







二叉排序树
二叉排序树(Binary Sort Tree),又称二叉查找树(Binary Search Tree),亦称二叉搜索树。
定义
二叉排序树或者是一棵空树,或者是具有下列性质的二叉树:
(1)若左子树不空,则左子树上所有节点的值均小于它的根节点的值;
(2)若右子树不空,则右子树上所有节点的值均大于它的根节点的值;
(3)左、右子树也分别为二叉排序树;
(4)没有键值相等的节点。
二叉排序树进行中序遍历可以得到一个关键字的有序序列。
查找步骤
若根结点的关键字值等于查找的关键字,成功。 否则,若小于根结点的关键字值,递归查左子树。
若大于根结点的关键字值,递归查右子树。
若子树为空,查找不成功。
查找性能分析
- 一棵二叉查找树的平均查找长度(ASL),见下图公式(1)。
- 一棵满二叉排序树的平均查找长度,见下图公式(2)。
- 一棵斜二叉排序树的平均查找长度,见下图公式(3)。

满树是查找最好的情况(和折半查找判定树相同),斜树查找情况最差(和顺序查找相同)。在随机的情况下,二叉排序树的平均查找长度和log2n是成正比的,在某些情况下(有人研究证明,这种情况出现的概率约为46.5%),尚需在构成二叉排序树的过程中进行“平衡化”处理,成为二叉平衡树,当然用二叉平衡树来查找,相比于二叉排序树在任何情况下都是一种优化。
与次优二叉树相对,二叉排序树是一种动态树表。其特点是:树的结构通常不是一次生成的,而是在查找过程中,当树中不存在关键字等于给定值的结点时再进行插入,如果值已经存在就插入失败。新插入的结点一定是一个新添加的叶子结点,并且是查找不成功时查找路径上访问的最后一个结点的左孩子或右孩子结点。
(次优二叉树:如果二叉树的带权内路径长度PH值在所有具有同样权值的的二叉树中近似为最小,称这类二叉树为次优查找二叉树。)
删除结点
在二叉排序树删去一个结点,分三种情况讨论:
- 若删除的结点是叶子结点,可以直接删除。
- 若删除的结点只有左子树或者只有右子树,直接让这个左子树或者右子树替代删除结点,成为被删除结点的双亲结点的左子树或者右子树,作此修改也不破坏二叉排序树的特性。
- 若p结点的左子树和右子树均不空。在删去p之后,为保持其它元素之间的相对位置不变,可按中序遍历保持有序进行调整,可以有两种做法:
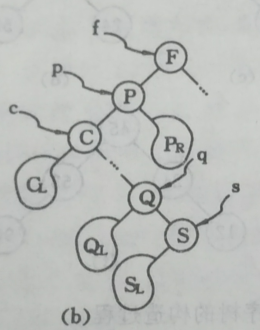
其一是令p的左子树为f的左/右(依p是f的左子树还是右子树而定,下图中* p是* f的左子树)子树,s为p左子树的最右下的结点,而p的右子树为s的右子树;如下图

其二是(中序遍历)令p的直接前驱(或直接后继)替代p,然后再从二叉排序树中删去它的直接前驱(或直接后继)即让f的左子树(如果有的话)成为p左子树的最左下结点(如果有的话),再让f成为p的左右结点的父结点。
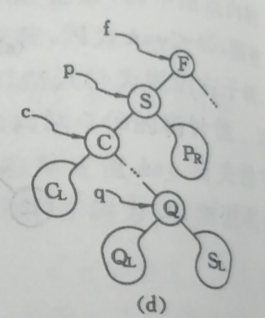
下图图b 中当以直接前驱* s替代* p时,由于* s只有左子树SL,则在删去s之后,只要令SL为 s的双亲*q的右子树即可。8
删除实现的Java代码
Java代码
/**
*方法名称:delete()
*方法描述:删除结点
*@param采用递归的方式进行删除
*@returnString
*@Exception
*/
private void deleteNode(BinarySortTree p)
{
//TODOAuto-generatedmethodstub
if(p!=null)
{
//如果结点有左子树
/*1。若p有左子树,找到其左子树的最右边的叶子结点r,用该叶子结点r来替代p,把r的左孩子
作为r的父亲的右孩子。
2。若p没有左子树,直接用p的右孩子取代它。
*/
if(p.lChild!=null)
{
BinarySortTree r=p.lChild;
BinarySortTree prev=p.lChild;
while(r.rChild!=null)
{
prev=r;
r=r.rChild;
}
p.data=r.data;
//若此时r不是p的左孩子,p的左子树不变,r的左子树作为r的父结点的右孩子结点
//(这个if结构里面的代码对应于上图b图d的情况)
if(prev!=r) //代码层面理解相当于如果进入过上面的while循环
{
prev.rChild=r.lChild;
}
else//代码层面理解相当于如果没进入过上面的while循环
{
//若r是p的孩子,则p的左子树指向r的左子树
p.lChild=r.lChild;
}
}
else
{
p=p.rChild;
}
}
}
优化
Size Balanced Tree(SBT)
AVL树
红黑树
Treap(Tree+Heap)
这些均可以使查找树的高度为O(log(n))















 967
967











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









