







SQL学习四-聚集函数
数据准备
原始数据:
| ID | NAME | CLASSID |
|---|---|---|
| 1 | xiaoming | 1 |
| 2 | xiaowang | 1 |
| 3 | xiaotian | 2 |
| 4 | xiaoming | 2 |
| 5 | xiaowang | 3 |
| 6 | xiaotian | 4 |
此外,还将往表中插入多条数据以满足学习聚合函数需要
插入数据如下:
| ID | NAME | CLASSID |
|---|---|---|
| 7 | xiaogang | 1 |
| 8 | xiaoqiang | 1 |
| 9 | xiaojing | 2 |
| 10 | xiaotie | 2 |
| 11 | wangqiang | 3 |
| 12 | wangwei | 3 |
| 13 | liming | 4 |
| 14 | liqiang | 4 |
插入语句如下:
INSERT INTO Student
VALUES
(7, 'xiaogang', 1),
(8, 'xiaoqiang', 1),
(9, 'xiaojing', 2),
(10, 'xiaotie', 2),
(11, 'wangqiang', 3),
(12, 'wangwei', 3),
(13, 'liming', 4),
(14, 'liqiang', 4);
聚集函数种类
COUNT(): 计算总数
SUM(): 计算某分组的和
AVG(): 计算某分组的平均值
MAX():获取某分组的最大值
MIN(): 获取某分组的最小值
GROUP_CONCAT(), 按照分组,根据指定的属性进行拼接,然后添加到表的列中
COUNT
COUNT一般用于计数,中间可以放属性,放*,也可以放1等。
COUNT如果放属性,表示这个属性的行数,如果放1,可以理解成SQL语句在表中增加了tmp列,该列全部为1,然后计算1的个数,以上表为例:
COUNT(1):
| ID | NAME | CLASSID | tmp |
|---|---|---|---|
| 1 | xiaoming | 1 | 1 |
| 2 | xiaowang | 1 | 1 |
| 3 | xiaotian | 2 | 1 |
| 4 | xiaoming | 2 | 1 |
| 5 | xiaowang | 3 | 1 |
| 6 | xiaotian | 4 | 1 |
| 7 | xiaogang | 1 | 1 |
| 8 | xiaoqiang | 1 | 1 |
| 9 | xiaojing | 2 | 1 |
| 10 | xiaotie | 2 | 1 |
| 11 | wangqiang | 3 | 1 |
| 12 | wangwei | 3 | 1 |
| 13 | liming | 4 | 1 |
| 14 | liqiang | 4 | 1 |
然后COUNT(1)就会计算tmp列中1的数量,然后再添加一个属性COUNT(1)到上面,这时,COUNT(1)的结果就是当前表中1的数量,结果如下:
| ID | NAME | CLASSID | tmp | COUNT(1) |
|---|---|---|---|---|
| 1 | xiaoming | 1 | 1 | 14 |
| 2 | xiaowang | 1 | 1 | 14 |
| 3 | xiaotian | 2 | 1 | 14 |
| 4 | xiaoming | 2 | 1 | 14 |
| 5 | xiaowang | 3 | 1 | 14 |
| 6 | xiaotian | 4 | 1 | 14 |
| 7 | xiaogang | 1 | 1 | 14 |
| 8 | xiaoqiang | 1 | 1 | 14 |
| 9 | xiaojing | 2 | 1 | 14 |
| 10 | xiaotie | 2 | 1 | 14 |
| 11 | wangqiang | 3 | 1 | 14 |
| 12 | wangwei | 3 | 1 | 14 |
| 13 | liming | 4 | 1 | 14 |
| 14 | liqiang | 4 | 1 | 14 |
这便是COUNT(1)处理的逻辑过程.
