







知乎登陆
@(博客)[Python, 登陆, 知乎, 爬虫]
018.8.12
背景
因为学年综合实践准备的一部分需要爬取知乎全站,所以为了方便,自动登陆是很有必要的。而由于许多学习爬虫的各友,都爱拿知乎练手——其实我倒非然,这算是第一次对知乎“开战”,是客观因素导致的必然——以至于知乎加强了反扒机制

我爬虫经验有限,实在不知该对这样的加密如何下手,一番搜索引擎之后,得到的都是过期操作。Github上找到了通过二维码扫描登陆的思路,那就以此宣战吧。
也在此感谢这名网友的无私奉献,点击可查看
题外话
说句题外话:切不可以惯性思维
另:完整代码已上传Github,文章末尾有链接。里边的study文件是我整个思考过程中产生的测试代码,如果只是需要实现知乎登陆,则study文件可以直接删除
环境
(1)python3.6
(2)主要第三方库:
requestsPIL:pip3 install -i https://pypi.douban.com/simple/ pillow利用豆瓣源,加快下载速度,因为直接安装可能会出现timeout的错误
(3)chrome
寻找切入点
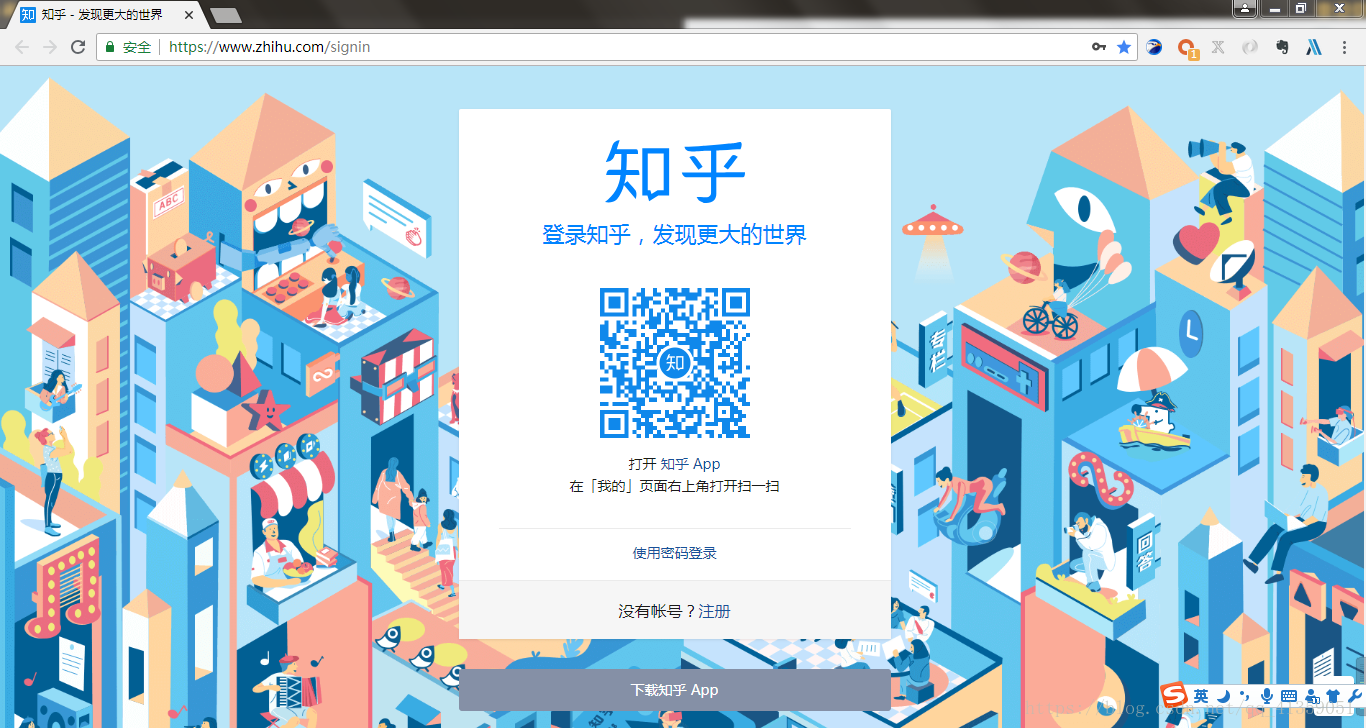
第一步肯定是先来到知乎提供二维码登陆的界面,利用开发工具,可查看请求这个二维码图片需要那些数据
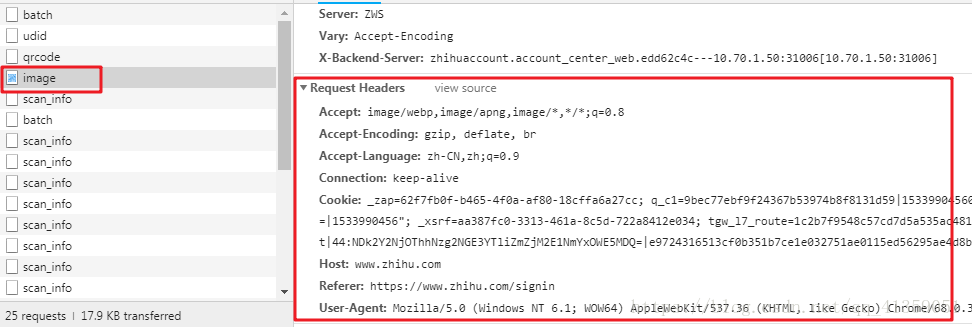
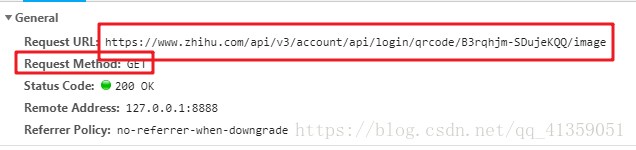
能看到是get请求,headers也很寻常,但多次刷新可发现请求的url地址有一部分在改变
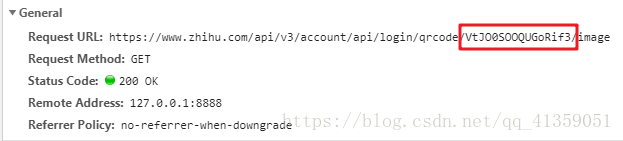
这肯定算不上什么难点,我们寻找前面的文件,能找到这部分动态改变的值
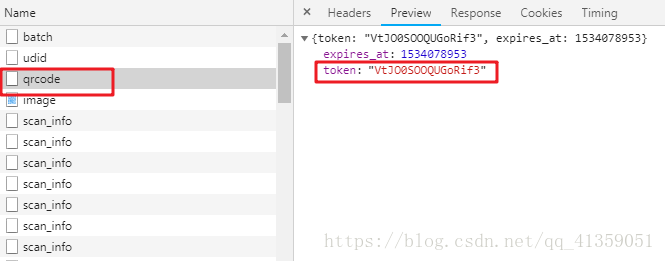
为了方便阐述,那就把image称之为A文件,qrcode成为B文件。这里就有了一个思路,先请求B文件,拿到token值以后,拼接成目的url,再去请求A文件
问题的转移1
于是我们从A迁移到了B
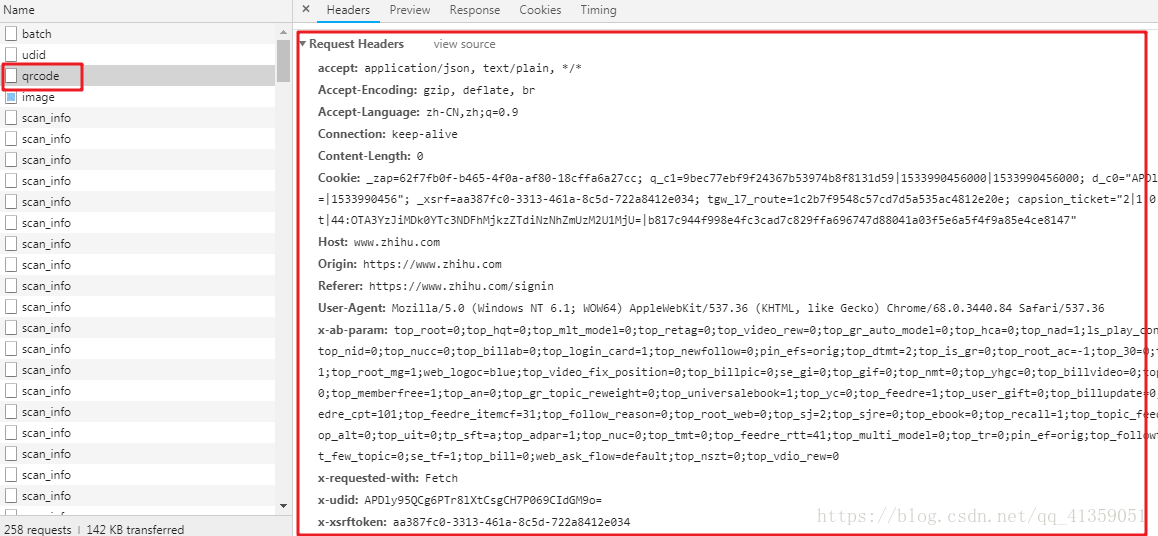
可见请求B文件的时候,headers字段是真的很多,但绝对不会所有都必要,这只能排除法了
