









在学习 word2vec 时,首先接触到的就是 Huffman 编码,这里简单记录一下学习内容。
目录
一、简介
哈夫曼编码(Huffman Coding),又称霍夫曼编码,是一种编码方式,哈夫曼编码是可变字长编码(VLC)的一种。是 Huffman 于 1952 年提出一种编码方法,该方法完全依据字符出现概率来构造异字头的平均长度最短的码字,有时称之为最佳编码,一般就叫做Huffman 编码(有时也称为霍夫曼编码)[1]。
首先,为介绍引入 Huffman 编码的重要性,这里介绍一种简单的 word2vec 方法:One-Hot 编码。
One-Hot 编码即独热编码,又称一位有效编码,其方法是使用 位状态寄存器来对
个状态进行编码,每个状态都有它独立的寄存器位,并且在任意时候,其中只有一位有效。举个例子,“冬天的雨和夏天的雪”,这句中存在的词有“冬天”、“夏天”、“雨”、“雪”、“和”、“的”,即
,故我们分别编码得:[100000]、[010000]、[001000]、[000100]、[000010]、[000001]。
这种编码方式存在离散稀疏问题,比如当语料库的十分庞大时,得到的编码向量会过于稀疏,并且会造成维度灾难。
Huffman 编码给出了一种解决方案,它是一种用于无损数据压缩的熵编码(权编码)算法。
二、Huffman树
给定 个权值作为
个叶子结点,构造一棵二叉树,若该树的带权路径长度达到最小,称这样的二叉树为最优二叉树,也称为哈夫曼树(Huffman Tree)。哈夫曼树是带权路径长度最短的树,权值较大的结点离根较近[2]。
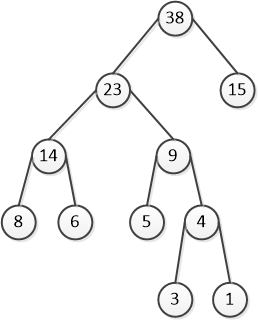
哈夫曼树又称为最优树,这里先给出一个哈夫曼树便于理解下面概念(图1 )。
(一)基础术语
1. 路径和路径长度
在一棵树中,从一个结点往下可以达到的子或孙子结点之间的通路(不可逆向、横向传递),称为路径。通路中分支的数目称为路径长度(等同于通过经过的层数)。若规定根结点的层数为 ,则从根结点到第
层结点的路径长度为
。
图1 中,权重为 38 的结点为根结点,以权重为 4 结点为例,其路径为 38→23→9→4,路径长度为 3 。
2. 结点的权及带权路径长度
若将树中结点赋予一个有着某种含义的数值,则这个数值称为该结点的权。结点的带权路径长度为:从根结点到该结点之间的路径长度与该结点的权的乘积。
图1 中,权重为 4 结点的带权路径长度为 。
3. 树的带权路径长度
树的带权路径长度规定为所有叶子结点的带权路径长度之和,记为 WPL 。。
图1 中,树的带权路径长度为 。
(二)构建
假设有 个权值,则构造出的哈夫曼树有
个叶子结点。
个权值分别设为
,则哈夫曼树的构造规则为:
1. 将 看成是有
棵树的森林(每棵树仅有一个结点);
2. 在森林中选出两个根结点的权值最小的树合并,作为一棵新树的左、右叶子结点,且新树的根结点权值为其左、右叶子结点权值之和;
3. 从森林中删除选取的两棵树,并将新树加入森林(新树只观察其合并之后的根结点,不再考虑其叶子结点);
4. 重复2、3步,直到森林中只剩一棵树为止,该树即为所求得的哈夫曼树。
下面给出一个具体例子,方便理解。
例:假设我们在一个文本中发现“冬天”、“夏天”、“雨”、“雪”、“和”、“的”这六个词出现的次数分别是1、3、5、6、8、15。我们以这六个词为叶子结点,以相应词频为权值,构造一棵哈夫曼树(图2 )。

