







字符串:
title() 将每个单词的首字母都改为大写。
upper() 将每个字母都改为大写。
lower() 将每个字母都改为小写。
删除空白:rstrip() 删除字符串末尾空白
lstrip() 删除字符串开头空白
strip() 同时删除字符串两边的空白
列表:
在列表中添加元素:append()、extend()
在列表中插入元素:insert()
在列表中删除元素:
1、使用 del 语句删除元素
list1 = [1,2,3,4]
del list1[2] # 删除3
2、使用pop方法删除列表末尾的元素
list1 = [1,2,3,4]
list1.pop() # 删除最后一个元素4
3、弹出列表中任何位置处的元素,在pop括号内指定要删除元素的索引
list1 = [1,2,3,4]
list1.pop(2) # 删除元素3
4、根据值删除元素,remove()
list1 = [1,2,3,4]
list1.remove('2') # 删除元素2
注意:使用 remove() 方法只删除第一个指定的值,如果要删除的值可能在列表中出 现多次,就需要使用循环来判断是否删除了所有这样的值。
列表排序:
1、使用sort()方法对列表进行永久性排序
list1 = [1,2,3,4]
list1.sort()
还可以按与字母相反的顺序排列列表元素
list1.sort(reverse=True)
2、使用sorted()对列表进行临时排序
sorted(list1)
3、倒着打印列表,方法reverse()永久性的修改列表元素的排列顺序。
list1.reverse()
遍历整个列表:
for i in list1: print(i)
squares = [value**2 for value in range(1,11)]
复制列表:
list2 = listt1[:]
代码格式:建议每行不超过79个字符
协作编写程序时,大多数编辑器中都可设置一个视觉标志--通常是一条竖线。
if语句:
if-elif-else结构,有一个测试满足条件后,就会跳过余下的测试。
if if if 就可以测试多个条件。
如果只想执行一个代码块,就是用 if-elif-else 结构,如果要运行多个代码块,就使 用一系列独立的if语句。
字典:
字典是一系列键-值对。每个键都与一个值相关联,可以使用键来访问与之相关联的 值。与键相关联的值可以是数字、字符串、列表乃至字典。事实上,可将任何python对象用作字典中的值。
注意,键-值对的排列顺序与添加顺序不同,python不关心键-值对的添加顺序,只关 心键和值之间的关联关系。
删除键值对:
alien={'color':'green','point':5}
del alien['point']
将键'point'从字典alien中删除,同时删除与这个键相关联的值。其他键值对不受影响
遍历键值对:
dict = {'name':'John','age':18}
for key,value in dict.items():
print(key,value)
注意,即便遍历字典时,键值对的返回顺序也与存储顺序不同。
遍历字典中所有键: dict.keys(),返回一个列表,其中包含字典中所有键。
按顺序遍历字典中所有键:for i in sorted(dict.keys())
遍历字典中所有值: dict.values(),返回一个列表,其中包含字典中所有值。这个方法没有考 虑重复,可以使用set(集合)剔除重复元素。
嵌套:
在列表中嵌套字典
alien_0 = {'color','green','point':'5'}
alien_1 = {'color','yellow','point':'10'}
alien_2 = {'color','red','point':'2'}
alien = [alien_0,alien_1,alien_2]
在字典中嵌套列表
dict2 = {'name':'Jerry','hobby': [basketball,dance] }
在字典中嵌套字典

用户输入input():
程序等待用户输入,并在用户按回车键后继续运行。
提示超过一行的话:可先将提示存储在一个变量中,再将该变量传递给函数input()
prompt = 'hello'
promt += '\nwhat is your name'
name = input(prompt)
while循环:
使用标志:在要求很多条件都满足才继续运行的程序中,可定义一个变量,用于判断整个程序是否处于活动状态。这个变量称为标志,充当了程序的交通信号灯。这样,在while语句中就只需检查一个条件---标志的当前值是否为true,并将所有测试都放在其他地方,从而让程序变得更加整洁。
break不再运行循环中余下的代码直接退出循环。
continue返回到循环开头,并根据条件测试结果决定是否继续执行循环。
while循环来处理列表:
在列表之间移动元素:
unconfirmed_users = ['alice','brain','candance'] confirmed_users = [] while unconfirmed_users: current_user = unconfirmed_users.pop() confirmed_users.append(current_user) print('unconfirmed_users:',unconfirmed_users) print('confirmed_users:',confirmed_users)
删除包含特定值的所有元素列表:
pets = ['dog','cat','dog','goldfish','cat','rabbit','cat'] print(pets) while 'cat' in pets: pets.remove('cat') print(pets)
while循环-使用用户输入来填充字典:
responses = {} pooling_active = True while pooling_active: name = input('What is your name? ') response = input('How old are you? ') responses[name] = response repeat = input('Would you like to let another person respond?(yes/no) ') if repeat == 'no': pooling_active = False # for name,response in responses.items(): # print(name,response) responses



函数:
形参:函数完成其工作所需的一项信息。
实参:调用函数时传递给函数的信息。
传递实参(可混用位置实参、关键字实参和默认值):
1、位置实参:要求实参的顺序与形参的顺序相同。
2、关键字实参:要求每个实参都由变量名和值组成,无需考虑函数调用中的实参顺 序,还清楚地指出了函数调用中各个值的用途。
注意,使用关键字实参时,务必准确地指定函数定义中的形参名。
3、编写函数时,可给每个形参指定默认值。使用默认值时,在形参列表中必须先列 出没有默认值的形参,再列出有默认值的实参。这让python依然能够正确地解读位置 实参。
返回值:return语句,调用返回值的函数时,需要提供一个变量,用于存储返回的 值。
让实参变成可选的:给可选的实参指定默认值--空字符串,将其移到形参列表的末 尾。
def get_formatted_name(first_name, last_name, middle_name=''): if middle_name: full_name = first_name + '' + middle_name + '' + last_name else: full_name = first_name + '' + last_name return full_name.title() musician = get_formatted_name('jimi','hendrix') print(musician) musician1 = get_formatted_name('john','hooker','lee') print(musician1)
如果想要禁止函数修改列表(参数是列表),可以将列表的副本(list1[:])传递给函数。这样函数所做的任何修改都只影响副本。
虽然向函数传递列表的副本可以保留原始列表的内容,但除非有充分的理由需要传递副本,否则还是应该将原始列表传递给函数,因为让函数使用现成列表可以避免花费时间和内存创建副本,从而提高效率,在处理大型列表时尤其如此。
传递任意数量的实参:
形参名*toppings中的星号让python创建一个名为toppings的空元祖,并将收到的所有值都封装到这个元组中。注意,python将实参封装到一个元组中,即便函数只收到一个值也是如此。
