







前言
P6分析HMM、CTC、RNN-T如何穷举所有可能的alignment。

下面只用RNN-T作为例子
score computation
选取一条alignment , h = 𝜙 c 𝜙 𝜙 a 𝜙 t 𝜙 𝜙,我们要怎么计算给acoustic feature x 1 : 6 x_{1:6} x1:6 来产生这个这个alignment h的几率呢?
首先,先计算 𝜙 在句首的几率 P(𝜙|X),再计算在 𝜙 条件下产生 c的几率 P(c|X,𝜙),再计算已产生𝜙 c 后生成 𝜙 的几率 P(𝜙|X,𝜙 c),…,依次类推,直到计算到P(𝜙|X,𝜙,c,𝜙,𝜙,a,𝜙,t,𝜙)。最终将这些几率累乘,便是这条路径也就是一个alignment的几率。
阿芒Aris
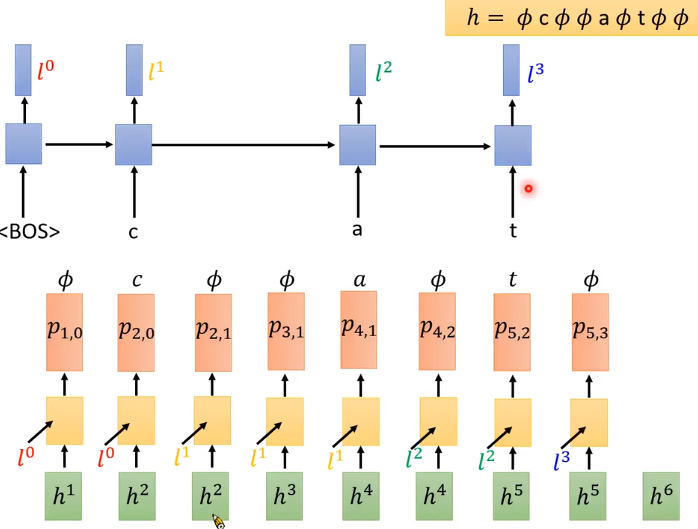
对于RNN-T而言,模型会先读取第一个acoustic feature h 1 h^1 h1(经过encoder的x1),同时RNN-T另外训练了一个RNN(蓝色部分),这个RNN会把decoder产生出来的token当作输入(note that ignore ϕ \phi ϕ),生成 l 0 l^0 l0去影响RNN-T接下来的predict.
另外训练的RNN(蓝色框框)因为一开始没有token,故输入初始token <BOS>(begin of sentence),产生一个vector l 0 l^0 l0(红色),接下来把从encoder来的 h 1 h^1 h1(代表第一个acoustic feature)和 l 0 l^0 l0输入到Decoder里面,Decoder产生一个probability distribution(用p1,0表示,第一个下标1代表由第一个acoustic feature产生,第二个下标0代表decoder产生了0个token,不含 ϕ \phi ϕ),则P(𝜙|X)便是 p 1 , 0 p_{1,0} p1,0里面𝜙的概率。接下来我们要计算P(c|X,𝜙),在decoder 产生 𝜙 的时候:对于左上角的RNN是没有影响的,故还是RNN给decoder的还是 l 0 l^0 l0; 但对decoder而言,一旦生成 𝜙 就代表decoder要处理下一个 acoustic feature,故输入 h 2 h^2 h2,同样地,decoder产生一个probability distribution,其中c的概率便是P(c|X,𝜙),依次类推,并把这些概率累乘便得到了P(h|X)。
总而言之,计算P(h|X)中的每一项就是按步查找按照对应的probability distribution,对本例而言,也就是 𝜙 在p1,0的几率,c在p2,0的几率,𝜙 在p2,1的几率,…,𝜙 在p6,3的几率 的累乘,就是这个alignment的几率。
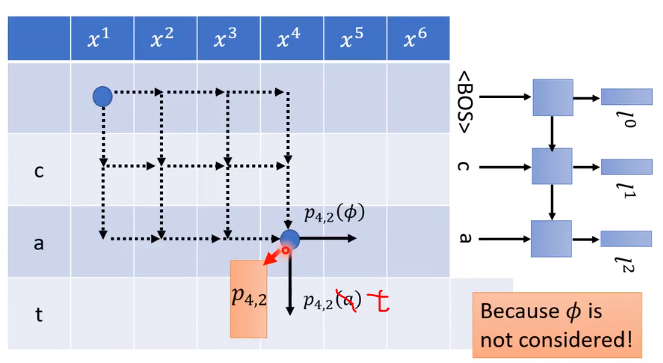
上图表格中的每一个格都对应到一个固定的概率的distribution,如上图的蓝点代表p4,2 (p4,2中第一个下标代表由第几个acoustic feature产生,第二个下标代表decoder已经产生了几个非𝜙 token)因此 这里的p4,2指的是读到h4的acoustic feature,已经产生了2个token c和a,并已经放到了单独训练的RNN里产生 l 2 l^2 l2。因此,
关键:每个格子代表的distribution不受到如何走到这个格子所影响。
就比如我们走到p4,2这个格子有很多种走法,但一走到这个格子,这个格子代表的distribution是固定的。
解释:对于 h 4 h^4 h4它只与已经产生的𝜙的个数有关, l 2 l^2 l2只与已经产生的token数目有关。这个单独训练的RNN是独立的,它只处理token,故无论𝜙在什么位置,对于顺序固定的token,它的输出都是一样的。
sum all alignment
α i , j α_{i,j} αi,j:the summation of the scores of all the alignments that read i-th acoustic features and output j-th tokens

