24) NOT NULL DEFAULT'' COMMENT'姓名',
`age` INT NOT NULL DEFAULT 0 COMMENT'年龄',
`pos` VARCHAR(20) NOT NULL DEFAULT'' COMMENT'职位',
`add_time` TIMESTAMP NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT'入职时间'
)CHARSET utf8 COMMENT'员工记录表1';
#新增数据
INSERT INTO staffs1(`name`,`age`,`pos`,`add_time`) VALUES('z3',22,'manager',NOW());
INSERT INTO staffs1(`name`,`age`,`pos`,`add_time`) VALUES('July',23,'dev',NOW());
INSERT INTO staffs1(`name`,`age`,`pos`,`add_time`) VALUES('2000',23,'dev',NOW());
INSERT INTO staffs1(`name`,`age`,`pos`,`add_time`) VALUES('hua',24,'ddd',NOW());
#联合索引
ALTER TABLE staffs1 ADD INDEX index_staffs_nameAgePos(name,age,pos);
#分析
explain select * from staffs where id = '1';
explain select * from staffs where 1 = 1 group by age;
explain select * from staffs where name='z3'and age=22 and pos='manager';
explain select staffs.name from staffs left join staffs1 on staffs.id = staffs1.id ;
explain select * from staffs where name = (select name from staffs where age =22);
explain select * from staffs where name = 'July' union select * from staffs1 where age =24 ;参考博文:















 6284
6284











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









