







一、TreeMap类
(一)TreeMap类的介绍
reeMap继承了NavigableMap,而NavigableMap继承自SortedMap,为SortedMap添加了搜索选项,NavigableMap有几种方法,分别是不同的比较要求:floorKey是小于等于,ceilingKey是大于等于,lowerKey是小于,higherKey是大于。
1.1:构造函数
// 默认构造函数。使用该构造函数,TreeMap中的元素按照自然排序进行排列。
TreeMap()
// 创建的TreeMap包含Map
TreeMap(Map<? extends K, ? extends V> copyFrom)
// 指定Tree的比较器
TreeMap(Comparator<? super K> comparator)
// 创建的TreeSet包含copyFrom
TreeMap(SortedMap<K, ? extends V> copyFrom)1.2:属性
//比较器,因为TreeMap是有序的,通过comparator接口我们可以对TreeMap的内部排序进行精密的控制
private final Comparator<? super K> comparator;
//TreeMap红-黑节点,为TreeMap的内部类
private transient Entry<K,V> root = null;
//容器大小
private transient int size = 0;
//TreeMap修改次数
private transient int modCount = 0;
//红黑树的节点颜色--红色
private static final boolean RED = false;
//红黑树的节点颜色--黑色
private static final boolean BLACK = true;1.3:方法
Entry<K, V> ceilingEntry(K key)
K ceilingKey(K key)
void clear()
Object clone()
Comparator<? super K> comparator()
boolean containsKey(Object key)
NavigableSet<K> descendingKeySet()
NavigableMap<K, V> descendingMap()
Set<Entry<K, V>> entrySet()
Entry<K, V> firstEntry()
K firstKey()
Entry<K, V> floorEntry(K key)
K floorKey(K key)
V get(Object key)
NavigableMap<K, V> headMap(K to, boolean inclusive)
SortedMap<K, V> headMap(K toExclusive)
Entry<K, V> higherEntry(K key)
K higherKey(K key)
boolean isEmpty()
Set<K> keySet()
Entry<K, V> lastEntry()
K lastKey()
Entry<K, V> lowerEntry(K key)
K lowerKey(K key)
NavigableSet<K> navigableKeySet()
Entry<K, V> pollFirstEntry()
Entry<K, V> pollLastEntry()
V put(K key, V value)
V remove(Object key)
int size()
SortedMap<K, V> subMap(K fromInclusive, K toExclusive)
NavigableMap<K, V> subMap(K from, boolean fromInclusive, K to, boolean toInclusive)
NavigableMap<K, V> tailMap(K from, boolean inclusive)
SortedMap<K, V> tailMap(K fromInclusive)1.4:继承关系
java.lang.Object
java.util.AbstractMap<K, V>
java.util.TreeMap<K, V>
public class TreeMap<K,V>
extends AbstractMap<K,V>
implements NavigableMap<K,V>, Cloneable, java.io.Serializable {}1.5:例子
/**
* @desc TreeMap测试程序
*
* @author skywang
*/
public class TreeMapTest {
public static void main(String[] args) {
// 测试常用的API
testTreeMapOridinaryAPIs();
// 测试TreeMap的导航函数
//testNavigableMapAPIs();
// 测试TreeMap的子Map函数
//testSubMapAPIs();
}
/**
* 测试常用的API
*/
private static void testTreeMapOridinaryAPIs() {
// 初始化随机种子
Random r = new Random();
// 新建TreeMap
TreeMap tmap = new TreeMap();
// 添加操作
tmap.put("one", r.nextInt(10));
tmap.put("two", r.nextInt(10));
tmap.put("three", r.nextInt(10));
System.out.printf("\n ---- testTreeMapOridinaryAPIs ----\n");
// 打印出TreeMap
System.out.printf("%s\n",tmap );
// 通过Iterator遍历key-value
Iterator iter = tmap.entrySet().iterator();
while(iter.hasNext()) {
