







集合之List和Set

集合之Map
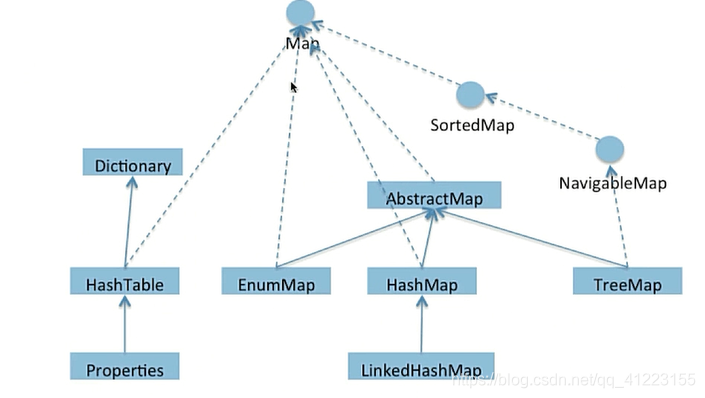
HashMap
hashmap是非线程安全的,所以效率比较高.
Java8之前,hashmap底层是通过数组+链表实现的,如图所示:
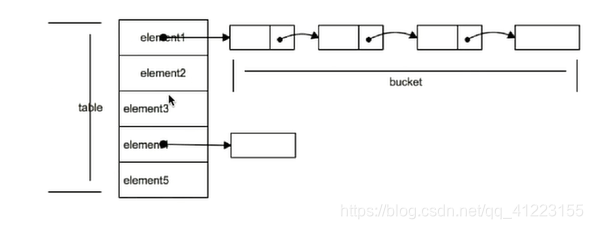
hashmap没有赋值之前,数组长度默认为16,在该数组中每个位置存储的都是链表的头结点.
通过hash(key.hashCode()) % len这个函数来获得要添加的元素在数组中的存放位置.
这样子就会有一个问题,有可能大多数元素经过哈希之后都跑到了同一个位置,这就导致链表很长,查询时间从O(1) ->O(n).
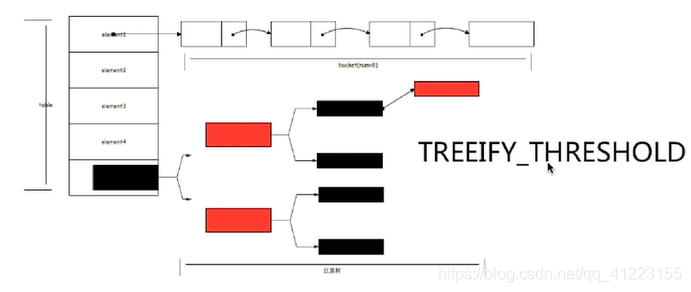
所以,Java8及以后,hashmap底层都是通过数组+链表+红黑树实现的.
通过一个常量TREEIFY_THRESHOLD(默认为8) 来决定要不要将链表转换为红黑树.
这也就意味着最坏情况下的性能可以从O(n)转换为O(logn)
通过hashmap的源码我们可以知道,其底层的数组是一个名为table的数组,在java8之前,数组的类型为entry,而在java8之后,数组的类型变成了Node`,因为引进了树嘛,哈哈不论是链表还是树,他们都是节点类型的:

数组中的每一个位置就是一个buket(可以理解为一个桶),通过哈希值决定元素应该放在哪个桶,哈希值相同的键值对以链表的形式存储.
当链表的大小超过TREEIFY_THRESHOLD时,链表就会变成红黑树,如下图:

