







一: 统计:
1: 加载数据:
import pandas as pd
college = pd.read_csv(‘C:/Users/11737/Desktop/机器学习课件/data/college.csv’)
college.head()
2:统计数据的列:
college.columns
3:查看数据的行和列:
college.shape
4:统计每列的数值信息:
college.describe()
5: 统计每列的数值信息,然后转置。
college.describe().T
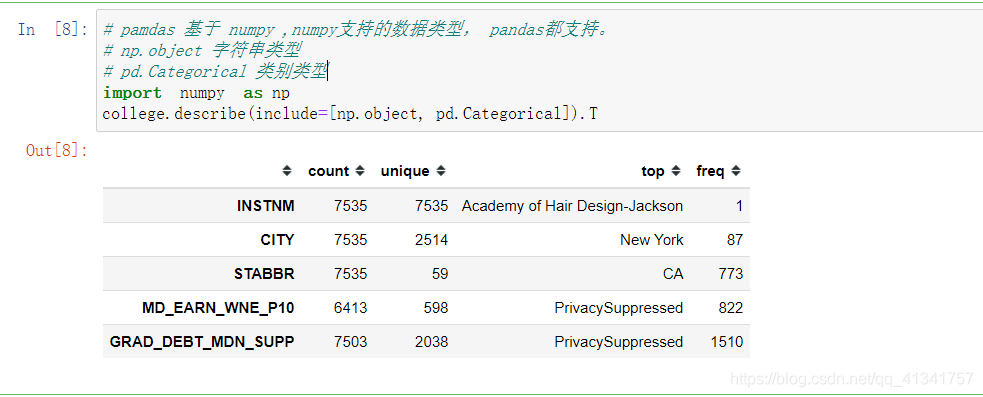
6:统计对象和类型列:
pamdas 基于 numpy ,numpy支持的数据类型, pandas都支持。
np.object 字符串类型
pd.Categorical 类别类型
import numpy as np
college.describe(include=[np.object, pd.Categorical]).T
7:查看字段的信息:
college.info()
二:排序:
1:选择最高分的前100个:
movie = pd.read_csv(‘C:/Users/11737/Desktop/机器学习课件/data/movie.csv’)
movie2 = movie[[‘movie_title’, ‘imdb_score’, ‘budget’]]
movie2.nlargest(100, ‘imdb_score’)
2: 选出刚才100个中,预算最小的5个:
movie2.nlargest(100, ‘imdb_score’).nsmallest(5, ‘budget’)
3:按照年份逆序排序:
movie2 = movie[[‘movie_title’, ‘title_year’, ‘imdb_score’]]
movie2.sort_values(‘title_year’, ascending=False).head()
4:按照年份和评分逆序排序:
movie2.sort_values([‘title_year’, ‘imdb_score’], ascending=False).head()
5:按照年进行去重,只保留第一个:
movie2.sort_values([‘title_year’, ‘imdb_score’], ascending=False).drop_duplicates(subset=‘title_year’).head()
6:对年份,级别降序,对花费升序:
提取出每年,每种电影分级中预算少的电影——sort_values多列排序
movie4 = movie[[‘movie_title’, ‘title_year’, ‘content_rating’, ‘budget’]]
多列排序,ascending=[False, False, True] 降序,降序,升序
movie4_sorted = movie4.sort_values([‘title_year’, ‘content_rating’, ‘budget’], ascending=[False, False, True])
去重,删除’title_year’, 'content_rating’相同的数据
movie4_sorted.drop_duplicates(subset=[‘title_year’, ‘content_rating’]).head()
三:案例分析:
对租房数据进行分析:
1: 载入数据:
import pandas as pd
house_data = pd.read_csv(‘C:/Users/11737/Desktop/机器学习课件/data/LJdata.csv’)
2: 将列名替换成英文:
house_data.columns = [‘district’, ‘address’, ‘title’, ‘house_type’, ‘area’, ‘price’, ‘floor’, ‘build_time’, ‘direction’, ‘update_time’, ‘view_num’, ‘extra_info’, ‘link’]
3: 查看数的基本信息:
house_data.head()
house_data.info()
house_data.shape
house_data.describe()
4:查询租金最高和最低的房子:
house_data[house_data[‘price’] == house_data[‘price’].min()]
house_data[house_data[‘price’] == house_data[‘price’].max()]
5:获取房屋价格最低和最高的房屋信息:
house_data.sort_values(by=‘price’).head(1)
house_data.sort_values(by=‘price’).tail(1)
6:查询最新的10套房子:
house_data.sort_values(by=‘update_time’, ascending=False).head(10)
7:查看所有的跟新时间,按时间降序排列:
house_data.sort_values(by=‘update_time’, ascending=False)[‘update_time’].unique()