Map.Entry entry = (Map.Entry)iter.next();
System.out.printf("next : %s - %s\n", entry.getKey(), entry.getValue());
}
// TreeMap的键值对个数
System.out.printf("size: %s\n", tmap.size());
// containsKey(Object key) :是否包含键key
System.out.printf("contains key two : %s\n",tmap.containsKey("two"));
System.out.printf("contains key five : %s\n",tmap.containsKey("five"));
// containsValue(Object value) :是否包含值value
System.out.printf("contains value 0 : %s\n",tmap.containsValue(new Integer(0)));
// remove(Object key) : 删除键key对应的键值对
tmap.remove("three");
System.out.printf("tmap:%s\n",tmap );
// clear() : 清空TreeMap
tmap.clear();
// isEmpty() : TreeMap是否为空
System.out.printf("%s\n", (tmap.isEmpty()?"tmap is empty":"tmap is not empty") );
}
/**
* 测试TreeMap的子Map函数
*/
public static void testSubMapAPIs() {
// 新建TreeMap
TreeMap tmap = new TreeMap();
// 添加“键值对”
tmap.put("a", 101);
tmap.put("b", 102);
tmap.put("c", 103);
tmap.put("d", 104);
tmap.put("e", 105);
System.out.printf("\n ---- testSubMapAPIs ----\n");
// 打印出TreeMap
System.out.printf("tmap:\n\t%s\n", tmap);
// 测试 headMap(K toKey)
System.out.printf("tmap.headMap(\"c\"):\n\t%s\n", tmap.headMap("c"));
// 测试 headMap(K toKey, boolean inclusive)
System.out.printf("tmap.headMap(\"c\", true):\n\t%s\n", tmap.headMap("c", true));
System.out.printf("tmap.headMap(\"c\", false):\n\t%s\n", tmap.headMap("c", false));
// 测试 tailMap(K fromKey)
System.out.printf("tmap.tailMap(\"c\"):\n\t%s\n", tmap.tailMap("c"));
// 测试 tailMap(K fromKey, boolean inclusive)
System.out.printf("tmap.tailMap(\"c\", true):\n\t%s\n", tmap.tailMap("c", true));
System.out.printf("tmap.tailMap(\"c\", false):\n\t%s\n", tmap.tailMap("c", false));
// 测试 subMap(K fromKey, K toKey)
System.out.printf("tmap.subMap(\"a\", \"c\"):\n\t%s\n", tmap.subMap("a", "c"));
// 测试
System.out.printf("tmap.subMap(\"a\", true, \"c\", true):\n\t%s\n",
tmap.subMap("a", true, "c", true));
System.out.printf("tmap.subMap(\"a\", true, \"c\", false):\n\t%s\n",
tmap.subMap("a", true, "c", false));
System.out.printf("tmap.subMap(\"a\", false, \"c\", true):\n\t%s\n",
tmap.subMap("a", false, "c", true));
System.out.printf("tmap.subMap(\"a\", false, \"c\", false):\n\t%s\n",
tmap.subMap("a", false, "c", false));
// 测试 navigableKeySet()
System.out.printf("tmap.navigableKeySet():\n\t%s\n", tmap.navigableKeySet());
// 测试 descendingKeySet()
System.out.printf("tmap.descendingKeySet():\n\t%s\n", tmap.descendingKeySet());
}
/**
* 测试TreeMap的导航函数
*/
public static void testNavigableMapAPIs() {
// 新建TreeMap
NavigableMap nav = new TreeMap();
// 添加“键值对”
nav.put("aaa", 111);
nav.put("bbb", 222);
nav.put("eee", 333);
nav.put("ccc", 555);
nav.put("ddd", 444);
System.out.printf("\n ---- testNavigableMapAPIs ----\n");
// 打印出TreeMap
System.out.printf("Whole list:%s%n", nav);