当红黑树中的节点被删除到只有6个的时候,红黑树又会转变为链表
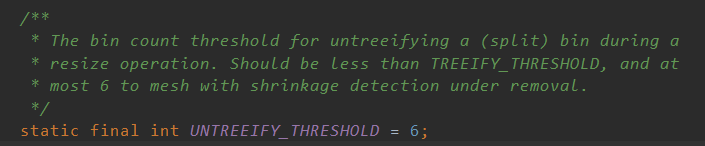
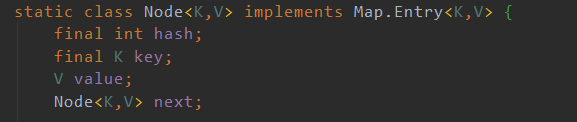
其中Node类的组成如图: 包括哈希值,key值,value值,以及指向下一个节点的next指针.
HashMap的构造函数
无参构造
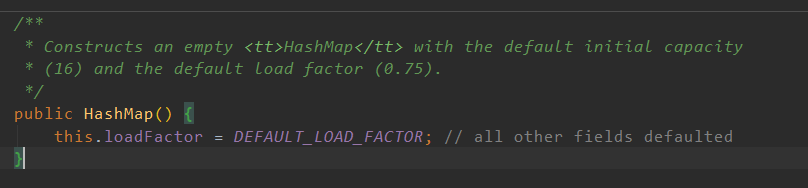
调用构造函数的时候并没有做什么初始化的工作,只给了容量大小这些东西,所以我们猜他应该在首次使用之后才会初始化.
put方法
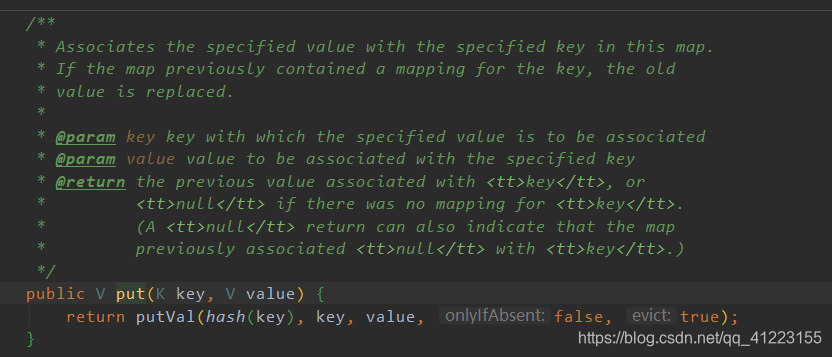
通过上图我们知道,hashmap的添加方法是调用了putVal这个方法实现,其中putVal()如下:
/**
* Implements Map.put and related methods
*表示实现自Map.put以及相关方法
* @param hash hash for key
* @param key the key
* @param value the value to put
* @param onlyIfAbsent if true, don't change existing value
* @param evict if false, the table is in creation mode.
* @return previous value, or null if none
*/
final V putVal(int hash, K key, V value, boolean onlyIfAbsent,
boolean evict) {
Node<K,V>[] tab; Node<K,V> p; int n, i;
if ((tab = table) == null || (n = tab.length) == 0)
n = (tab = resize()).length;//当初始数组为空,就会调用resize()方法为其初始化.
if ((p = tab[i = (n - 1) & hash]) == null)//算出键值对在table里的位置
tab[i] = newNode(hash, key, value, null);//如果该位置还没有元素在里面的话就直接new一个放进去
else {//如果该位置已经有元素了
Node<K,V> e; K k;
if (p.hash == hash &&
((k = p.key) == key || (key != null && key.equals(k))))
e = p;//如果该键与之前在里面的键完全一样,替换原来的键
else if (p instanceof TreeNode)//如果此时是红黑树结构了,就按照树的方式去存储键值对
e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value);
else {//如果不是红黑树
for (int binCount = 0; ; ++binCount) {
if ((e = p.next) == null) {
p.next = newNode(hash, key, value, null);//将键值对添加到链表最后
if (binCount >= TREEIFY_THRESHOLD - 1) //如果链表的长度达到了TREEIFY_THRESHOLD就要变为红黑树了
treeifyBin(tab, hash);
break;
}
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
break;//如果该键对应的值本来就是这个,直接退出
p = e;//如果该键的值原来不是这个,替换掉.
}
}
if (e != null) { // existing mapping for key
V oldValue = e.value;
if (!onlyIfAbsent || oldValue == null)
e.value = value;
afterNodeAccess(e);
return oldValue;
}
}
++modCount;
if (++size > threshold)
resize();//当hashmap的元素大于阈值只有调用resize()方法扩容
afterNodeInsertion(evict);
return null;
}
对于put方法的总结:

get方法
public V get(Object key) {
Node<K,V> e;
return (e = getNode(hash(key), key)) == null ? null : e.value;
}
/**
* Implements Map.get and related methods
*
* @param hash hash for key
* @param key the key
* @return the node, or null if none
*/
final Node<K,V> getNode(int hash, Object key) {
Node<K,V>[] tab; Node<K,V> first, e; int n; K k;
if ((tab = table) != null && (n = tab.length) > 0 &&
(first = tab[(n - 1) & hash]) != null) {
if (first.hash == hash && // always check first node
((k = first.key) == key || (key != null && key.equals(k))))
return first;
if ((e = first.next) != null) {
if (first instanceof TreeNode)
return ((TreeNode<K,V>)first).getTreeNode(hash, key);
do {
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
return e;
} while ((e = e.next) != null);
}
}
return null;
}
如何减少哈希碰撞
- 扰动函数: 促使元素位置分布均匀,减少碰撞几率.
- 使用final对象,并采用合适的
equals()和hashCode()方法.
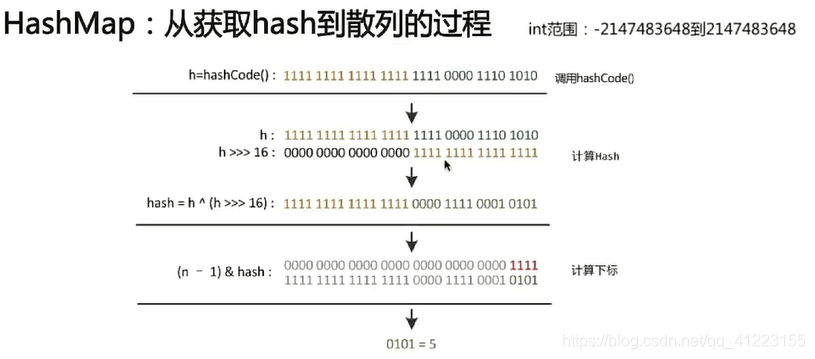
hashmap从获取hash到散列的过程
源码:

图解:
hashmap的扩容问题
hashmap的扩容因子为0.75,数组初始长度为16,当数组中占用的位置到了16x0.75=12的时候,它就会对数组进行扩容,扩从为其的两倍.
- 多线程环境下,调整大小会存在条件竞争,容易造成死锁,比如两个线程都发现需要调整hashmap的大小了,两个线程就都会去调整其大小,这就有可能造成死锁.
rehashing是一个比较耗时的过程,即每次扩容之后都要重新将数组中的键值对重新hash一遍放到新的数组里面去,这个过程比较耗时.
ConcurrentHashMap
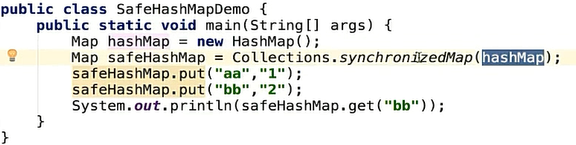
我们知道,hashmap并不是线程安全的,那么我们要使它变成线程安全的,那就需要通过Collections的synchronizedMap方法或者加synchronized关键字
这样子的话,效率其实就和hashtable一样了,就没有了优越感了哈哈哈,所以为了多线程下的效率问题,java5及其之后引入了ConcurrentHashMap
如何优化Hashtable?
- 通过锁细粒度化,将整个锁拆解成多个锁进行优化.
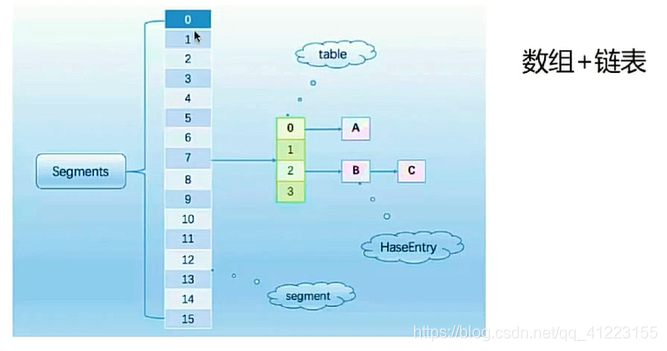
早期的ConcurrentHashMap:通过分段锁Segment来实现,即将锁一段一段的存储,然后给每个线程配一段锁访问该段锁对应的数据,默认分成16个segment,所以理论上它的效率是hashtable的16倍.
- java8之后,ConcurrentHashMap取消了分段锁机制,让table数组里的每个位置(
也叫buket)都采用一把锁来管理,从而采用了CAS+synchronized使锁更细化来保证并发安全.