8: 查看看房人数的平均值和中位数:
house_data[‘view_num’].mean() # 平均值
house_data[‘view_num’].median() # 中位数
9:获取不同看房人数的房源的数量:
先根据看房人数将房源分组,然后取出房源的名字,最后统计房源名字的数量。
tmp_df = house_data.groupby(‘view_num’,as_index=False)[‘district’].count()
修改列名
tmp_df.columns = [‘view_num’, ‘count’]
tmp_df.head()
10:对上面的看房人数和房源数量进行构图:
%matplotlib inline
tmp_df[‘count’].plot(kind=‘bar’,figsize=(20,10))
解释: inline是notebook中的绘图包, tmp_df[‘count’]是指定绘图的纵轴,plot表示线形图,加上属性kind=‘bar‘, 表示绘制柱状图。figsize表示图的大小。
11: 求房子价格的平均值,中位数,方差:
house_data[‘price’].mean() 平均值
house_data[‘price’].std() 中位数
house_data[‘price’].median() 方差
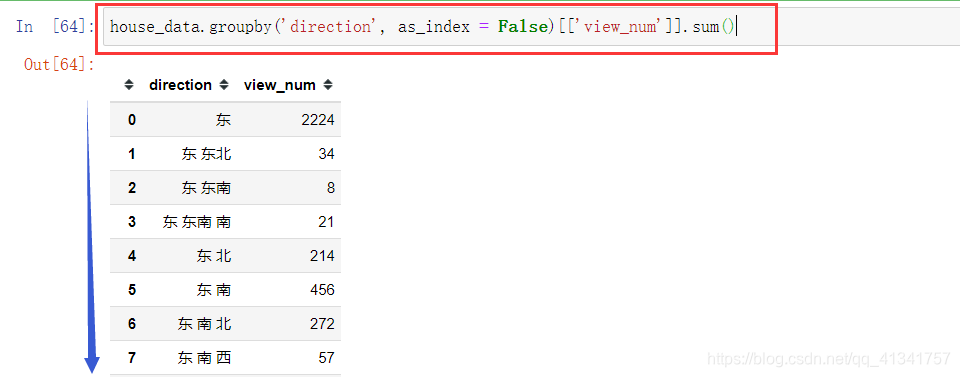
12: 查看房间人数最多的朝向:
先将数据根据朝向分组,取出查看的人数,对分组内部进行求和。
然后查询查看人数等于求和最大的信息。
popular_direction = house_data.groupby(‘direction’, as_index = False)[[‘view_num’]].sum()
popular_direction[popular_direction[‘view_num’] ==popular_direction[‘view_num’].max()]