// 获取第一个key、第一个Entry
System.out.printf("First key: %s\tFirst entry: %s%n",nav.firstKey(), nav.firstEntry());
// 获取最后一个key、最后一个Entry
System.out.printf("Last key: %s\tLast entry: %s%n",nav.lastKey(), nav.lastEntry());
// 获取“小于/等于bbb”的最大键值对
System.out.printf("Key floor before bbb: %s%n",nav.floorKey("bbb"));
// 获取“小于bbb”的最大键值对
System.out.printf("Key lower before bbb: %s%n", nav.lowerKey("bbb"));
// 获取“大于/等于bbb”的最小键值对
System.out.printf("Key ceiling after ccc: %s%n",nav.ceilingKey("ccc"));
// 获取“大于bbb”的最小键值对
System.out.printf("Key higher after ccc: %s%n\n",nav.higherKey("ccc"));
}
}运行结果:
{one=8, three=4, two=2}
next : one - 8
next : three - 4
next : two - 2
size: 3
contains key two : true
contains key five : false
contains value 0 : false
tmap:{one=8, two=2}
tmap is empty1.6:总结
1. TreeMap 是一个有序的key-value集合,它是通过红黑树实现的。
2. TreeMap 继承于AbstractMap,所以它是一个Map,即一个key-value集合。
3. TreeMap 实现了NavigableMap接口,意味着它支持一系列的导航方法。比如返回有序的key集合。
4. TreeMap 实现了Cloneable接口,意味着它能被克隆。
5. TreeMap 实现了java.io.Serializable接口,意味着它支持序列化。
6. TreeMap基于红黑树(Red-Black tree)实现。该映射根据其键的自然顺序进行排序,或者根据创建映射时提供的 Comparator 进行排序,具体取决于使用的构造方法。
7. TreeMap的基本操作 containsKey、get、put 和 remove 的时间复杂度是 log(n) 。
8. TreeMap是非同步的。 它的iterator 方法返回的迭代器是fail-fastl的。
(二)TreeMap对数字,英文字母,汉字等排序例子
2.1:对于一些简单的数字,英文字母等排序
TreeMap hm = new TreeMap<String, String>(new Comparator() {
public int compare(Object o1, Object o2) {
//如果有空值,直接返回0
if (o1 == null || o2 == null)
return 0;
return String.valueOf(o1).compareTo(String.valueOf(o2));
}
});compareTo(String str) :是String 提供的一个方法,如果参数字符串等于此字符串,则返回 0 值;如果按字典顺序此字符串小于字符串参数,则返回一个小于 0 的值;如果按字典顺序此字符串大于字符串参数,则返回一个大于 0 的值。
int compare(T o1,T o2):随第一个参数小于、等于或大于第二个参数而分别返回负整数、零或正整数。
2.2:对于处理有中文排序的问题
TreeMap hm = new TreeMap<String, String>(new Comparator() {
public int compare(Object o1, Object o2) {
//如果有空值,直接返回0
if (o1 == null || o2 == null)
return 0;
CollationKey ck1 = collator.getCollationKey(String.valueOf(o1));
CollationKey ck2 = collator.getCollationKey(String.valueOf(o2));
return ck1.compareTo(ck2);
}
});CollationKey:CollationKey 表示遵守特定 Collator 对象规则的 String。比较两个CollationKey 将返回它们所表示的 String 的相对顺序。使用 CollationKey来比较 String 通常比使用 Collator.compare 更快。因此,当必须多次比较 String 时(例如,对一个 String 列表进行排序),使用 CollationKey 会更高效。
2.3:排序综合例子
package ChineseSort;
import java.util.Collection;
import java.util.Iterator;
import java.util.SortedMap;
import java.util.TreeMap;
public class TestSort {
public static void main(String[] args) {
// TODO Auto-generated method stub
CollatorComparator comparator = new CollatorComparator();
TreeMap map = new TreeMap(comparator);
for (int i = 0; i < 10; i++) {
String s = "" + (int)(Math.random() * 1000);
map.put(s, s);
}
map.put("abcd", "abcd");
map.put("Abc", "Abc");