类似动态规划
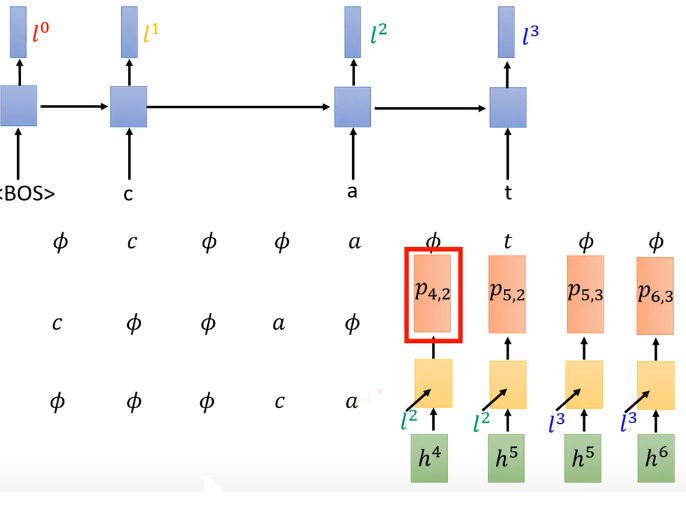
- 如 α 4 , 2 α_{4,2} α4,2格子,把所有读过4个acoustic feature且输出2个token的路径全部找出来,将概率累加。
- 我们目标不是 α 4 , 2 α_{4,2} α4,2,是最右下角的 α i , j α_{i,j} αi,j代表所有alignments的总和。
- 至此,我们已经能够计算

Question3——training
已经知道怎么计算 P θ ( Y ∣ X ) P_θ(Y | X) Pθ(Y∣X),但要先有RNN-T,即训练θ,才能计算P。
任务:假设给一段声音讯号x和人工标注的对应文字
Y
^
\hat{Y}
Y^
,我们希望找到参数
θ
\theta
θ 使得
P
θ
(
Y
^
∣
X
)
P_{\theta}(\hat{Y}|X)
Pθ(Y^∣X)的概率最越大越好。
优化gradient descent:求参数θ对
P
θ
(
Y
∣
X
)
P_θ(Y | X)
Pθ(Y∣X)的偏微分。因为P由所有可能的alignment组成的,所以P由产生每个路径(产生token或者
ϕ
\phi
ϕ)的几率相乘以后相加。