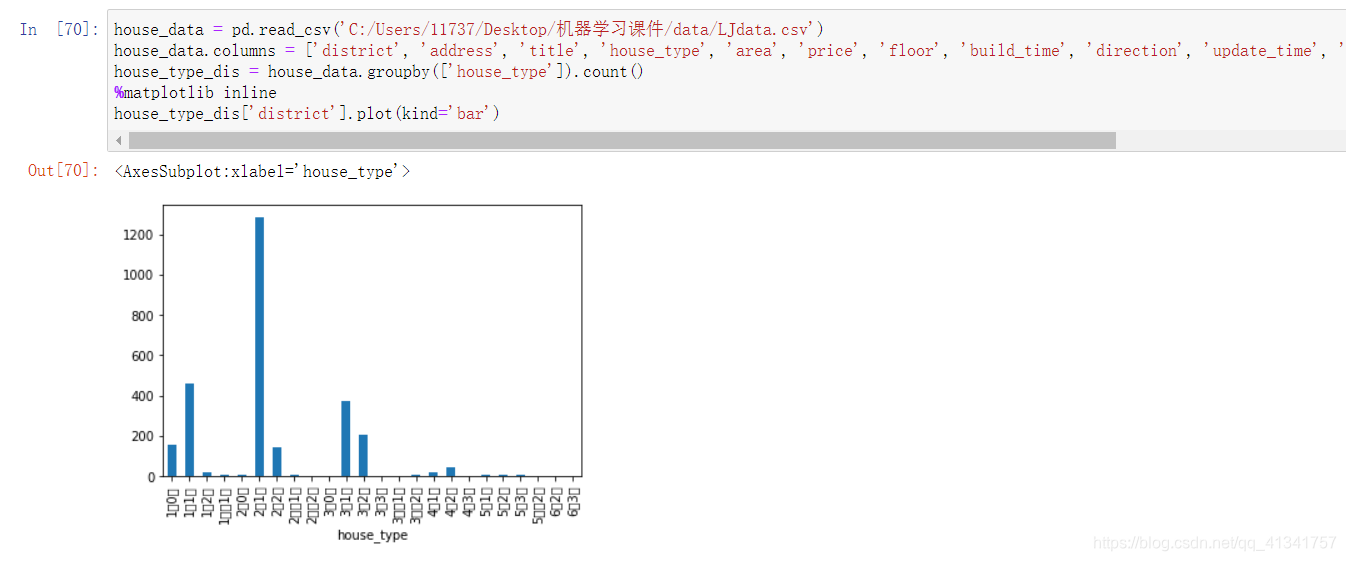
13: 查看房型的分布情况:
import matplotlib.pyplot as plt
导入这个包是为了解决中文乱码问题:
plt.rcParams[‘axes.unicode_minus’] = False
可以用来正常的显示负号。
house_type_dis = house_data.groupby([‘house_type’]).count()
%matplotlib inline
house_type_dis[‘district’].plot(kind=‘bar’)
拿到的统计表会根据分组的字段作为横坐标,统计的结果作为纵坐标。
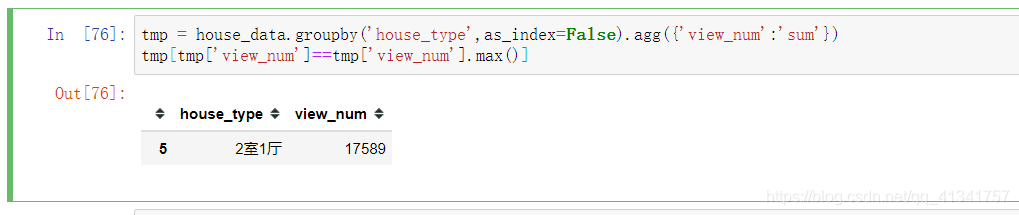
14:最受欢迎的房型:
思路:根据房子型号进行分组,然后使用agg()进行聚合,里面可以是元祖或者字典,字典的键是列名,值是组内聚合的结果。
tmp = house_data.groupby(‘house_type’,as_index=False).agg({‘view_num’:‘sum’})
tmp[tmp[‘view_num’]==tmp[‘view_num’].max()]
15:房子的平均租房价格:
思路:先使用房子价格/房子的面积,得到数据,增加一列。然后再对这新增的一列,求平均。
house_data.loc[:, ‘price_per_m2’] = house_data[‘price’] / house_data[‘area’]
house_data[‘price_per_m2’].mean()

16:热门小区:
思路:根据小区进行分组,然后统计组内的个数。根据个数再排序就可以了。
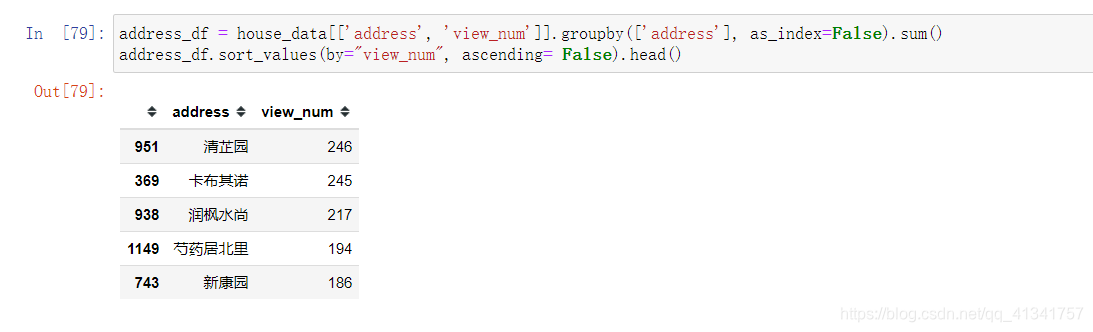
17:出租房源最多的小区:
思路:根据小区进行分组,然后计算每个组的个数。修改两个列的名字,第一个不需要修改,但是第二个必须修改,view_num在这里只是为了占位置的,实际位置上统计的是每个组的个数。
tmp_df2 = house_data[[‘address’,‘view_num’]].groupby([‘address’],as_index=False).count() tmp_df2.columns = [‘address’,‘count’]
tmp_df2.nlargest(columns=‘count’, n=1)
















 4735
4735











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