再结合上SQL语句,假设按照下面的查询语句查询,
SELECT COUNT(1), CLASSID FROM Student
WHERE ID % 2 = 0;
首先是FROM Student WHERE ID % 2 = 0;获取到的结果如下:
| ID | NAME | CLASSID |
|---|---|---|
| 2 | xiaowang | 1 |
| 4 | xiaoming | 2 |
| 6 | xiaotian | 4 |
| 8 | xiaoqiang | 1 |
| 10 | xiaotie | 2 |
| 12 | wangwei | 3 |
| 14 | liqiang | 4 |
然后按照COUNT(1)处理后的结果如下:
| ID | NAME | CLASSID | tmp | COUNT(1) |
|---|---|---|---|---|
| 2 | xiaowang | 1 | 1 | 7 |
| 4 | xiaoming | 2 | 1 | 7 |
| 6 | xiaotian | 4 | 1 | 7 |
| 8 | xiaoqiang | 1 | 1 | 7 |
| 10 | xiaotie | 2 | 1 | 7 |
| 12 | wangwei | 3 | 1 | 7 |
| 14 | liqiang | 4 | 1 | 7 |
由于查询的数据只有CLASSID和COUNT(1)两列
故结果如下:
| CLASSID | COUNT(1) |
|---|---|
| 1 | 7 |
| 2 | 7 |
| 4 | 7 |
| 1 | 7 |
| 2 | 7 |
| 3 | 7 |
| 4 | 7 |
在数据库上执行结果如下:
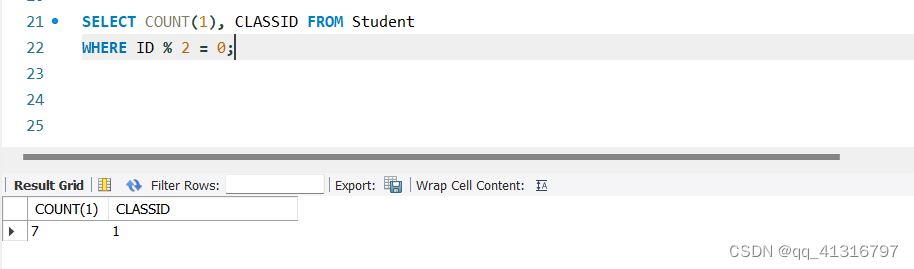
此时在结果上只展示了一条,这是为什么呢?我们接着往下看
GROUP BY + COUNT
在聚集函数一般与GROUP BY一起使用,如果没有使用GROUP BY,那么可以将当前表格中所有的数据看成一组(未分组就是一组),GROUP BY + SELECT只会保留每组中的第一条数据,上面实验中,由于有GROUP BY(没有使用GROUP BY相当于分组分成了一组)+ SELECT,故最终执行结果只有第一条数据。
从之前的结果中我们知道,GROUP BY有按照某个属性分组,相同属性分为一组,如果在实验表中按照CLASSID分组,我们的结果如下:
CLASSID = 1 组:
| ID | NAME | CLASSID |
|---|---|---|
| 1 | xiaoming | 1 |
| 2 | xiaowang | 1 |
| 7 | xiaogang | 1 |
| 8 | xiaoqiang | 1 |
CLASSID=2组:
| ID | NAME | CLASSID |
|---|---|---|
| 3 | xiaotian | 2 |
| 4 | xiaoming | 2 |
| 9 | xiaojing | 2 |
| 10 | xiaotie | 2 |
CLASSID=3组:
| ID | NAME | CLASSID |
|---|---|---|
| 5 | xiaowang | 3 |
| 11 | wangqiang | 3 |
| 12 | wangwei | 3 |
CLASSID=4组:
| ID | NAME | CLASSID |
|---|---|---|
| 6 | xiaotian | 4 |
| 13 | liming | 4 |
| 14 | liqiang | 4 |
按照上面的规则,如果加上一个COUNT(1)属性,相当于在每个分组的后面加上了tmp列,然后COUNT(1)相当于在后面再加一列,该列的值为当前组的1的数量(如果没有分组就相当于整个表中tmp=1的数量),结果如下:
CLASSID = 1 组:
| ID | NAME | CLASSID | tmp | COUNT(1) |
|---|---|---|---|---|
| 1 | xiaoming | 1 | 1 | 4 |
| 2 | xiaowang | 1 | 1 | 4 |
| 7 | xiaogang | 1 | 1 | 4 |
| 8 | xiaoqiang | 1 | 1 | 4 |
CLASSID=2组:
| ID | NAME | CLASSID | tmp | COUNT(1) |
|---|---|---|---|---|
| 3 | xiaotian | 2 | 1 | 4 |