图中两个相加项代表两条不同的路径(alignment)。
第一部分: P 4 , 1 ( a ) P_{4,1}(a) P4,1(a)对θ的偏微分
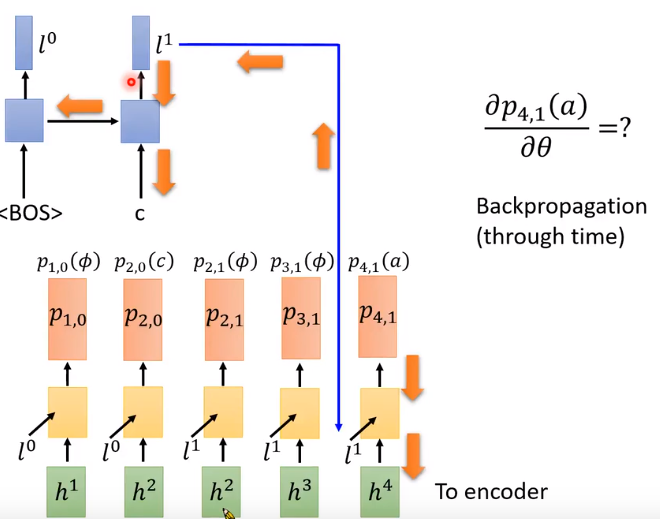
使用BPTT,先初始化参数产生 P 4 , 1 P_{4,1} P4,1,接下来Bp更新参数,和训练一般的神经网络是一样的。
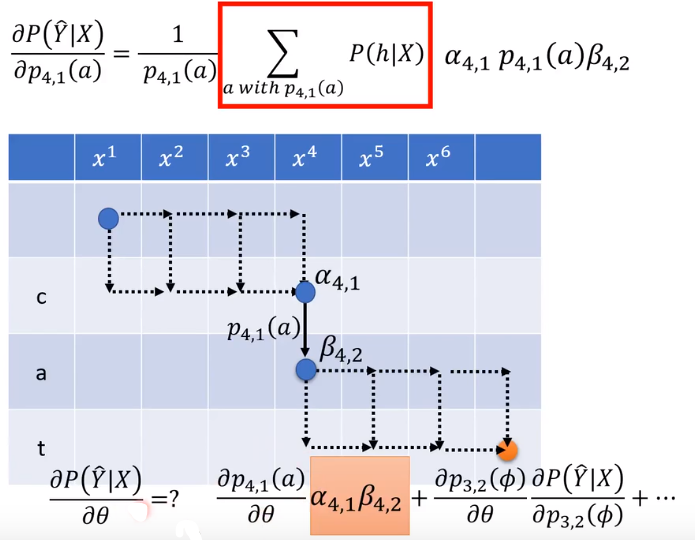
第二部分:计算 P θ ( Y ^ ∣ X ) P_{\theta}(\hat{Y}|X) Pθ(Y^∣X)对 P 4 , 1 ( a ) P_{4,1}(a) P4,1(a)的偏微分。
- step 1

- step 2 不含 P 4 , 1 ( a ) P_{4,1}(a) P4,1(a)的路径偏微分为0,other指路径中除了 P 4 , 1 ( a ) P_{4,1}(a) P4,1(a)的元素(component,箭头)