map.put("bbb", "bbb");
map.put("BBBB", "BBBB");
map.put("北京", "北京");
map.put("中国", "中国");
map.put("上海", "上海");
map.put("厦门", "厦门");
map.put("香港", "香港");
map.put("碑海", "碑海");
Collection col = map.values();
Iterator it = col.iterator();
while (it.hasNext()) {
System.out.println(it.next());
}
}
}
比较器类:package ChineseSort;
import java.text.CollationKey;
import java.text.Collator;
import java.util.Comparator;
public class CollatorComparator implements Comparator {
Collator collator = Collator.getInstance();
public int compare(Object element1, Object element2) {
CollationKey key1 = collator.getCollationKey(element1.toString());
CollationKey key2 = collator.getCollationKey(element2.toString());
return key1.compareTo(key2);
}
}运行该类,运行结果如下:
此时可以看到中文的排序已经完成正常。如果想不让英文区分大小写,则修改CollatorComparator类,找到element1.toString()修改为:element1.toString().toLowerCase()
325
62
653
72
730
757
874
895
909
921
Abc
abcd
bbb
BBBB
碑海
北京
上海
厦门
香港
中国(三)TreeMap重写Comparator降序排列
TreeMap中默认的排序为升序,如果要改变其排序可以自己写一个Comparator。
重写comparator:
class descendComparator implements Comparator
{
public int compare(Object o1,Object o2)
{
Double i1=(Double)o1;
Double i2=(Double)o2;
return -i1.compareTo(i2);
}
}TreeMap降序例子:
TreeMap<Double,Integer> map = new TreeMap<Double,Integer>(new descendComparator());
map.put(1.1, 1);
map.put(1.2, 2);
map.put(2.2, 4);
Set<Double> keys = map.keySet();
Iterator<Double> iter = keys.iterator();
while(iter.hasNext())
{
double a = iter.next();
System.out.println(" "+a+":"+map.get(a));
}运行结果
2.2:4
1.2:2
1.1:1(四)TreeMap分别对key和value降序排列
TreeMap默认按key进行升序排序,下面我们将对key和value进行降序排列。
4.1:key进行降序排序
Map<String,String> map = new TreeMap<String,String>(new Comparator<String>(){
public int compare(String obj1,String obj2){
//降序排序
return obj2.compareTo(obj1);
}
});
map.put("month", "The month");
map.put("bread", "The bread");
map.put("attack", "The attack");
Set<String> keySet = map.keySet();
Iterator<String> iter = keySet.iterator();
while(iter.hasNext()){
String key = iter.next();
System.out.println(key+":"+map.get(key));
}4.2:value进行降序排列
List<Map.Entry<String,String>> mappingList = null;
Map<String,String> map = new TreeMap<String,String>();
map.put("aaaa", "month");
map.put("bbbb", "bread");
map.put("ccccc", "attack");
//通过ArrayList构造函数把map.entrySet()转换成list
mappingList = new ArrayList<Map.Entry<String,String>>(map.entrySet());
//通过比较器实现比较排序
Collections.sort(mappingList, new Comparator<Map.Entry<String,String>>(){
public int compare(Map.Entry<String,String> mapping1,Map.Entry<String,String> mapping2){
return mapping1.getValue().compareTo(mapping2.getValue());
}
});
for(Map.Entry<String,String> mapping:mappingList){
System.out.println(mapping.getKey()+":"+mapping.getValue());
}(五)TreeMap红黑树原理,源码解析(不建议发布-借鉴内容不懂)