def make_pazza(*toppings): print(toppings) make_pazza('pepperoni') make_pazza('mushrooms','green peppers','extra cheese')
结合使用位置实参和任意数量的实参
使用任意数量的关键字实参
函数build_profile()的定义要求提供名和姓,同时允许用户根据需要提供任意数量的名称-值对。形参**user_info中的两个星号让python创建一个名为user_info的空字典,并将收到的所有名称-值对都封装到这个字典中。在这个函数中,可以像访问其他字典那样访问user_info中的名称-值对。
def build_profile(first,last,**user_info): profile = {} profile['first_name'] = first profile['last_name'] = last for key,value in user_info.items(): profile[key] = value return profile user_profile = build_profile('albert','einstein',location = 'princeton',field='physics') print(user_profile)
函数编写指南:
给形参指定默认值时,等号两边不要有空格
对于函数调用中的关键字实参,也应遵循这种约定。

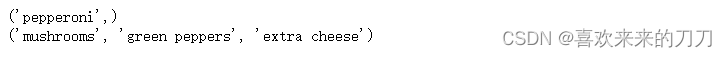
类:
面向对象编程中,你编写表示现实世界中的事物和情景的类,并基于这些类来创建对象。编写类时,你定义一大类都有的通用行为。基于类创建对象时,每个对象都自动具备这种通用行为,然后可根据需要赋予每个对象独特的个性。根据类来创建对象被称为实例化,这让你能够使用类的实例。
创建Dog类:
它表示的不是简单的小狗,而是任何小狗,每个狗都有名字和年龄,只有宠物狗会蹲下和打滚。根据约定,在python中,首字母大写的名称指的是类,在这个类定义中的括号是空的,因为我们要从空白创建这个类。
class Dog(): def __init__(self,name,age): self.name = name self.age = age def sit(self): print(self.name.title() + 'is now sitting.') def roll_over(self): print(self.name.title() + 'rolled over!')类中的函数称为方法。__init__()是一个特殊的方法,每当你根据Dog类创建新实例时,python都会自动运行它。形参self必不可少,还必须位于其他形参的前面。每个与类相关联的方法调用都自动传递实参self,它是一个指向实例本身的引用,让实例能够访问类中的属性和方法。每当我们根据Dog类创建实例时,都只需给最后两个形参(name和age)提供值。
以self为前缀的变量都可供类中的所有方法使用,还可以通过类的任何实例来访问这些变量。self.name = name获取存储在形参name中的值,并将其存储到变量name中,然后该变量被关联到当前创建的实例。像这样可通过实例访问的变量称为属性。
根据类创建实例:
可以将类视为有关如何创建实例的说明。Dog类是一系列说明,让python知道如何创建表示特定小狗的实例。下面来创建一个表示特定小狗的实例:
my_dog = Dog('willie',6) print(my_dog.name.title()) print(my_dog.age)
遇到这行代码时,python使用'willie'和6调用Dog类中的方法__init__(),方法__init__()创建一个表示特定小狗的示例,并使用我们提供的值来设置属性name和age。方法__init__()并未显式地包含return语句,但python自动返回一个表示这条小狗的实例。我们将这个实例存储在变量my_dog中。
在这里,命名约定很有用:我们通常可以认为首字母大写的名称(如Dog)指的是类,而小写的名称(如my_dog)指的是根据类创建的实例。
1、访问属性:
要访问实例的属性,可使用句点表示法。my_dog.age,在这里,python先找到实例my_dog,再查找与这个实例相关联的属性age。在Dog类中引用这个属性时,使用的是self.name。
2、调用方法
根据Dog类创建实例后,就可以使用句点表示法来调用Dog类中定义的任何方法。要调用方法,可指定实例的名称(如my_dog)和要调用的方法,并用句点分隔他们。遇到代码my_dog.sit()时,python在类Dog中查找方法sit()并运行其代码。
