







最近面试有点多,没来的及写面经,就单独开个帖子记录一下碰到的一些不懂的技术问题:
- AQS中两个队列如何工作,这个结合os中阻塞和就绪两种情况讲
- 分布式的理解,这个问的频率很高
- nacos怎么进行服务注册和发现的
- mysql什么情况会发生死锁,如何加表锁,什么情况使用垂直分表,什么情况使用水平分表
- jdbc为什么要使用反射加载驱动
- docker如何实现容器的隔离的,dockfile记录了什么信息
- 最左匹配原则的索引结构是什么样的
- 消息中间件如何保证消息不丢失,ACK=0,-1,1表示啥,消息中间件挂了那客户端的消息怎么办,如何保证消费者能最快的速度进行消费。
- uml有哪几种图,写代码前会画uml图吗
- 软件开发的模式
- Threadlocal中value为什么是强引用
- Redis中zset为什么用跳表而不用b+树,Redis的延时双删
- RBAC 0,1,2,以及部门考虑过没有(这个是项目相关)
- 反向代理的时候
- 说说epoll
- 了解新版jdk的新特性吗,了解golong吗,了解k8s吗
- Leader选举策略有哪些
- CAP,现在有什么方法解决了AP和CP不相容的问题
- Spring中如何创建一个事务,事务的传播级别
- AOP除了实现日志还能实现什么功能
- JVM发生OOM的集中情况,如何分析解决,为什么会频繁出现YoungGC和FulGC
- 使用过哪些网络分析工具或者抓包工具
算法题:kmp,链表有环如何判断,给一个ipv4的地址返回一个int类型的数据(直接使用int会溢出),在服务器上找到cpu占用率top90的进程。
MySQL
使用limit查询慢的原因?
MySQL通过 limit 实现分页查询。limit 接收一个或两个整数型参数。如果是两个参数,第一个指定返回记录行的偏移量,第二个指定返回记录行的最大数目。初始记录行的偏移量是 0。对于小的偏移量,直接用 limit 查询没有什么问题。随着数据量的增大,越往后分页,limit 语句的偏移量越大,速度也会明显变慢。
limit 90000,10的意思扫描满足条件的90010行,扔掉前面的90000行,返回最后的10行,问题就在这里,如果是limit 100000,100,需要扫描100100行,在一个高并发的应用里,每次查询需要扫描超过10W行,性能肯定大打折扣。文中还提到limit n性能是没问题的,因为只扫描n行。
优化limit查询?
- 使用主键索引(使用子查询或者连接查询查询id)优化,比如加上where id>1000 limit X,X,从而加速查询
- 使用 between and 语句分页效率快N倍
- 分表存储
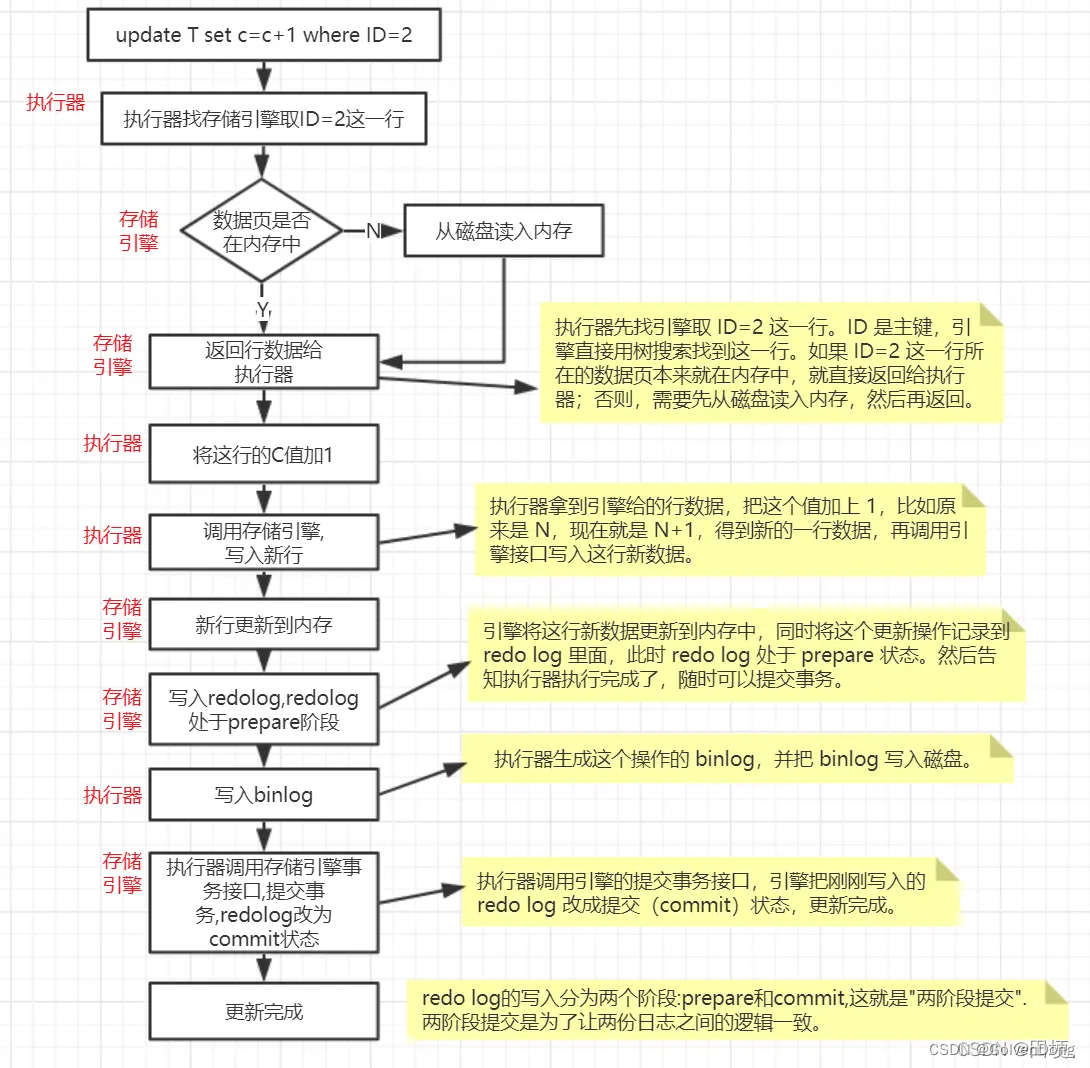
更新语句的执行流程
参考链接:https://blog.csdn.net/weixin_51626435/article/details/123411484
正常语句的执行流程:
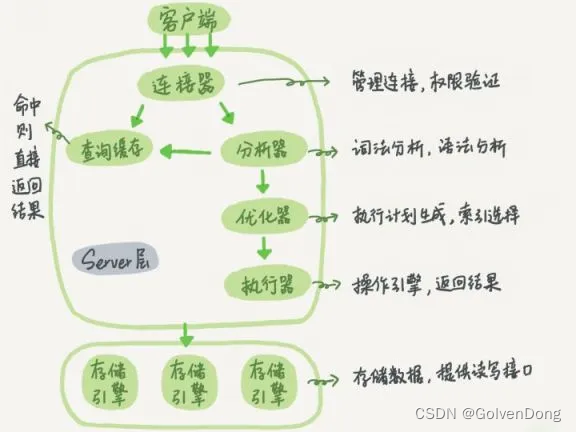
更新语句的执行流程:
- 连接器、分析器、优化器、执行器
- 使用两阶段提交的方式进行更新。
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