5.1:红黑树简介
红黑树是一种自平衡排序二叉树,树中每个节点的值,都大于或等于在它的左子树中的所有节点的值,并且小于或等于在它的右子树中的所有节点的值,这确保红黑树运行时可以快速地在树中查找和定位的所需节点。
对于 TreeMap 而言,由于它底层采用一棵“红黑树”来保存集合中的 Entry,这意味这 TreeMap 添加元素、取出元素的性能都比 HashMap 低:当 TreeMap 添加元素时,需要通过循环找到新增 Entry 的插入位置,因此比较耗性能;当从 TreeMap 中取出元素时,需要通过循环才能找到合适的 Entry,也比较耗性能。但 TreeMap、TreeSet 比 HashMap、HashSet 的优势在于:TreeMap 中的所有 Entry 总是按 key 根据指定排序规则保持有序状态,TreeSet 中所有元素总是根据指定排序规则保持有序状态。
为了理解 TreeMap 的底层实现,必须先介绍排序二叉树和红黑树这两种数据结构。其中红黑树又是一种特殊的排序二叉树。
排序二叉树是一种特殊结构的二叉树,可以非常方便地对树中所有节点进行排序和检索。
排序二叉树要么是一棵空二叉树,要么是具有下列性质的二叉树:
- 若它的左子树不空,则左子树上所有节点的值均小于它的根节点的值;
- 若它的右子树不空,则右子树上所有节点的值均大于它的根节点的值;
- 它的左、右子树也分别为排序二叉树。
图 1 显示了一棵排序二叉树:
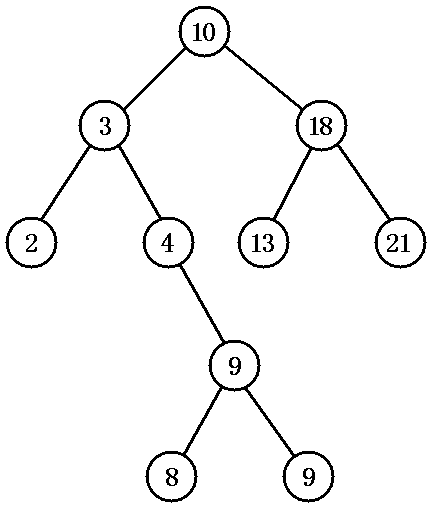
对排序二叉树,若按中序遍历就可以得到由小到大的有序序列。如图 1 所示二叉树,中序遍历得:
| {2,3,4,8,9,9,10,13,15,18} |
创建排序二叉树的步骤,也就是不断地向排序二叉树添加节点的过程,向排序二叉树添加节点的步骤如下:
- 以根节点当前节点开始搜索。
- 拿新节点的值和当前节点的值比较。
- 如果新节点的值更大,则以当前节点的右子节点作为新的当前节点;如果新节点的值更小,则以当前节点的左子节点作为新的当前节点。
- 重复 2、3 两个步骤,直到搜索到合适的叶子节点为止。
- 将新节点添加为第 4 步找到的叶子节点的子节点;如果新节点更大,则添加为右子节点;否则添加为左子节点。
5.2:TreeMap的红黑树
数据结构
1 红黑树的节点颜色--红色
private static final boolean RED = false;
2 红黑树的节点颜色--黑色
private static final boolean BLACK = true;
3 “红黑树的节点”对应的类。
static final class Entry<K,V> implements Map.Entry<K,V> { ... }
Entry包含了6个部分内容:key(键)、value(值)、left(左孩子)、right(右孩子)、parent(父节点)、color(颜色)
Entry节点根据key进行排序,Entry节点包含的内容为value。
相关操作
1 左旋
private void rotateLeft(Entry<K,V> p) { ... }
2 右旋
private void rotateRight(Entry<K,V> p) { ... }
3 插入操作
public V put(K key, V value) { ... }
4 插入修正操作
红黑树执行插入操作之后,要执行“插入修正操作”。
目的是:保红黑树在进行插入节点之后,仍然是一颗红黑树
private void fixAfterInsertion(Entry<K,V> x) { ... }
5 删除操作
private void deleteEntry(Entry<K,V> p) { ... }
6 删除修正操作
红黑树执行删除之后,要执行“删除修正操作”。
目的是保证:红黑树删除节点之后,仍然是一颗红黑树
private void fixAfterDeletion(Entry<K,V> x) { ... }
5.3:TreeMap添加节点源码
我们来分析 TreeMap 添加节点(TreeMap 中使用 Entry 内部类代表节点)的实现,TreeMap 集合的 put(K key, V value) 方法实现了将 Entry 放入排序二叉树中,下面是该方法的源代码:
public V put(K key, V value)
{
// 先以 t 保存链表的 root 节点
Entry<K,V> t = root;
// 如果 t==null,表明是一个空链表,即该 TreeMap 里没有任何 Entry
if (t == null)
{
// 将新的 key-value 创建一个 Entry,并将该 Entry 作为 root
root = new Entry<K,V>(key, value, null);
// 设置该 Map 集合的 size 为 1,代表包含一个 Entry
size = 1;
// 记录修改次数为 1
modCount++;
return null;
}
int cmp;
Entry<K,V> parent;
Comparator<? super K> cpr = comparator;
// 如果比较器 cpr 不为 null,即表明采用定制排序
if (cpr != null)
{
do {
// 使用 parent 上次循环后的 t 所引用的 Entry
parent = t;
// 拿新插入 key 和 t 的 key 进行比较
cmp = cpr.compare(key, t.key);
// 如果新插入的 key 小于 t 的 key,t 等于 t 的左边节点
if (cmp < 0)
t = t.left;
// 如果新插入的 key 大于 t 的 key,t 等于 t 的右边节点
else if (cmp > 0)
t = t.right;
// 如果两个 key 相等,新的 value 覆盖原有的 value,
// 并返回原有的 value
else
return t.setValue(value);
} while (t != null);
}
else
{
if (key == null)
throw new NullPointerException();