3、创建多个实例
可按需求根据类创建任意数量的实例,条件是将每个实例都存储在不同的变量中,或占用列表或字典不同的位置。
使用类和实例
给属性设定默认值
- class Car():
- def __init__(self,make,model,year):
- self.make = make
- self.model = model
- self.year = year
- self.odometer_reading = 0
- def read_odometer(self):
- return self.odometer_reading
- my_new_car = Car('audi','a4',2016)
- my_new_car.read_odometer()
修改属性的值
1、直接修改属性的值
要修改属性的值,最简单的方式是通过实例直接访问它。
2、通过方法修改属性的值
- class Car():
- def __init__(self,make,model,year):
- self.make = make
- self.model = model
- self.year = year
- self.odometer_reading = 0
- def read_odometer(self):
- return self.odometer_reading
- def update_odometer(self,mileage):
- self.odometer_reading = mileage
- my_new_car = Car('audi','a4',2016)
- my_new_car.update_odometer(23)
- my_new_car.read_odometer()
out: 23
3、通过方法对属性的值进行递增
- class Car():
- def __init__(self,make,model,year):
- self.make = make
- self.model = model
- self.year = year
- self.odometer_reading = 10
- def read_odometer(self):
- return self.odometer_reading
- def increment_odometer(self,miles):
- self.odometer_reading += miles
- my_new_car = Car('audi','a4',2016)
- my_new_car.increment_odometer(100)
- my_new_car.read_odometer()
out: 110
继承:
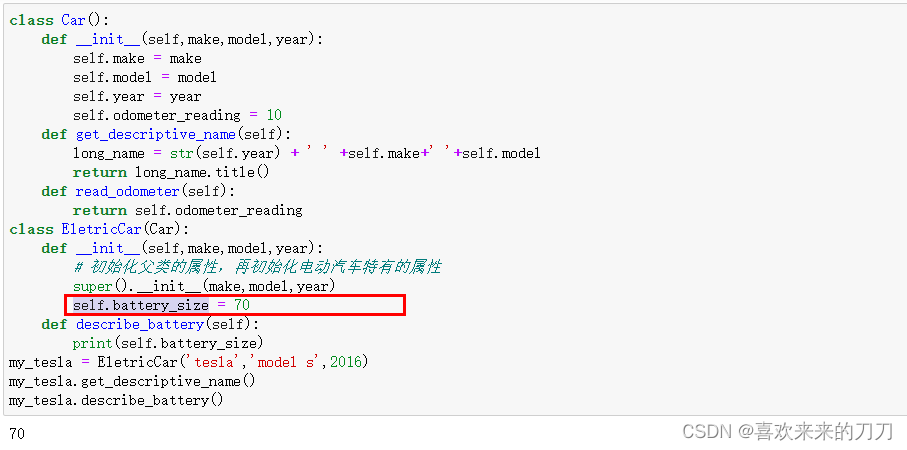
一个类继承另一个类时,它将自动获得另一个类的所有属性和方法,原有的类称为父类,而新类称为子类。子类继承了其父类的所有属性和方法,同时还可以定义自己的属性和方法。
创建子类的实例时,python首先需要完成的任务是给父类的所有属性赋值。为此,子类的方法__init__()需要父类施以援手。创建子类时,父类必须包含在当前文件中,且位于子类前面。定义子类时,必须在括号内指定父类的名称。方法__init__()接受创建Car实例所需的信息。super()是一个特殊的函数,帮助python将父类和子类关联起来。这行代码让python调用ElectricCar的父类的方法__init__(),让ElectricCar实例包含父类的所有属性。父类也称为超类(superclass)。 my_tesla = EletricCar('tesla','model s',2016),这行代码调用 ElectricCar类中定义的方法__init__(),后者让python调用父类Car中定义的方法__init__()
给子类定义属性和方法:
让一个类继承另一个类之后,可添加区分子类和父类所需的新属性和新方法。
在下面代码里,我们添加了self.battery_size,并设置其初始值70,根据ElectricCar类创建的所有实例都将包含这个属性,但所有Car实例都不包括它。对于ElectricCar类的特殊化程度没有任何限制,可以根据所需的准确程度添加任意数量的属性和方法。
重写父类的方法:
对于父类的方法,只要它不符合子类模拟的实物的行为,都可对其进行重写。为此,可以在子类中定义一个这样的方法,即它与要重写的父类方法同名。如果有人对电动汽车调用这个重写的方法,python将忽略Car类中的方法,转而运行电动汽车类里面的代码。使用继承时,可让子类保留从父类那里继承来的精华,并剔除不需要的糟粕。
将实例用作属性:
使用代码模拟实物时,你可能会发现自己给类添加的细节越来越多:属性和方法清单以及文件都越来越长,这时候可能就需要将类的一部分作为一个独立的类提取出来。你可以将大型类拆分成多个协同工作的小类。
首先我们定义了一个名为Battery的新类,它没有继承任何类。在ElectricCar类中,我们添加了一个名为self.battery的属性,这行代码让python创建一个新的Battery实例(由于没有指定尺寸,因此默认值为70),并将该实例存储在属性self.battery中。每当方法__init__()被调用时,都将执行该操作;因此现在每个ElectricCar实例都包含一个自动创建的Battery实例。
python标准库--有序字典
类的编码风格:
类名应该采用驼峰命名法,即将类名中的每个单词的首字母都大写,而不使用下划线。实例名和模块名都采用小写格式,并在单词之间加上下划线。
对于每个类,都应紧跟 在类定义后面 包含一个文档字符串,这种文档字符串简要地描述类的功能,并遵循编写函数的文档字符串时采用的格式约定(三引号)。每个模块也都应包含一个文档字符串,对其中的类可用于做什么进行描述。
可使用空行来组织代码,但不要滥用。在类中,可以使用一个空行来分隔方法;而在模块中,可使用两个空行来分隔类。
需要同时导入标准库中的模块和你编写的模块时,先编写导入标准库模块的import语句,再添加一个空行,然后编写导入你自己编写的模块的import语句。在包含多条import语句的程序中,这种做法让人很容易明白程序使用的各个模块都来自何方。







文件:
with open('xiyouji.txt') as file_object: contents = file_object.read() print(contents)
函数open()打开文件,它接受一个参数:要打开的文件的名称,python在当前执行的文件所在的目录中查找指定的文件,函数open()返回一个表示文件的对象。
有空白行是因为read()到达文件末尾时返回一个空字符串,而将这个空字符串显示出来就是一个空行。要消除空白行,可在print语句中使用rstrip()。
关键字with在不再需要访问文件后将其关闭。当然也可以调用open()和close()来打开和关闭文件,但这样做时,如果程序存在bug,导致close()语句未执行,文件将不会关闭。这看似微不足道,但未妥善地关闭文件可能会导致数据丢失或受损。如果在程序中过早地调用close(0,你会发现需要使用文件时它已关闭(无法访问),这会导致更多的错误。并非在任何情况下都能轻松确定关闭文件的恰当时机,但通过使用前面所示的结构,可以让python去确定:你只管打开文件,并在需要时使用它,python自会在合适的时候自动将其关闭。
使用read()读取文件的全部内容,并将其作为一个长长的字符串存储在变量contents中。
文件路径有相对路径和绝对路径两种,文件路径中使用反斜杠(\),绝对路径通常比相对路径长,因此将其存储在一个变量中,再将该变量传递给open()函数,通常使用绝对路径,可读取系统任何地方的文件。
逐行读取--for循环:
变量filename表示的并非实际文件--他只是一个让python知道到哪里去查找文件的字符串,调用open后,将一个表示文件及其内容的对象存储到了变量file_object中,这里也使用了关键字with,让python负责妥善地打开和关闭文件。
出现空白行的原因:因为在这个文件中,每行的末尾都有一个看不见的换行符,而print语句也会加上一个换行符,因此每行末尾都有两个换行符:一个来自文件,一个来自print语句。要消除这些空白行,可在print语句中使用rstrip()。
filename = 'pi_digits.txt' with open(filename) as file_object: for line in file_object: print(line)
使用关键字with时,open()返回的文件对象只在with代码块内可用,如果要在with代码块外访问文件的内容,可以在with代码块内将文件的各行存储在一个列表中,并在with代码块外使用该列表。
