






codecs模块是Python标准库中的一个模块,它提供了对文本进行编码和解码的功能。python对多国语言的处理是支持的很好的,它可以处理现在任意编码的字符,这里深入的研究一下python对多种不同语言的处理。当python要做编码转换的时候,会借助于内部的编码,转换过程是这样的:原有编码 -> 内部编码 -> 目的编码。如下图
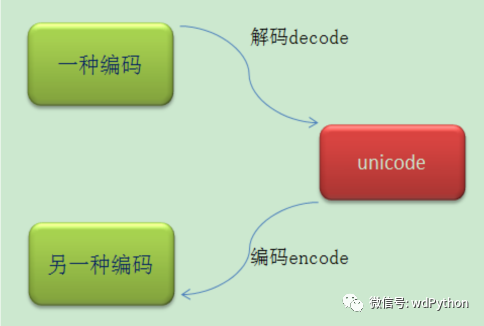
python的内部是使用unicode来处理的,但是unicode的使用需要考虑的是它的编码格式有两种,一是UCS-2,它一共有65536个码 位,另一种是UCS-4,它有2147483648g个码位。对于这两种格式,python都是支持的,这个是在编译时通过–enable- unicode=ucs2或–enable-unicode=ucs4来指定的。那么我们自己默认安装的python有的什么编码怎么来确定呢?可以通过sys.maxunicode的值来判断:
import sys
print(sys.maxunicode)
# 我的输出1114111
如果输出的值为65535,那么就是UCS-2,如果输出是1114111就是UCS-4编码。我们要认识到一点:当一个字符串转换为内部编码后,它就不是str类型了!它是unicode类型
codecs模块还有哪些功能?
**1.查找字符编码的对应关系:**codecs模块提供了lookup方法,可以查找字符编码的对应关系,lookup函数返回一个包含4个元素的元组,其中look[0]是encoder的函数引用,look[1]是decoder的函数引用,look[2] 是UTF-8编码方式的StreamReader类对象引用,look[3]是UTF-8编码方式的StreamWriter类对象引用。
# @Author : 小红牛
# 微信公众号:编程IT资料库
import codecs
# 查找'utf-8'编码的对应关系
look = codecs.lookup('utf-8')
print(look)
# 打印编码名称,解码器函数,编码器函数
print('编码名称:', look.name)
print('编码器函数:', look[0], look.encode)
print('解码器函数:', look[1], look.decode)
print('StreamReader类:', look[3])
print('StreamWriter类:', look[3])
输出以下内容
<codecs.CodecInfo object for encoding utf-8 at 0x1ff2c165f00>
编码名称: utf-8
编码器函数: <built-in function utf_8_encode> <built-in function utf_8_encode>
解码器函数: <function decode at 0x000001FF2C1F5C60> <function decode at 0x000001FF2C1F5C60>
StreamReader类:<class 'encodings.utf_8.StreamWriter'>
StreamWriter类:<class 'encodings.utf_8.StreamWriter'>
**2.对文本进行编码+解码操作:**使用codecs模块的函数可以将文本从一个编码方式转换为另一个编码方式。例如,可以使用codecs.decode()函数将UTF-8编码的文本转换为Unicode编码的文本。
import codecs
str = '微信公众号:wdPython'
print('1.字符串编码'.center(50,'-'))
print(str.encode('gbk'))
print(str.encode('gb2312'))
print(str.encode('utf-8'))
print('2.codecs模块编码'.center(50,'-'))
# 创建gb2312,utf-8编码
code_gb2312 = codecs.lookup('gb2312')
code_gbk= codecs.lookup('gbk')
code_utf_8 = codecs.lookup('utf-8')
print(code_gb2312.encode(str))
print(code_gbk.encode(str))
print(code_utf_8.encode(str))
print('3.decode解码code_utf_8[0]'.center(50,'-'))
# code_utf_8.encode(str)[0]是unicode数据,code_utf_8.encode(str)[1]是长度
encode_str = code_utf_8.decode(code_utf_8.encode(str)[0])
# 解码后的字符串是一个tuple类型
print(encode_str[0], encode_str[1], type(encode_str))
输出结果
---------------------1.字符串编码----------------------
b'\xce\xa2\xd0\xc5\xb9\xab\xd6\xda\xba\xc5\xa3\xbawdPython'
b'\xce\xa2\xd0\xc5\xb9\xab\xd6\xda\xba\xc5\xa3\xbawdPython'
b'\xe5\xbe\xae\xe4\xbf\xa1\xe5\x85\xac\xe4\xbc\x97\xe5\x8f\xb7\xef\xbc\x9awdPython'
-------------------2.codecs模块编码-------------------
(b'\xce\xa2\xd0\xc5\xb9\xab\xd6\xda\xba\xc5\xa3\xbawdPython', 14)
(b'\xce\xa2\xd0\xc5\xb9\xab\xd6\xda\xba\xc5\xa3\xbawdPython', 14)
(b'\xe5\xbe\xae\xe4\xbf\xa1\xe5\x85\xac\xe4\xbc\x97\xe5\x8f\xb7\xef\xbc\x9awdPython', 14)