| 4 | xiaoming | 2 | 1 | 4 |
| 9 | xiaojing | 2 | 1 | 4 |
| 10 | xiaotie | 2 | 1 | 4 |
CLASSID=3组:
| ID | NAME | CLASSID | tmp | COUNT(1) |
|---|---|---|---|---|
| 5 | xiaowang | 3 | 1 | 3 |
| 11 | wangqiang | 3 | 1 | 3 |
| 12 | wangwei | 3 | 1 | 3 |
CLASSID=4组:
| ID | NAME | CLASSID | tmp | COUNT(1) |
|---|---|---|---|---|
| 6 | xiaotian | 4 | 1 | 3 |
| 13 | liming | 4 | 1 | 3 |
| 14 | liqiang | 4 | 1 | 3 |
如果执行下面的SQL语句
SELECT COUNT(1), NAME, CLASSID
FROM Student
WHERE ID % 2 = 0
GROUP BY CLASSID;
则结果如下:
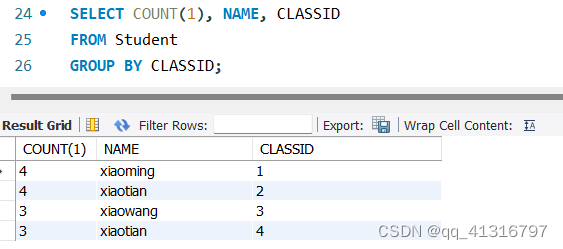
结果为上面四张表中每个表的第一行,取出COUNT(1),NAME, CLASSID的结果。
GROUP BY 后面还可以放多个属性,分组将按照这几个属性分,这几个属性相同的元素为一组,
GROUP_CONCAT
在聚集函数中,还有一个比较有意思的属性,GROUP_CONCAT,用于将同一个分组中每一行的几个属性拼接起来,通常和GROUP BY 一起使用。
如果不使用分组,那么表示当前表中所有的数据为一组,那么会在表中的每一列加上一个GROUP_CONCAT属性,行与行的拼接之间以逗号,分开,以下面的GROUP_CONCAT为例,该属性为拼接该表中所有的数据之后的结果如下:
GROUP_CONCAT(ID, '@', NAME, '@', CLASSID)
由于是聚合函数,同时也有分组,并且还和SELECT一起使用
以上面的SQL为例,加上GROUP_CONCAT函数之后的结果如下:
| ID | NAME | CLASSID | GROUP_CONCAT(ID, ‘@’, NAME, ‘@’, CLASSID) |
|---|---|---|---|
| 1 | xiaoming | 1 | 1@xiaoming@1,2@xiaowang@1,3@xiaotian@2,4@xiaoming@2,5@xiaowang@3,6@xiaotian@4,7@xiaogang@1,8@xiaoqiang@1,9@xiaojing@2,10@xiaotie@2,11@wangqiang@3,12@wangwei@3,13@liming@4,14@liqiang@4 |
| 2 | xiaowang | 1 | 1@xiaoming@1,2@xiaowang@1,3@xiaotian@2,4@xiaoming@2,5@xiaowang@3,6@xiaotian@4,7@xiaogang@1,8@xiaoqiang@1,9@xiaojing@2,10@xiaotie@2,11@wangqiang@3,12@wangwei@3,13@liming@4,14@liqiang@4 |
| 3 | xiaotian | 2 | 1@xiaoming@1,2@xiaowang@1,3@xiaotian@2,4@xiaoming@2,5@xiaowang@3,6@xiaotian@4,7@xiaogang@1,8@xiaoqiang@1,9@xiaojing@2,10@xiaotie@2,11@wangqiang@3,12@wangwei@3,13@liming@4,14@liqiang@4 |
| 4 | xiaoming | 2 | 1@xiaoming@1,2@xiaowang@1,3@xiaotian@2,4@xiaoming@2,5@xiaowang@3,6@xiaotian@4,7@xiaogang@1,8@xiaoqiang@1,9@xiaojing@2,10@xiaotie@2,11@wangqiang@3,12@wangwei@3,13@liming@4,14@liqiang@4 |
| 5 | xiaowang | 3 | 1@xiaoming@1,2@xiaowang@1,3@xiaotian@2,4@xiaoming@2,5@xiaowang@3,6@xiaotian@4,7@xiaogang@1,8@xiaoqiang@1,9@xiaojing@2,10@xiaotie@2,11@wangqiang@3,12@wangwei@3,13@liming@4,14@liqiang@4 |
