




1、索引的本质
索引是帮助MySQL高效获取数据的排好序的数据结构。
索引是一种特殊的文件(InnoDB数据表上的索引是表空间的一个组成部分),它们包含着对数据表里所有记录的引用指针。
索引是一种数据结构。数据库索引,是数据库管理系统中一个排序的数据结构,以协助快速查询、更新数据库表中数据。索引的实现通常使用B树及其变种B+树。
更通俗的说,索引就相当于目录。为了方便查找书中的内容,通过对内容建立索引形成目录。索引是一个文件,它是要占据物理空间的。
2、索引的类型
从物理存储角度分为:
① 聚集索引:将数据和索引存储在一起,通过索引可以直接找到数据
② 非聚集索引:数据和索引是分别存放的,索引的各个节点分别存储的是指向数据的指针,当访问数据时,在内存中直接搜索索引,然后通过索引找到磁盘相应数据。
从逻辑角度:
①主键索引:不允许重复,不允许为NULL,一个表只能有一个主键。
②数据列不允许重复,允许为NULL值,一个表允许多个列创建唯一索引。
可以通过 ALTER TABLE table_name ADD UNIQUE (column); 创建唯一索引
可以通过 ALTER TABLE table_name ADD UNIQUE (column1,column2); 创建唯一组合索引
③ 普通索引:基本的索引类型,没有唯一性的限制,允许为NULL值。
可以通过ALTER TABLE table_name ADD INDEX index_name (column);创建普通索引
可以通过ALTER TABLE table_name ADD INDEX index_name(column1, column2, column3);创建组合索引
④全文索引(FULLTEXT):MySQL从3.23.23版开始支持全文索引和全文检索,FULLTEXT索引仅可用于 MyISAM 表;他们可以从CHAR、VARCHAR或TEXT列中作为CREATE TABLE语句的一部分被创建,或是随后使用ALTER TABLE 或CREATE INDEX被添加。
可以通过ALTER TABLE table_name ADD FULLTEXT (column);创建全文索引
3、索引的创建方式
-
在创建表的时候
CREATE TABLE user_index2 ( id INT auto_increment PRIMARY KEY, first_name VARCHAR (16), last_name VARCHAR (16), id_card VARCHAR (18), information text, KEY name (first_name, last_name), FULLTEXT KEY (information), UNIQUE KEY (id_card) ); -
使用alter table命令创建
