







利用正则表达式提取文章中的所有英文单词
1.先创建一个Pattern对象, 模式对象,可以理解成一个正则表达式对象
Pattern pattern = Pattern.compile("[a-zA-Z]+");//“+”:表示可以有一对多
Pattern pattern = Pattern.compile("[0-9]+");//“+”:表示可以有一对多 1997
2.创建一个匹配器对象
//理解:就是matcher 匹配器pattern(模式/样式),到content文本中去匹配
//找到就返回true,否则就返回false
Matcher matcher = pattern.matcher(content);
3、开始循环匹配
while (matcher.find()){
//匹配内容,文本,放到m.group(0)
System.out.println(“找到:”+matcher.group(0));
}
public static void main(String[] args){
String content ="1995年,互联网的蓬勃发展给了Oak机会。业界为了使死板、" +
"单调的静态网页能够“灵活”起来,急需一种软件技术来开发一种程序," +
"这种程序可以通过网络传播并且能够跨平台运行。于是,世界各大IT企业为此纷纷投" +
"入了大量的人力、物力和财力。这个时候," +
"Sun公司想起了那个被搁置起来很久的Oak,并且重新审视了那个用软件编写的试验平台," +
"由于它是按照嵌入式系统硬件平台体系结构进行编写的,所以非常小," +
"特别适用于网络上的传输系统,而Oak也是一种精简的语言,程序非常小,适合在网络上传输。" +
"Sun公司首先推出了可以嵌入网页并且可以随同网页在网络上传输的Applet(Applet是一种将" +
"小程序嵌入到网页中进行执行的技术),并将Oak更名为Java(在申请注册商标时,发现Oak已" +
"经被人使用了,再想了一系列名字之后,最终,使用了提议者在喝一杯Java咖啡时无意提到的" +
"Java词语)。5月23日,Sun公司在Sun world会议上正式发布Java和HotJava浏览器。" +
"IBM、Apple、DEC、Adobe、HP、Oracle、Netscape和微软等各大公司都纷纷停止了" +
"自己的相关开发项目,竞相购买了Java使用许可证,并为自己的产品开发了相应的Java平台。";
//提取文章中的所有英文单词
//1.先创建一个Pattern对象, 模式对象,可以理解成一个正则表达式对象
Pattern pattern = Pattern.compile("[a-zA-Z]+");//“+”:表示可以有一对多
// Pattern pattern = Pattern.compile("[0-9]+");//“+”:表示可以有一对多 1997
//2.创建一个匹配器对象
//理解:就是matcher 匹配器pattern(模式/样式),到content文本中去匹配
//找到就返回true,否则就返回false
Matcher matcher = pattern.matcher(content);
//3、开始循环匹配
while (matcher.find()){
//匹配内容,文本,放到m.group(0)
System.out.println("找到:"+matcher.group(0));
}
}
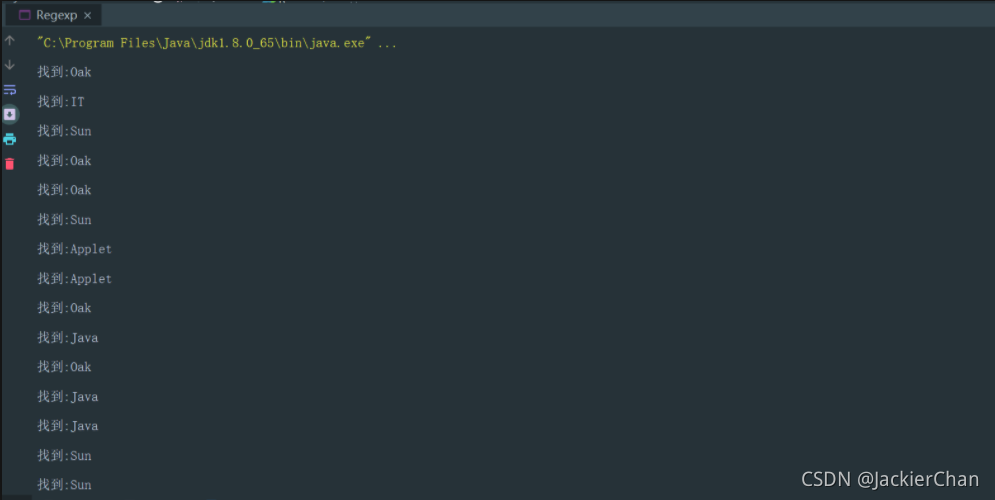
结果:
















 1033
1033











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