| 6 | xiaotian | 4 | 1@xiaoming@1,2@xiaowang@1,3@xiaotian@2,4@xiaoming@2,5@xiaowang@3,6@xiaotian@4,7@xiaogang@1,8@xiaoqiang@1,9@xiaojing@2,10@xiaotie@2,11@wangqiang@3,12@wangwei@3,13@liming@4,14@liqiang@4 |
| 7 | xiaogang | 1 | 1@xiaoming@1,2@xiaowang@1,3@xiaotian@2,4@xiaoming@2,5@xiaowang@3,6@xiaotian@4,7@xiaogang@1,8@xiaoqiang@1,9@xiaojing@2,10@xiaotie@2,11@wangqiang@3,12@wangwei@3,13@liming@4,14@liqiang@4 |
| 8 | xiaoqiang | 1 | 1@xiaoming@1,2@xiaowang@1,3@xiaotian@2,4@xiaoming@2,5@xiaowang@3,6@xiaotian@4,7@xiaogang@1,8@xiaoqiang@1,9@xiaojing@2,10@xiaotie@2,11@wangqiang@3,12@wangwei@3,13@liming@4,14@liqiang@4 |
| 9 | xiaojing | 2 | 1@xiaoming@1,2@xiaowang@1,3@xiaotian@2,4@xiaoming@2,5@xiaowang@3,6@xiaotian@4,7@xiaogang@1,8@xiaoqiang@1,9@xiaojing@2,10@xiaotie@2,11@wangqiang@3,12@wangwei@3,13@liming@4,14@liqiang@4 |
| 10 | xiaotie | 2 | 1@xiaoming@1,2@xiaowang@1,3@xiaotian@2,4@xiaoming@2,5@xiaowang@3,6@xiaotian@4,7@xiaogang@1,8@xiaoqiang@1,9@xiaojing@2,10@xiaotie@2,11@wangqiang@3,12@wangwei@3,13@liming@4,14@liqiang@4 |
| 11 | wangqiang | 3 | 1@xiaoming@1,2@xiaowang@1,3@xiaotian@2,4@xiaoming@2,5@xiaowang@3,6@xiaotian@4,7@xiaogang@1,8@xiaoqiang@1,9@xiaojing@2,10@xiaotie@2,11@wangqiang@3,12@wangwei@3,13@liming@4,14@liqiang@4 |
| 12 | wangwei | 3 | 1@xiaoming@1,2@xiaowang@1,3@xiaotian@2,4@xiaoming@2,5@xiaowang@3,6@xiaotian@4,7@xiaogang@1,8@xiaoqiang@1,9@xiaojing@2,10@xiaotie@2,11@wangqiang@3,12@wangwei@3,13@liming@4,14@liqiang@4 |
| 13 | liming | 4 | 1@xiaoming@1,2@xiaowang@1,3@xiaotian@2,4@xiaoming@2,5@xiaowang@3,6@xiaotian@4,7@xiaogang@1,8@xiaoqiang@1,9@xiaojing@2,10@xiaotie@2,11@wangqiang@3,12@wangwei@3,13@liming@4,14@liqiang@4 |
| 14 | liqiang | 4 | 1@xiaoming@1,2@xiaowang@1,3@xiaotian@2,4@xiaoming@2,5@xiaowang@3,6@xiaotian@4,7@xiaogang@1,8@xiaoqiang@1,9@xiaojing@2,10@xiaotie@2,11@wangqiang@3,12@wangwei@3,13@liming@4,14@liqiang@4 |
假设执行下面的SQL语句