以我拙见是这样处理的,首先看清楚了,是POST请求(从爬虫到现在也几个月了,还是爬了不少网站,真的不提交数据用post请求的,我第一次见,所以之前一直是惯性思维的用get,然后一直请求失败, 所以各位入门爬虫的注意了,千万注意了别掉坑里)
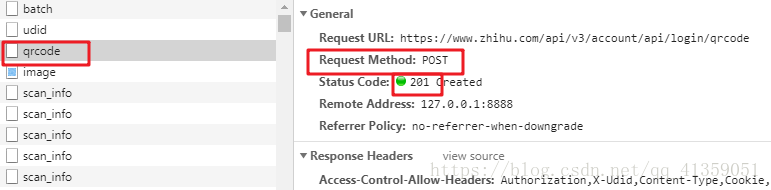
复制了所有headers,做一次post的请求,再看看状态码是不是201(为了避免请求被重定向,建议打印请求内容,或者关闭重定向,后面皆以打印内充处理不再单独提示)(对应study/test1.py文件)
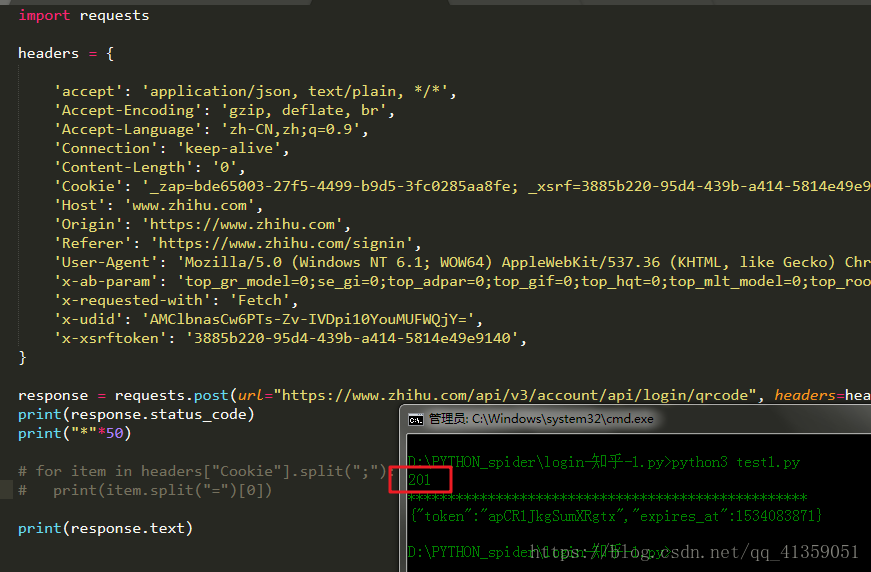
可以说很OK,然后就开始排除法,首先去掉的是最常用不到的噻。通过几轮排除下来,发现Cookie和User-Agent是必要的,
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 2816
2816











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