filename = 'pi_digits.txt' with open(filename) as file_object: lines = file_object.readlines() pi_string = '' for line in lines: pi_string += line.strip() print(pi_string)
注意,读取文本文件时,python将其中所有文本都解读为字符串。如果读取的是数字,并要将其作为数值使用,就必须使用函数int()将其转换为整数,或使用函数float()将其转换为浮点数。
写入文件:
filename = 'pi_digits.txt' with open(filename,'w') as file_object: file_object.write('I love writting')调用open()时提供了两个实参,第一个实参就是要打开的文件的名称,第二个实参w告诉python,我们要以写入模式打开这个文件。打开文件时,可指定读取模式('r'),写入模式('w'),附加模式('a')(在文件末尾添加内容)或能够读取和写入文件的模式('r+')。如果你忽略了模式实参,python将以默认的只读模式打开文件。
如果你要写入的文件不存在,那么open()将会自动创建它。然而,以写入模式打开文件时千万要小心,因为如果指定的文件已存在,python将在返回文件对象前清空该文件。
使用文件对象的方法write()将一个字符串写入文件。这个程序没有终端输出,只能打开txt文件去看。
python只能将字符串写入文本文件。要将数值数据存储到文本文件中,必须先使用函数str()将其转换为字符串格式。


异常:
python使用被称为异常的特殊对象来管理程序执行期间发生的错误。每当发生让python不知所措的错误时,它都会创建一个异常对象。如果你编写了处理该异常的代码,程序将继续运行;如果你未对异常处理,程序将终止,并显示一个traceback,其中包含有关异常的报告。
异常是使用try-except代码块处理的。try-except代码块让python执行指定的操作,同时告诉python发生异常怎么办。使用try-except代码块时,即便出现异常,程序也将继续运行:显示你编写的友好的错误信息,而不是令用户迷惑的traceback。
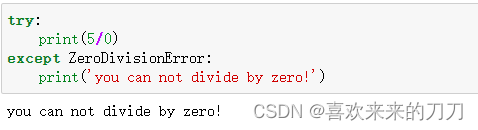
1、ZeroDivisionError异常
下面代码指出的错误ZeroDivisionError是一个异常对象,python无法按照你的要求做时,就会创建这种对象。在这种情况下,python将停止运行程序,并指出引发了哪种异常,我们可以根据这些信息对程序进行修改。
使用try-except代码块
如果try代码块中的代码运行起来没有问题,python将跳过except代码块;如果try代码块中的代码导致了错误,python将查找这样的except代码块,并运行其中的代码,即其中指定的错误与引发的错误相同。
使用异常避免崩溃
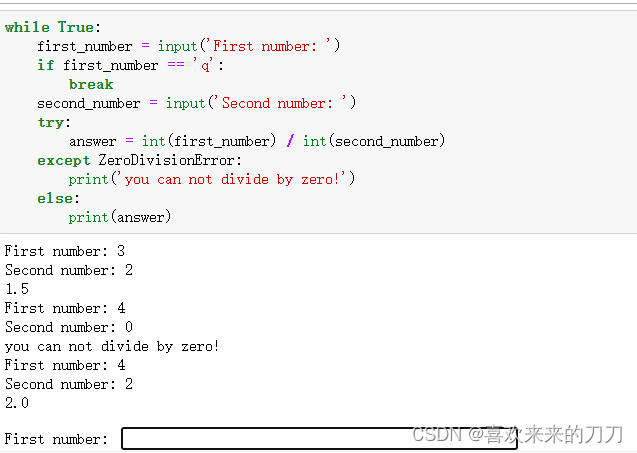
发生错误时,如果程序还有工作没有完成,妥善地处理错误就尤其重要。这种情况经常会出现在 要求用户提供输入的程序中,如果程序能妥善地处理无效输入,就能再提示用户提供有效输入,而不至于崩溃。
else代码块:
通过将可能引发错误的代码放在try--except代码块中,可提高这个程序抵御错误的能力。依赖于try代码块成功执行的代码都应放到else代码块中。在这个例子中,如果除法运算成功,我们就使用else代码块来打印结果。
except代码块告诉python,出现ZeroDivisionError异常时该怎么办,如果try代码块因除0错误而失败,我们就打印出一条友好的消息,告诉用户如何避免这种错误。程序将继续运行,用户根本看不到traceback。
try-except-else代码块的工作原理大致如下:python尝试执行try代码块中的代码,只有可能引发异常的代码才需要放在try语句中。有时候,有一些仅在try代码块成功执行时才需要运行的代码,这些代码应放在else代码块中。except代码块告诉python,如果它尝试运行try代码块中的代码引发了指定的异常,该怎么办。
通过预测可能发生错误的代码,可编写健壮的程序,它们即便面临无效数据或缺少资源,也能继续运行,从而能够抵御无意的用户错误和恶意的攻击。
2、FileNotFoundError异常
这个错误是函数open()导致的,因此要处理这个错误,必须将try语句放在包含open()的代码行之前:
分析文本:
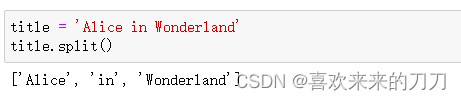