SELECT NAME, CLASSID, GROUP_CONCAT(ID, '@', NAME, '@', CLASSID)
FROM Student;
则结果如下:

如果加上GROUP BY,那么就是对每个组的属性进行拼接,以上面的SQL语句为例,
SELECT COUNT(1), NAME, CLASSID, GROUP_CONCAT(ID, '@', NAME, '@', CLASSID)
FROM Student
GROUP BY CLASSID;
则结果相当于从
CLASSID = 1 组:
| ID | NAME | CLASSID | tmp | COUNT(1) | GROUP_CONCAT(ID, ‘@’, NAME, ‘@’, CLASSID) |
|---|---|---|---|---|---|
| 1 | xiaoming | 1 | 1 | 4 | 1@xiaoming@1,2@xiaowang@1,7@xiaogang@1,8@xiaoqiang@1 |
| 2 | xiaowang | 1 | 1 | 4 | 1@xiaoming@1,2@xiaowang@1,7@xiaogang@1,8@xiaoqiang@1 |
| 7 | xiaogang | 1 | 1 | 4 | 1@xiaoming@1,2@xiaowang@1,7@xiaogang@1,8@xiaoqiang@1 |
| 8 | xiaoqiang | 1 | 1 | 4 | 1@xiaoming@1,2@xiaowang@1,7@xiaogang@1,8@xiaoqiang@1 |
CLASSID=2组:
| ID | NAME | CLASSID | tmp | COUNT(1) | GROUP_CONCAT(ID, ‘@’, NAME, ‘@’, CLASSID) |
|---|---|---|---|---|---|
| 3 | xiaotian | 2 | 1 | 4 | 3@xiaotian@2,4@xiaoming@2,9@xiaojing@2,10@xiaotie@2 |
| 4 | xiaoming | 2 | 1 | 4 | 3@xiaotian@2,4@xiaoming@2,9@xiaojing@2,10@xiaotie@2 |
| 9 | xiaojing | 2 | 1 | 4 | 3@xiaotian@2,4@xiaoming@2,9@xiaojing@2,10@xiaotie@2 |
| 10 | xiaotie | 2 | 1 | 4 | 3@xiaotian@2,4@xiaoming@2,9@xiaojing@2,10@xiaotie@2 |
CLASSID=3组:
| ID | NAME | CLASSID | tmp | COUNT(1) | GROUP_CONCAT(ID, ‘@’, NAME, ‘@’, CLASSID) |
|---|---|---|---|---|---|
| 5 | xiaowang | 3 | 1 | 3 | 5@xiaowang@3,11@wangqiang@3,12@wangwei@3 |
| 11 | wangqiang | 3 | 1 | 3 | 5@xiaowang@3,11@wangqiang@3,12@wangwei@3 |
| 12 | wangwei | 3 | 1 | 3 | 5@xiaowang@3,11@wangqiang@3,12@wangwei@3 |
CLASSID=4组:
| ID | NAME | CLASSID | tmp | COUNT(1) | GROUP_CONCAT(ID, ‘@’, NAME, ‘@’, CLASSID) |
|---|---|---|---|---|---|
| 6 | xiaotian | 4 | 1 | 3 | 6@xiaotian@4,13@liming@4,14@liqiang@4 |
| 13 | liming | 4 | 1 | 3 | 6@xiaotian@4,13@liming@4,14@liqiang@4 |
| 14 | liqiang | 4 | 1 | 3 | 6@xiaotian@4,13@liming@4,14@liqiang@4 |
最终通过SQL执行结果如下:
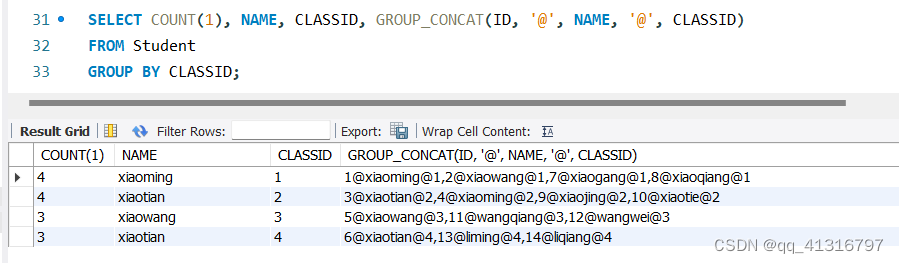
COUNT中可以放的值
COUNT中除了可以放* , 1, 等,还可以放属性,COUNT(NAME)的含义是计算同一个组中NAME中不为空的属性的属性,我们建立一个新的表
CREATE TABLE IF NOT EXISTS Teacher (