Comparable<? super K> k = (Comparable<? super K>) key;
do {
// 使用 parent 上次循环后的 t 所引用的 Entry
parent = t;
// 拿新插入 key 和 t 的 key 进行比较
cmp = k.compareTo(t.key);
// 如果新插入的 key 小于 t 的 key,t 等于 t 的左边节点
if (cmp < 0)
t = t.left;
// 如果新插入的 key 大于 t 的 key,t 等于 t 的右边节点
else if (cmp > 0)
t = t.right;
// 如果两个 key 相等,新的 value 覆盖原有的 value,
// 并返回原有的 value
else
return t.setValue(value);
} while (t != null);
}
// 将新插入的节点作为 parent 节点的子节点
Entry<K,V> e = new Entry<K,V>(key, value, parent);
// 如果新插入 key 小于 parent 的 key,则 e 作为 parent 的左子节点
if (cmp < 0)
parent.left = e;
// 如果新插入 key 小于 parent 的 key,则 e 作为 parent 的右子节点
else
parent.right = e;
// 修复红黑树
fixAfterInsertion(e); // ①
size++;
modCount++;
return null;
}上面程序中代码就是实现“排序二叉树”的关键算法,每当程序希望添加新节点时:系统总是从树的根节点开始比较 —— 即将根节点当成当前节点,如果新增节点大于当前节点、并且当前节点的右子节点存在,则以右子节点作为当前节点;如果新增节点小于当前节点、并且当前节点的左子节点存在,则以左子节点作为当前节点;如果新增节点等于当前节点,则用新增节点覆盖当前节点,并结束循环 —— 直到找到某个节点的左、右子节点不存在,将新节点添加该节点的子节点 —— 如果新节点比该节点大,则添加为右子节点;如果新节点比该节点小,则添加为左子节点。
5.4:TreeMap删除节点源码
private void deleteEntry(Entry<K,V> p)
{
modCount++;
size--;
// 如果被删除节点的左子树、右子树都不为空
if (p.left != null && p.right != null)
{
// 用 p 节点的中序后继节点代替 p 节点
Entry<K,V> s = successor (p);
p.key = s.key;
p.value = s.value;
p = s;
}
// 如果 p 节点的左节点存在,replacement 代表左节点;否则代表右节点。
Entry<K,V> replacement = (p.left != null ? p.left : p.right);
if (replacement != null)
{
replacement.parent = p.parent;
// 如果 p 没有父节点,则 replacemment 变成父节点
if (p.parent == null)
root = replacement;
// 如果 p 节点是其父节点的左子节点
else if (p == p.parent.left)
p.parent.left = replacement;
// 如果 p 节点是其父节点的右子节点
else
p.parent.right = replacement;
p.left = p.right = p.parent = null;
// 修复红黑树
if (p.color == BLACK)
fixAfterDeletion(replacement); // ①
}
// 如果 p 节点没有父节点
else if (p.parent == null)
{
root = null;
}
else
{
if (p.color == BLACK)
// 修复红黑树
fixAfterDeletion(p); // ②
if (p.parent != null)
{
// 如果 p 是其父节点的左子节点
if (p == p.parent.left)
p.parent.left = null;
// 如果 p 是其父节点的右子节点
else if (p == p.parent.right)
p.parent.right = null;
p.parent = null;
}
}
}TreeMap 删除节点采用下图所示右边的情形进行维护——也就是用被删除节点的右子树中最小节点与被删节点交换的方式进行维护。
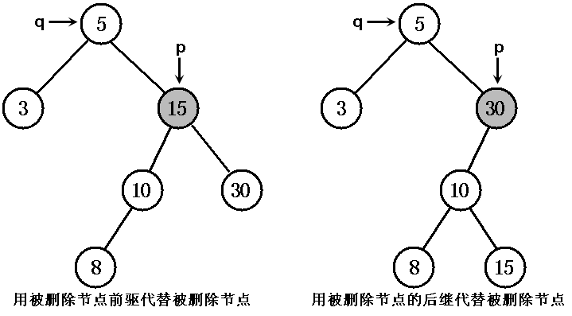
当程序从排序二叉树中删除一个节点之后,为了让它依然保持为排序二叉树,程序必须对该排序二叉树进行维护。维护可分为如下几种情况:
(1)被删除的节点是叶子节点,则只需将它从其父节点中删除即可。
(2)被删除节点 p 只有左子树,将 p 的左子树 pL 添加成 p 的父节点的左子树即可;被删除节点 p 只有右子树,将 p 的右子树 pR 添加成 p 的父节点的右子树即可。
(3)若被删除节点 p 的左、右子树均非空,有两种做法:
1. 将 pL 设为 p 的父节点 q 的左或右子节点(取决于 p 是其父节点 q 的左、右子节点),将 pR 设为 p 节点的中序前趋节点 s 的右子节点(s 是 pL 最右下的节点,也就是 pL 子树中最大的节点)。
2. 以 p 节点的中序前趋或后继替代 p 所指节点,然后再从原排序二叉树中删去中序前趋或后继节点即可。(也就是用大于 p 的最小节点或小于 p 的最大节点代替 p 节点即可)。
5.5:Java红黑树总结
1:每个节点要么是红色,要么是黑色。
2:根节点永远是黑色的。
3:所有的叶节点都是空节点(即 null),并且是黑色的。
4:每个红色节点的两个子节点都是黑色。(从每个叶子到根的路径上不会有两个连续的红色节点)
5:从任一节点到其子树中每个叶子节点的路径都包含相同数量的黑色节点。

















 602
602

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











