







PostgreSQL LIKE 子句:获取包含某些字符的数据
在 PostgreSQL 数据库中,我们如果要获取包含某些字符的数据,可以使用 LIKE 子句。
在 LIKE 子句中,通常与通配符结合使用,通配符表示任意字符,在 PostgreSQL 中,主要有以下两种通配符:
- 百分号 %
- 下划线 _
如果没有使用以上两种通配符,LIKE 子句和等号 = 得到的结果是一样的。
//使用 LIKE 子句搭配百分号 % 和下划线 _ 从数据库中获取数据的通用语法:
SELECT FROM table_name WHERE column LIKE 'XXXX%';
SELECT FROM table_name WHERE column LIKE '%XXXX%';
SELECT FROM table_name WHERE column LIKE 'XXXX_';
SELECT FROM table_name WHERE column LIKE '_XXXX';
SELECT FROM table_name WHERE column LIKE '_XXXX_';
你可以在 WHERE 子句中指定任何条件。
你可以使用 AND 或者 OR 指定一个或多个条件。
XXXX 可以是任何数字或者字符。
下面是 LIKE 语句中演示了 % 和 _ 的一些差别:
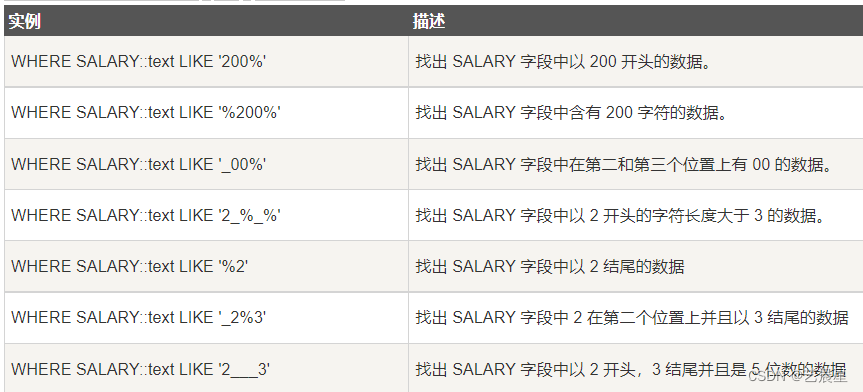
在 PostgreSQL 中,LIKE 子句是只能用于对字符进行比较,因此在上面例子中,我们要将整型数据类型转化为字符串数据类型。
实例:
mydb=# select * from COMPANY;
id | name | age | address | salary | join_date
----+-------+-----+----------------------------------------------------+--------+------------
4 | Mark | 25 | Rich-Mond | 65000 | 2007-12-13
5 | David | 27 | Texas | 85000 | 2007-12-13
3 | Teddy | 23 | Norway | 20000 |
2 | Allen | 25 | Texas | | 2007-12-13
1 | Paul | 32 | California | 20000 | 2001-07-13
(5 行记录)
//将找出 AGE 以 2 开头的数据:
mydb=# SELECT * FROM COMPANY WHERE AGE::text LIKE '2%';
id | name | age | address | salary | join_date
----+-------+-----+----------------------------------------------------+--------+------------
4 | Mark | 25 | Rich-Mond | 65000 | 2007-12-13
5 | David | 27 | Texas | 85000 | 2007-12-13
3 | Teddy | 23 | Norway | 20000 |
2 | Allen | 25 | Texas | | 2007-12-13
(4 行记录)
//将找出 address 字段中含有 - 字符的数据:
mydb=# SELECT * FROM COMPANY WHERE ADDRESS LIKE '%-%';
id | name | age | address | salary | join_date
----+------+-----+----------------------------------------------------+--------+------------
4 | Mark | 25 | Rich-Mond | 65000 | 2007-12-13
(1 行记录)
PostgreSQL LIMIT 子句:限制 SELECT 语句中查询的数据的数量
PostgreSQL 中的 limit 子句用于限制 SELECT 语句中查询的数据的数量。
//带有 LIMIT 子句的 SELECT 语句的基本语法如下:
SELECT column1, column2, columnN
FROM table_name
LIMIT [no of rows]
OFFSET 子句
//下面是 LIMIT 子句与 OFFSET 子句一起使用时的语法:
SELECT column1, column2, columnN
FROM table_name
LIMIT [no of rows] OFFSET [row num]
实例:
mydb=# select * from COMPANY;
id | name | age | address | salary | join_date
----+-------+-----+----------------------------------------------------+--------+------------
4 | Mark | 25 | Rich-Mond | 65000 | 2007-12-13
5 | David | 27 | Texas | 85000 | 2007-12-13
3 | Teddy | 23 | Norway | 20000 |
2 | Allen | 25 | Texas | | 2007-12-13
1 | Paul | 32 | California | 20000 | 2001-07-13
(5 行记录)
//将找出限定的数量的数据,即读取 4 条数据:
mydb=# SELECT * FROM COMPANY LIMIT 4;
id | name | age | address | salary | join_date
----+-------+-----+----------------------------------------------------+--------+------------
4 | Mark | 25 | Rich-Mond | 65000 | 2007-12-13
5 | David | 27 | Texas | 85000 | 2007-12-13
3 | Teddy | 23 | Norway | 20000 |
2 | Allen | 25 | Texas | | 2007-12-13
(4 行记录)
//但是,在某些情况下,可能需要从一个特定的偏移开始提取记录。下面是一个实例,从第三位开始提取 3 个记录:
mydb=# SELECT * FROM COMPANY LIMIT 3 OFFSET 2;
id | name | age | address | salary | join_date
----+-------+-----+----------------------------------------------------+--------+------------
3 | Teddy | 23 | Norway | 20000 |
2 | Allen | 25 | Texas | | 2007-12-13
1 | Paul | 32 | California | 20000 | 2001-07-13
(3 行记录)















 2040
2040











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