ID INT PRIMARY KEY,
NAME VARCHAR(20),
CLASSID INT NOT NULL
);
INSERT INTO Teacher
VALUES
(1, 'xiaoming', 1),
(2, 'xiaowang', 1),
(3, 'xiaotian', 2),
(4, NULL, 2),
(5, 'xiaowang', 3),
(6, 'xiaotian', 4),
(7, 'xiaogang', 1),
(8, 'xiaoqiang', 1),
(9, NULL, 2),
(10, 'xiaotie', 2),
(11, NULL, 3),
(12, NULL, 3),
(13, 'liming', 4),
(14, NULL, 4);
然后执行以下的SQL语句
SELECT COUNT(NAME), CLASSID
FROM Teacher
GROUP BY CLASSID;
执行 FROM Teacher GROUP BY CLASSID;
得到的结果是
CLASSID = 1 组:
| ID | NAME | CLASSID |
|---|---|---|
| 1 | xiaoming | 1 |
| 2 | xiaowang | 1 |
| 7 | xiaogang | 1 |
| 8 | xiaoqiang | 1 |
CLASSID=2组:
| ID | NAME | CLASSID |
|---|---|---|
| 3 | xiaotian | 2 |
| 4 | NULL | 2 |
| 9 | xiaojing | 2 |
| 10 | xiaotie | 2 |
CLASSID=3组:
| ID | NAME | CLASSID |
|---|---|---|
| 5 | xiaowang | 3 |
| 11 | NULL | 3 |
| 12 | NULL | 3 |
CLASSID=4组:
| ID | NAME | CLASSID |
|---|---|---|
| 6 | xiaotian | 4 |
| 13 | liming | 4 |
| 14 | NULL | 4 |
那么,在执行COUNT(NAME)后,会在上述表的后面加上一列
CLASSID = 1 组:
| ID | NAME | CLASSID | COUNT(NAME) |
|---|---|---|---|
| 1 | xiaoming | 1 | 4 |
| 2 | xiaowang | 1 | 4 |
| 7 | xiaogang | 1 | 4 |
| 8 | xiaoqiang | 1 | 4 |
CLASSID=2组:
| ID | NAME | CLASSID | COUNT(NAME) |
|---|---|---|---|
| 3 | xiaotian | 2 | 2 |
| 4 | NULL | 2 | 2 |
| 9 | NULL | 2 | 2 |
| 10 | xiaotie | 2 | 2 |
CLASSID=3组:
| ID | NAME | CLASSID | COUNT(NAME) |
|---|---|---|---|
| 5 | xiaowang | 3 | 1 |
| 11 | NULL | 3 | 1 |
| 12 | NULL | 3 | 1 |
CLASSID=4组:
| ID | NAME | CLASSID | COUNT(NAME) |
|---|---|---|---|
| 6 | xiaotian | 4 | 2 |
| 13 | liming | 4 | 2 |
| 14 | NULL | 4 | 2 |
最终执行完SQL之后的结果如下:
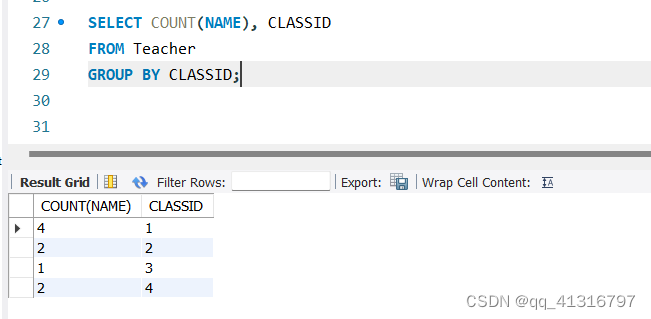
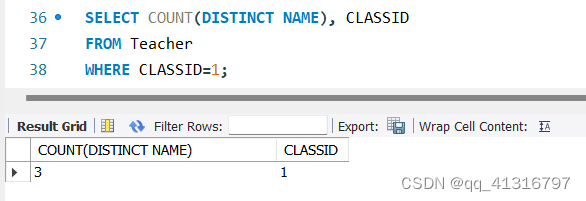
此外,COUNT在添加属性的时候,还可以加上DISTINCT属性,以达到去重的目标
实验时,将ID=2的NAME属性更新为NAME=1的属性,然后观察CLASSID=1的组中的NAME属性去重后的COUNT.
SELECT COUNT(DISTINCT NAME), CLASSID
FROM Teacher
WHERE CLASSID=1;
最终通过执行SQL得到的结果为3,因为ID=1和ID=2的NAME属性重复了。















 896
896











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