-------------3.decode解码code_utf_8[0]--------------
微信公众号:wdPython 26 <class 'tuple'>
通过对比str.encode(‘gbk’)和codecs.lookup(‘gbk’),上面的输出结果,可以看到他们编码后的结果是一样的。解码和编码返回后的结果都是元组类型。
为了方便程序员使用的单独函数,以简化对lookup的调用,也可以这样操作编码+解码。与上面的操作结果是一样的。
getencoder(encoding):用于将字符串编码为字节
import codecs
# 获取utf-8编码的encoder方法
encoder = codecs.getencoder("utf-8")
# 使用encoder方法将字符串编码为utf-8格式的字节串
str = "微信公众号:编程IT资料库"
bytes = encoder(str)[0]
print(bytes)
# 输出:b'\xe5\xbe\xae\xe4\xbf\xa1\xe5\x85\xac\xe4\xbc\x97\xe5\x8f\xb7\xef\xbc\x9awdPython'
getdecoder(encoding):用于将字节解码为字符串。
import codecs
# 获取utf-8编码的decoder方法
decoder = codecs.getdecoder("utf-8")
# 使用decoder方法将utf-8格式的字节串解码为字符串
bytes = b'\xe5\xbe\xae\xe4\xbf\xa1\xe5\x85\xac\xe4\xbc\x97\xe5\x8f\xb7\xef\xbc\x9awdPython'
str = decoder(bytes)[0]
print(str) # 输出:微信公众号:编程IT资料库
getreader(encoding):此方法返回一个关联的读取器对象,该对象使用指定的编码方式从流中读取数据。
import codecs
# 获取utf-8编码的reader方法
reader = codecs.getreader('utf-8')
# 使用reader方法读取文件内容并解码为字符串
with open('李白.txt', "rb") as f:
content = reader(f).read()
print(content) # 输出文件内容的字符串形式
也可以使用codecs.open读数据
import codecs
f = codecs.open("李白.txt", "r", "utf-8")
print(f.read())
f.close()
getwriter(encoding):此方法返回一个关联的写入器对象,该对象使用指定的编码方式向流中写入数据。
import codecs
# 获取utf-8编码的writer方法
writer = codecs.getwriter('utf-8')
content = '''将进酒
李白〔唐代〕
君不见黄河之水天上来,奔流到海不复回。
君不见高堂明镜悲白发,朝如青丝暮成雪。
人生得意须尽欢,莫使金樽空对月。'''
# 使用writer方法将字符串编码为utf-8格式并写入文件
with open('李白.txt', "wb") as f:
writer(f).write(content)
f.close()
codecs.open写数据
import codecs
content = '''将进酒
李白〔唐代〕
君不见黄河之水天上来,奔流到海不复回。
君不见高堂明镜悲白发,朝如青丝暮成雪。
人生得意须尽欢,莫使金樽空对月。'''
f = codecs.open("李白.txt", "w", "utf-8")
f.write(content)
f.close()
3.处理Unicode编码的异常:使用codecs模块可以捕获和处理Unicode编码的异常,例如UnicodeDecodeError等。例如,可以使用codecs.open()函数的errors参数来指定如何处理Unicode编码的异常。原本李白.txt格式为utf-8,我用big5去解码,肯定会报错,目的是为了演示报错的原因。
import codecs
try:
# 尝试打开一个文件,并使用指定的编码方式读取内容
with codecs.open('李白.txt', 'r', encoding='big5') as f:
content = f.read()
except UnicodeDecodeError as e:
# 如果遇到Unicode解码错误,则打印错误信息并采取适当的处理措施
print("Unicode解码错误:", e)
content = None
if content is not None:
print("文件内容:", content)
# 输出,Unicode解码错误: 'big5' codec can't decode byte 0x92 in position 8: illegal multibyte sequence
感兴趣的小伙伴,赠送全套Python学习资料,包含面试题、简历资料等具体看下方。

一、Python所有方向的学习路线
Python所有方向的技术点做的整理,形成各个领域的知识点汇总,它的用处就在于,你可以按照下面的知识点去找对应的学习资源,保证自己学得较为全面。


二、Python必备开发工具
工具都帮大家整理好了,安装就可直接上手!
三、最新Python学习笔记
当我学到一定基础,有自己的理解能力的时候,会去阅读一些前辈整理的书籍或者手写的笔记资料,这些笔记详细记载了他们对一些技术点的理解,这些理解是比较独到,可以学到不一样的思路。

四、Python视频合集
观看全面零基础学习视频,看视频学习是最快捷也是最有效果的方式,跟着视频中老师的思路,从基础到深入,还是很容易入门的。

五、实战案例
纸上得来终觉浅,要学会跟着视频一起敲,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。

六、面试宝典


简历模板
若有侵权,请联系删除















 2506
2506











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