ALTER TABLE table_name ADD INDEX index_name (column_list);可以在列名处创建多个索引。
- 使用create index创建索引
CREATE INDEX index_name ON table_name (column_list);这种方式不能创建主键索引。
-
删除索引
根据索引名删除普通索引、唯一索引、全文索引:alter table 表名 drop KEY 索引名
4、索引的使用场景
- where语句
对where语句的字段建立索引可以提高查询效率
- order by语句
对order by 的字段建立索引,由于索引本身是有序的,因此直接按照索引的顺序和映射关系逐条取出数据即可。而且如果分页的,那么只用取出索引表某个范围内的索引对应的数据
- join语句
可以对join语句中on的连接字段建立索引。
5、创建索引的原则
索引虽好,但也不是无限制的使用,最好符合一下几个原则
1) 最左前缀匹配原则,组合索引非常重要的原则,mysql会一直向右匹配直到遇到范围查询(>、<、between、like)就停止匹配,比如a = 1 and b = 2 and c > 3 and d = 4 如果建立(a,b,c,d)顺序的索引,d是用不到索引的,如果建立(a,b,d,c)的索引则都可以用到,a,b,d的顺序可以任意调整。
2)较频繁作为查询条件的字段才去创建索引
3)更新频繁字段不适合创建索引
4)若是不能有效区分数据的列不适合做索引列(如性别,男女未知,最多也就三种,区分度实在太低)
5)尽量的扩展索引,不要新建索引。比如表中已经有a的索引,现在要加(a,b)的索引,那么只需要修改原来的索引即可。
6)定义有外键的数据列一定要建立索引。
7)对于那些查询中很少涉及的列,重复值比较多的列不要建立索引。
8)对于定义为text、image和bit的数据类型的列不要建立索引。
6、索引的数据结构⭐
- Hash表
Hash表的索引实质就是使用Hash表来存储数据,当进行等值数据查找时,可以根据哈希值直接查找数据,但是当索引的重复值较多时,会有大量的hash碰撞,导致效率低。这种方法不能进行范围查找,只能进行等值查找。
- B-Tree
① 叶节点具有相同的深度,叶节点的指针为空
② 所有的索引元素不重复
③节点中的数据索引从左到右递增排列
④每个子节点的大小默认为16KB
⑤查找不稳定,靠近根节点的数据查找速度快。
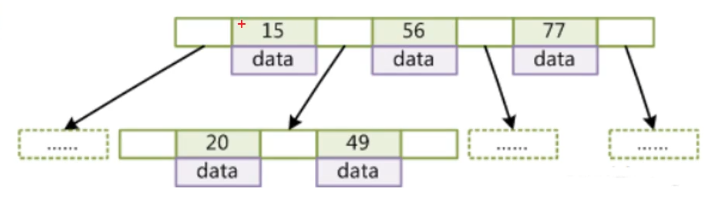
- B+Tree
拥有B-Tree的特点,另外:
非叶子节点不存储data,只存储索引(有冗余),可以放更多的索引
叶子节点包含所有索引字段
叶子节点用指针连接,提高区间访问的性能
它不仅可以被用在=,>,>=,<,<=和between这些比较操作符上,而且还可以用于like操作符,只要它的查询条件是一个不以通配符开头的常量