注意: synchronized只锁住当前链表或者红黑树的头结点,这样只要哈希不冲突,就不会产生并发,效率自然就高了.
ConcurrentHashMap源码
ConcurrentHashMap是在J.U.C包下的.
大部分变量和hashmap是差不多的,比如初始时候的数组容量都是16,扩容因子都是0.75,链表树化的临界值都是8,而树链表化的临界值是6等.
ConcurrentHashMap的put()方法
public V put(K key, V value) {
return putVal(key, value, false);
}
/** Implementation for put and putIfAbsent */
final V putVal(K key, V value, boolean onlyIfAbsent) {
if (key == null || value == null) throw new NullPointerException();//表名它不允许键值为null,和hashtable一样,hashmap键值都是可以为空的.
int hash = spread(key.hashCode());//计算k的哈希值
int binCount = 0;
for (Node<K,V>[] tab = table;;) {//for循环是因为cas更新是需要不断去失败重试直到成功为止的
Node<K,V> f; int n, i, fh;
if (tab == null || (n = tab.length) == 0)
tab = initTable();//数组为空获取没有长度就给它初始化为16
else if ((f = tabAt(tab, i = (n - 1) & hash)) == null) {//不需要初始化就去找队友的应该放在那个位置,f表示头结点
if (casTabAt(tab, i, null,
new Node<K,V>(hash, key, value, null)))
break; // no lock when adding to empty bin没有该节点就直接利用cas机制添加,添加失败就break去等着下次循环
}
else if ((fh = f.hash) == MOVED)
tab = helpTransfer(tab, f);//
else {//如果发生了哈希碰撞
V oldVal = null;
synchronized (f) {//锁住链表或者红黑树的头结点
if (tabAt(tab, i) == f) {//如果f是头结点
if (fh >= 0) {//如果fh(头结点的哈希值)大于0
binCount = 1;//初始化链表计数器
for (Node<K,V> e = f;; ++binCount) {//遍历链表
K ek;
if (e.hash == hash &&
((ek = e.key) == key ||
(ek != null && key.equals(ek)))) {//节点存在就更新其值
oldVal = e.val;
if (!onlyIfAbsent)
e.val = value;
break;
}
Node<K,V> pred = e;
if ((e = e.next) == null) {//不存在就在尾部添加
pred.next = new Node<K,V>(hash, key,
value, null);
break;
}
}
}
else if (f instanceof TreeBin) {//如果头结点是红黑树的节点
Node<K,V> p;
binCount = 2;
if ((p = ((TreeBin<K,V>)f).putTreeVal(hash, key,
value)) != null) {//往树里添加节点
oldVal = p.val;
if (!onlyIfAbsent)
p.val = value;
}
}
}
}
if (binCount != 0) {
if (binCount >= TREEIFY_THRESHOLD)
treeifyBin(tab, i);
if (oldVal != null)
return oldVal;
break;
}
}
}
addCount(1L, binCount);
return null;
}

ConcurrentHashMap总结
比起Segment,锁拆的更细,直接锁的是头结点
- 首先使用无锁操作CAS插入头结点,失败就说明有其他线程在操作头结点,此时就循环重试.
- 如果头结点已经存在,则尝试获取头结点的同步锁,再进行操作.
HashMap,Hashtable,ConcurrentHashMap区别
- HashMap的键值都是可以为null的,而其他两个键值都是不可以为null的.
- Hashtable(锁住整个对象)和ConcurrentHashMap(CAS+同步锁)是线程安全的,而HashMap是线程不安全的.
- HashMap和ConcurrentHashMap底层是数组+链表+红黑树,而Hashtable底层是数组+链表














 337
337











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









