







异常检测与推荐系统
1 异常检测
例:假想你是一个飞机引擎制造商,当你生产的飞机引擎从生产线上流出时,你需要进行QA(质量控制测试),而作为这个测试的一部分,你测量了飞机引擎的一些特征变量,比如引擎运转时产生的热量,或者引擎的振动等等。
当以前看到这样的问题时,我首先想到的应该是使用监督学习中的逻辑回归来做。但是仔细观察数据集就能发现,这类问题中正向类要远远大于负向类,具有很大的倾斜度,有就是说会出现在之前机器学习扩展中学习到的类偏斜问题。而在这里异常检验为解决这类问题提供了一个新的思路。

1.1 高斯分布
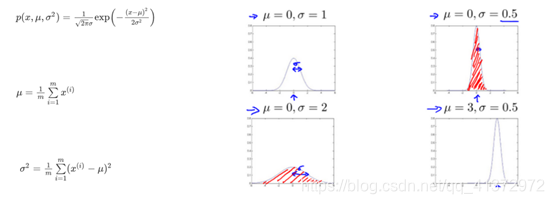
用高斯分布来表示样本某项特征的分布情况。
1.2 算法

这里是异常检测运行的算法,用这个算法可以判断一个点是否是异常点。现在的问题就是如何确定EPSILON的值了。
1.3 开发与评价
例:我们有10000台正常引擎的数据,有20台异常引擎的数据。 我们这样分配数据:
6000台正常引擎的数据作为训练集
2000台正常引擎和10台异常引擎的数据作为交叉检验集
2000台正常引擎和10台异常引擎的数据作为测试集
步骤一:计算平均值与方差并构建P(X)函数。
步骤二:根据下图所示的F1值,使用交叉验证集不断尝试直到选出合适的阀值。
步骤三:使用测试集来测试所得模型的表现,以F1值为判断标准。

我感觉异常检测的知识就是对于我之前所作的机器学习扩展内容的实际应用,其中涉及到将初始训练集划分为训练集、交叉验证集、测试集。当出现类偏斜问题时,如何处理,具体方法如右图所示。
1.4 对比

2 推荐系统
2.1 例子
例:假设我们推荐系统构建的目的是向用户推荐他可能感兴趣的电影。我们可以假设每部电影都有两个特征,如x1代表电影的浪漫程度, x2代表电影的动作程度。

我们用x(i)来表示电影i的特征向量,θ(j)来表示用户j的参数向量,对于用户j对于电影i,我们预测评分为(?^((j) ) )^? ?^((?))
2.2 代价函数
在之前的基于内容的推荐系统中,对于每一部电影,我们都掌握了可用的特征,使用这些特征训练出了每一个用户的参数。相反地,如果我们拥有用户的参数,我们可以学习得出电影的特征。

我认为推荐算法的大致还是和之前的监督学习算法一致,但是相当于是将特征与参数都赋予了定义。
2.3 协同过滤
如果我们既没有用户的参数,也没有电影的特征,那么上述的这两种方法都不可行了。协同过滤算法可以同时学习这两者。

通过这种方式,我们同样可以使用之前监督学习中的优化算法,帮助我们更加快速的进行梯度下降。














 843
843











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