每一个节点均是从左到右依次增大的
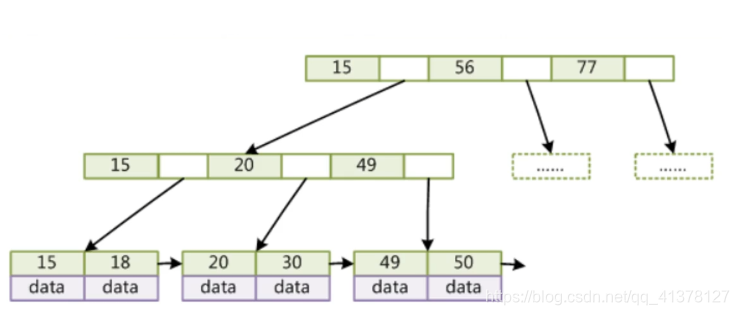
B-Tree和B+Tree的区别:
①在B树中,你可以将键和值存放在内部节点和叶子节点;但在B+树中,内部节点都是键,没有值,叶子节点同时存放键和值。
②B+树的叶子节点有一条链相连,而B树的叶子节点各自独立。
7、MySQL的引擎
常用的有:
- MyISAM索引
MyISAM索引文件和数据文件是分离的(非聚集)
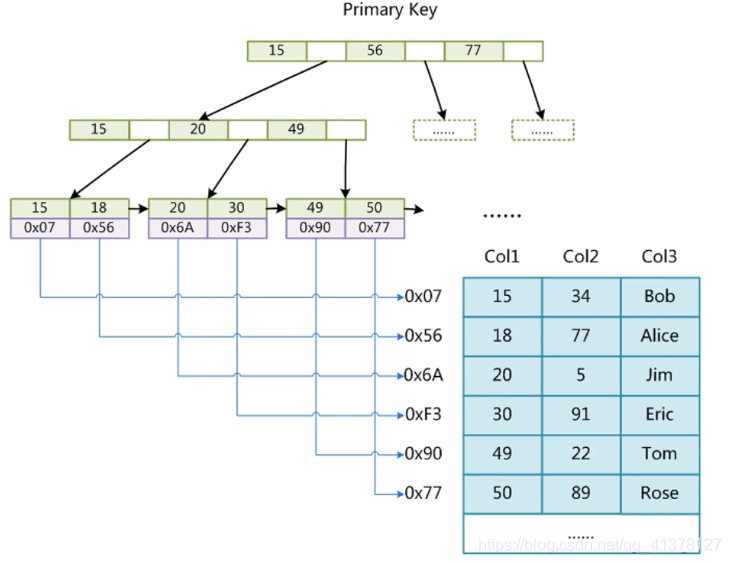
不提供事务的支持,也不支持行级锁和外键。需要进行回表查询。这种方式为非聚集索引,索引单独存放在一个文件中,存放的是数据的行地址。
- InnoDB索引(默认)
InnoDB索引实现(聚集)
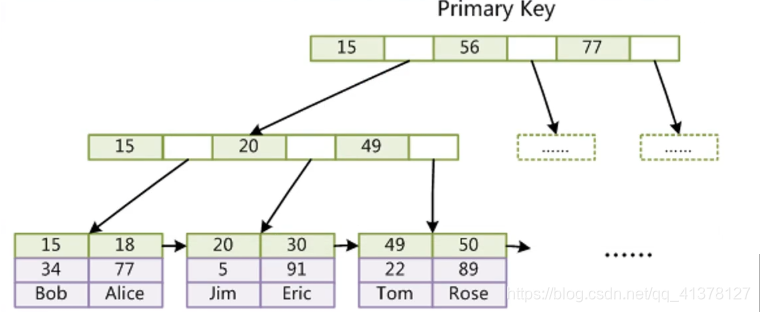
表数据文件本身就是按B+ Tree组织的一个索引结构文件
聚集索引-叶子节点包含了完整的数据记录
为什么InnoDB表必须有主键,并且推荐使用整型的自增主键?
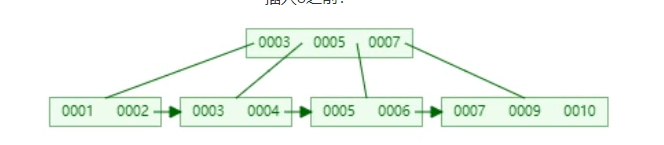
答:InnoDB会按照主键来建立索引,因此在创建表时需要指定主键,若没有主键,则会按照具有唯一性质的列建立索引,若也没有唯一的列,则会自动维护一个主键列来创建索引。索引需要进行比较等操作,整型的数据哥更适合用来比较,每一个节点的大小默认为16KB,若不是自增的主键,则在节点存满以后在进行插入时,树会进行大量的操作:
插入8之前:
插入8之后:
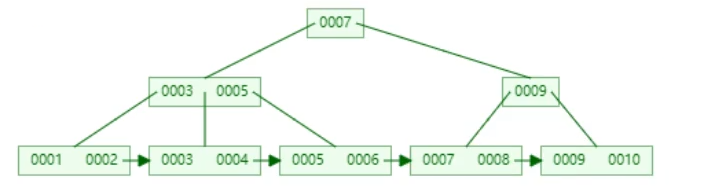
数据结构变化较大,性能开销大,若是自增的主键,则会一直在最右加入元素,树的结构不会有大的变化。
为什么非主键索引结构叶子节点存储的是主键值? (一 致性和节省存储空间)
由于主键冗余较大,因此可以采用前缀索引:
语法:index(field(10)),使用字段值的前10个字符建立索引,默认是使用字段的全部内容建立索引。
前提:前缀的标识度高。比如密码就适合建立前缀索引,因为密码几乎各不相同。
实操的难度:在于前缀截取的长度。
我们可以利用select count(*)/count(distinct left(password,prefixLen));,通过从调整prefixLen的值(从1自增)查看不同前缀长度的一个平均匹配度,接近1时就可以了(表示一个密码的前prefixLen个字符几乎能确定唯一一条记录)
- 联合索引:多个列共同作为索引。

按照最左前缀法则,依次从左至右比较每一个索引。所以联合索引中的顺序就很重要了。

















 228
228

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