- step 3

- step 4:计算所有有通过
P
4
,
1
(
a
)
P_{4,1}(a)
P4,1(a)的alignment的分数和,上述的分子。
引入 β i , j β_{i,j} βi,j:the summation of the score of all the alignments staring from i-th acoustic features and j-th tokens 代表的是从i,j点到终点的alignments的概率和。
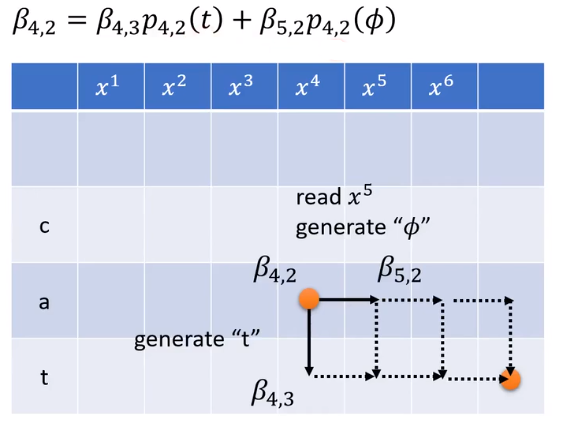
所以经过
P
4
,
1
(
a
)
P_{4,1}(a)
P4,1(a)这一箭头的路径可以表示为:
先到达
a
4
,
1
a_{4,1}
a4,1的所有路径——
a
4
,
1
a_{4,1}
a4,1,
然后必定产生token a——
P
4
,
1
(
a
)
P_{4,1}(a)
P4,1(a),
再加上从acoustic
x
4
x^4
x4 token a 到达终点——
β
4
,
2
β_{4,2}
β4,2
得公式:
Question4——testing
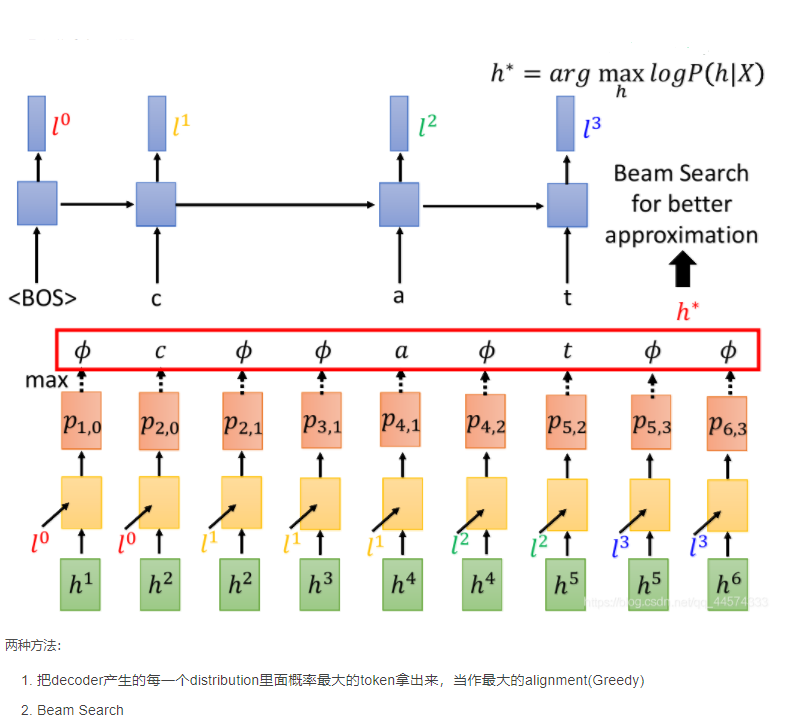
现在模型训练好了参数,可以算出P(Y|X),接下来在语音辨识的时候,声音讯号给定了即X,要找出Y,使得P(Y|X)最大,这个使得P(Y|X)最大的Y便是语音辨识的结果。
理想上:穷举所有的Y,每个Y还有多种可能的alignment。
实际上:把
∑
P
(
h
∣
X
)
\sum{P(h|X)}
∑P(h∣X)替换成
max
P
(
h
∣
X
)
\max{P(h|X)}
maxP(h∣X) ,即将align(Y)范围内的概率P的求和替换成范围内使得概率P最大的h——alignment。

找最大的alignment
结束summary

看懂说明前面的知识掌握了。















 2356
2356











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









