






源代码中不要加中文注释,会导致最后的#无法对齐
代码如下:
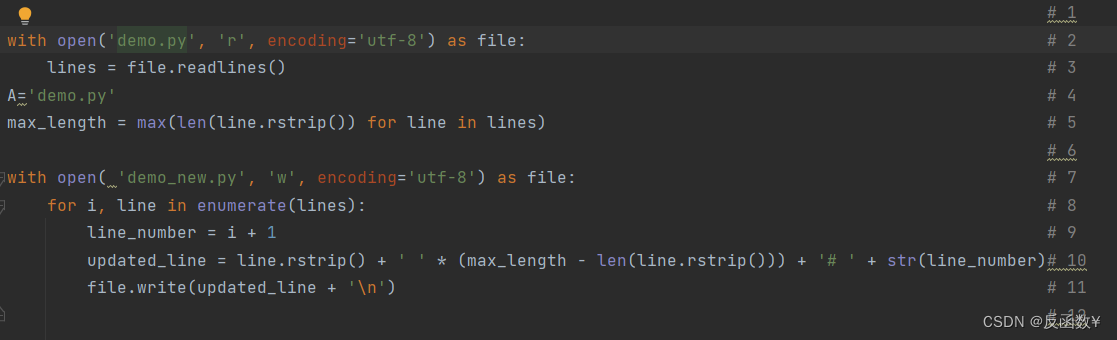
with open('demo.py', 'r', encoding='utf-8') as file:
lines = file.readlines()
A='demo.py'
max_length = max(len(line.rstrip()) for line in lines)
with open( 'demo_new.py', 'w', encoding='utf-8') as file:
for i, line in enumerate(lines):
line_number = i + 1
updated_line = line.rstrip() + ' ' * (max_length - len(line.rstrip())) + '# ' + str(line_number)
file.write(updated_line + '\n')
运行结果:
代码注释:
# 打开名为'demo.py'的文件,以只读方式读取(使用utf-8编码)
with open('demo.py', 'r', encoding='utf-8') as file:
# 将文件的内容按行读取,并存储在列表变量lines中
lines = file.readlines()
#列表解析式len(line.rstrip()) for line in lines用于创建一个包含每行长度的列表。
max_length = max(len(line.rstrip()) for line in lines) #再Lines里面,对每行line的长度进行测量,然后选出最大值
# 创建一个名为'demo_new.py'的文件,并以写入方式打开(使用utf-8编码)
with open('demo_new.py', 'w', encoding='utf-8') as file:
# 遍历lines列表中的每一行(同时获取行号和行内容)
#enumerate(lines)将lines列表转换为一个可迭代对象,每次迭代返回一个包含索引和对应元素的元组。
for i, line in enumerate(lines):
# 计算行号(从1开始)
line_number = i + 1
# 更新行内容,将行末尾的空格和换行符去除,并在行末尾添加空格,使其达到最大长度
# 然后在行末尾添加'#'、行号,并将结果存储在updated_line中
updated_line = line.rstrip() + ' ' * (max_length - len(line.rstrip())) + '# ' + str(line_number)
# 将updated_line写入到文件中,并在末尾添加换行符
file.write(updated_line + '\n')













 4588
4588











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