从图2 中可以看到,权值越大的结点离根越近。
三、Huffman编码
这里直接给出一个定理:在变字长编码中,如果码字长度严格按照对应符号出现的概率大小逆序排列(从大到小),则其平均码字长度为最小(证明略,详细可见[1])。我们就上例中“冬天”、“夏天”、“雨”、“雪”、“和”、“的”六个词给出 Huffman 编码方法,具体过程以图示展示(图3 ):
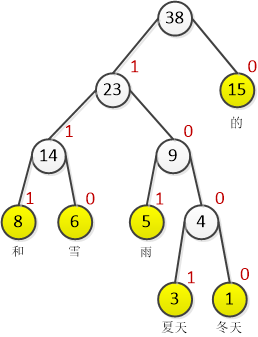
如图3 所示,我们在每个分支结点分别标注 1 或 0 ,注意,这里标注时保证整体标准一致即可(即可左 1 右 0 ,或左 0 右 1 )。最终的 Huffman 编码结果分别为:
- “冬天”:[1,0,0,0]
- “夏天”:[1,0,0,1]
- “雨”:[1,0,1]
- “雪”:[1,1,0]
- “和”:[1,1,1]
- “的”:[0]
四、代码
这里直接给出相关代码,具体描述请看代码中的注释信息。
(一)python
# 结点对象
class Node:
def __init__(self):
# 权重
self.frequency = 0
# 符号名
self.name = None
# 左结点
self.l_child = None
# 右结点
self.r_child = None
self.code = None
# 对频数排序
def __lt__(self, other):
return self.frequency < other.frequency
# 从文本中获取每个符号的频数
def frequency(origin_path):
# 频数字典
frequency_dict = dict()
with open(origin_path, 'r') as f:
for line in f.readlines():
line = line.lower()
for j in line:
if j.isalpha():
if j in frequency_dict:
frequency_dict[j] += 1
else:
frequency_dict.update({j: 1})
# 返回频数字典
return frequency_dict
# 创建哈夫曼树
def establish_huffman_tree(frequency_dict):
# 输出哈夫曼树的根结点
node_list = []
for j in frequency_dict:
a = Node()
# 频数
a.frequency = frequency_dict[j]
# 符号名
a.name = j
node_list.append(a)
# while len(node_list) > 1:
# 生成N-1个新结点
for j in range(len(frequency_dict) - 1):
# 从大到小排序
node_list.sort(reverse=True)
# 提取频数最小的两个结点,并将它们从node_list中删除
node_1 = node_list.pop()
node_2 = node_list.pop()
# 新结点
new_node = Node()
new_node.frequency = node_1.frequency + node_2.frequency
# 左边频数较右边频数大
new_node.l_child = node_2
new_node.r_child = node_1
node_list.append(new_node)
# 返回哈夫曼树的根结点
return node_list[0]
# 哈夫曼编码
def encode(base_node, rst_dict, code):
if base_node.name:
rst_dict.update({base_node.name: code})
return
code += '1'
encode(base_node.l_child, rst_dict, code)
code = code[:-1]
code += '0'
encode(base_node.r_child, rst_dict, code)
return rst_dict
# 编码文本文件,并写入新的文件
def encode_text(code_dict, origin_path, code_text):
string = ''
with open(origin_path, 'r') as f:
for line in f.readlines():
line = line.lower()
for j in line:
if j.isalpha():
string += code_dict[j]
else:
string += '\n'
with open(code_text, 'w') as f:
f.write(string)
# 解码
def decode(text_address, result_address, base_node):
text_string = ''
a = base_node
with open(text_address, 'r') as f:
for line in f.readlines():
for j in line:
if j == '1':
b = a.l_child
if b.name:
text_string += b.name
a = base_node
else:
a = b
elif j == '0':
b = a.r_child
if b.name:
text_string += b.name
a = base_node
else:
a = b
else:
text_string += '\n'
with open(result_address, 'w') as f:
f.write(text_string)
if __name__ == '__main__':
# 原始文件路径
my_origin_path = "../data/origin.txt"
# 获取频数字典
my_frequency_dict = frequency(my_origin_path)
# my_frequency_dict = {'冬天': 1, '夏天': 3, '雨': 5, '雪': 6, '和': 8, '的': 15}
# my_frequency_dict = {'a': 1, 'b': 3, 'c': 5, 'd': 6, 'e': 8, 'f': 15}
# 构建哈夫曼树
my_base_node = establish_huffman_tree(my_frequency_dict)
# 哈夫曼编码
my_code_dict = encode(my_base_node, {}, '')
# 编码文件路径
my_code_text = "../data/code.txt"
# 编码文本文件
encode_text(my_code_dict, my_origin_path, my_code_text)
# 解码文件路径
my_result_address = "../data/result.txt"
decode(my_code_text, my_result_address, my_base_node)
(二)结果
- origin.txt
该文件为待编码文件,内容如下,这里分别将“冬天”、“夏天”、“雨”、“雪”、“和”、“的”匹配到“a”、“b”、“c”、“d”、“e”、“f”,并频数分别设定为1、3、5、6、8、15。
abbbcccccddddddeeeeeeeefffffffffffffff
- code.txt
文件内容如下:
1000100110011001101101101101101110110110110110110111111111111111111111111000000000000000
该文件为对 origin.txt 进行哈夫曼编码的结果文件,该结果与第三部分得出的编码结果相同。
- result.txt
文件内容如下:
abbbcccccddddddeeeeeeeefffffffffffffff
该文件输出结果是对 code.txt 文件内容的解码,解码结果与 origin.txt 文件内容相同。














 428
428











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