方法split()以空格为分隔符将字符串分拆成多个部分,并将这些部分都存储到一个列表中。
失败时一声不吭:
在except代码块中写pass语句。
存储数据:
使用json模块,模块json让你能够将简单的python数据结构转储到文件中,并在程序再次运行时加载该文件中的数据。还可以使用json在python之间分享数据。更重要的是,JSON数据格式并非python专用,这让你能够将以JSON格式存储的数据与使用其他编程语言的人分享。
存储 json.dump()和读取 json.load():
函数 json.dump() 接受两个实参:要存储的数据以及可用于存储数据的文件对象。通常使用文件扩展名.json来指出文件存储的数据为JSON格式。这个程序没有输出,我们可以打开文件number.json,看看其内容。
import json numbers = [1,2,3,4,5,6,7,8,8] filename = 'number.json' with open(filename,'w') as f_obj: json.dump(numbers,f_obj)
使用json.load()将这个列表读取到内存中:
保存和读取用户生成的数据:
我们提示输入用户名,并将其存储在一个变量中。调用json.dump(),将用户名存储到文件中。
再编写一个程序,向其名字被存储的用户发出问候:
将这两个程序合并为一个:
重构:
经常会遇到一种情况:代码能够正常运行,但可做进一步的改进--将代码划分为一系列完成具体工作的函数。这样的过程被称为重构。重构让代码更清晰、更易于理解、更容易扩展。
我们可以看到上面代码重点是问候用户,因此我们把所有代码放在一个名为greet_user()的函数中:
函数greet_user()所做的不仅仅是问候用户,还在存储了用户名时获取它,而在没有存储用户名时提示用户输入一个,接下来我们重构greet_user(),让它不执行这么多任务:
新增的函数get_stored_username()目标明确,如果存储了用户名,这个函数就获取并返回它;如果文件username.json不存在,这个函数就返回None。这是一种不错的做法:函数要么返回预期的值,要么返回None;这让我们能够使用函数的返回值做简单测试。
我们还需将greet_user()中的另一个代码块提取出来:将没有存储用户名时提示用户输入的代码放在一个独立的函数中:
import json def get_stored_username(): """如果存储了用户名,就获取它""" try: with open(filename) as f_obj: username = json.load(f_obj) except FileNotFoundError: return None else: return username def get_new_name(): """提示用户输入用户名""" filename = 'username.json' username = input('What is your name? ') with open(filename,'w') as f_obj: json.dump(username,f_obj) return username def greet_user(): """问候用户,并指出其名字""" username = get_stored_username() if username: print('Welcome back, '+ username +' !') else: username = get_new_name() print('We will remember you, '+ username +' !') greet_user()在最终版本中,每个函数都执行单一而清晰的任务。我们调用greet_user(),它打印一条合适的消息:要么欢迎老用户回来,要么问候新用户。为此,它首先调用get_stored_username(),这个函数只负责获取存储的用户名(如果存储了的话),再在必要时调用get_new_name(),这个函数只负责获取并存储新用户的用户名。要编写出清晰而易于维护和扩展的代码,这种划分工作必不可少。












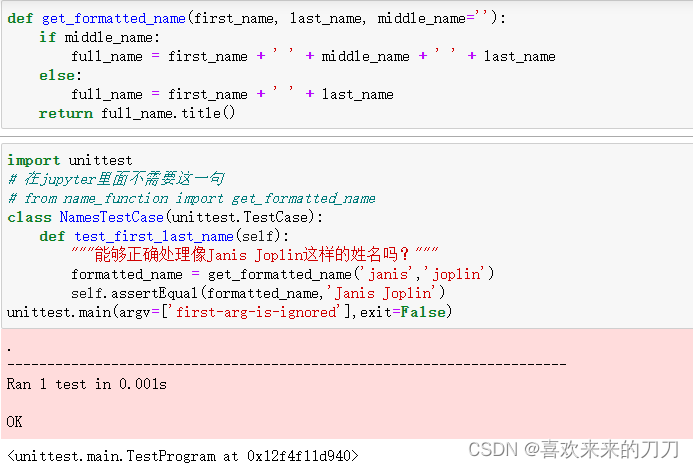
测试代码------使用python模块unittest:
要测试的代码如下 name_function.py:
def get_formatted_name(first_name, last_name): """Generate a neatly formatted full name""" full_name = first_name + ' ' + last_name return full_name.title()函数get_formatted_name()将名和姓合并成姓名,在名和姓之间加上一个空格,并将它们首字母大写,再返回结果。
单元测试用于核实函数的某个方面没有问题,测试用例是一组单元测试,这些单元测试一起核实函数在各种情形下的行为都符合要求。良好的测试用例考虑到了函数可能收到的各种输入,包含针对所有这些情形的测试。全覆盖式测试用例包含一整套单元测试,涵盖了各种可能的函数使用方式。
要为函数编写测试用例,可先导入模块unittest以及要测试的函数,再创建一个继承unittest.TestCase的类,并编写一系列方法对函数行为的不同方面进行测试。
下面是只包含一个方法的测试用例 test_name_function.py,它检查函数get_formatted_name()在给定名和姓时能否正确的工作:
你可以随便给这个类命名,但最好让它看起来与要测试的函数相关,并包含字样Test。这个类必须继承unittest.TestCase类,这样python才知道如何运行你编写的测试。
我们运行test_name_function.py时,所有以test_打头的方法都将自动运行。
断言方法用来核实得到的结果是否与期望的结果一致。我们调用unittest的方法assertEqual(),并向它传递参数。代码行self.assertEqual(formatted_name,'Janis Joplin')意思是说:将'formatted_name'的值同字符串'Janis Joplin'进行比较,若相等就万事大吉,不相等就返回错误。
代码行unittest.main(argv=['first-arg-is-ignored'],exit=False)让python运行这个文件中的测试。
第1行的句点表明有一个测试通过了。接下来的一行指出python运行了一个测试,消耗的时间不到0.001秒。最后的OK表明该测试用例中的所有单元测试都通过了。
不能通过的测试:
下面是get_formatted_name()的新版本,它要求通过一个实参指定中间名:
测试未通过怎么办?
测试未通过时,不要修改测试,而应该修复导致测试不能通过的代码:检查刚对函数所做的修改,找出导致函数行为不符合预期的修改。
修改代码,将middle_name设为可选的:
现在,测试用例通过了。
添加新测试--用于测试包含中间名的姓名:
方法名(test_first_last_middle_name())必须以test_打头,这样它才会在我们运行test_name_function.py时自动运行。在TestCase类中使用很长的方法名是可以的,这些方法的名称必须是描述性的,这才能让你明白测试未通过时的输出,这些方法由python自动调用,你根本不用编写调用它们的代码。
测试类:
下面表描述了6个常用的断言方法。使用这些方法可以核实返回的值等于或不等于预期的值、返回的值为True或False、返回的值是否在列表中。你只能在继承unittest.TestCase的类中使用这些方法。
各种断言方法 方法 用途 assertEqual(a,b) 核实 a==b assertNotEqual(a,b) 核实 a!=b assertTrue(x) 核实 x为True assertFalse(x) 核实 x为False assertIn(item,list) 核实 item在list中 assertNotIn(item,list) 核实 item不在list中




方法setUp():
unittest.TestCase类中包含方法setUp(),让我们只需要创建这些对象一次,再运行各个以test_打头的方法。这样,在你编写的每个测试方法中都可使用在方法setUp()中创建的对象了。
方法setUp()创建的变量名前面都含有前缀self,因此可在这个类中的任何地方使用。
运行测试用例时,每完成一个单元测试,python都打印一个字符:测试通过时打印一个句点;测试引发错误时打印一个E;测试导致断言失败时打印一个F。如果测试用例包含很多单元测试,需要运行很长时间,就可通过观察这些结果来获悉有多少个测试通过了。















 1269
1269











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









