






OverView
Project 2 需要为Bustub实现B+树索引,拆分为两个部分:
- Checkpoint 1:单线程B+树
- Checkpoint 2:多线程B+树
Checkpoint 1 :Single Thread B+ Tree
Checkpoint 分为两个部分:
- Task 1:B+ Tree Pages,B+树中的各种page。在Bustub索引B+树中,所有的节点都是page。包含leaf page,internal page和它们的父类tree page。
- Task 2:B+ Tree Data Structure (Insertion,Deletion,Point Search)。Checkpoint 1的重点是B+树的插入、删除和单点查询。
Task 1 B+Tree Pages
关于各种页基本的get、set方法这里暂且不说,这部分主要介绍一下page的内存布局
在P1 中我们第一次与page打交道。page实际上可以存储数据库内很多种类的数据。例如索引和实际的表数据等。
/** The actual data that is stored within a page. */
char data_[BUSTUB_PAGE_SIZE]{};
/** The ID of this page. */
page_id_t page_id_ = INVALID_PAGE_ID;
/** The pin count of this page. */
int pin_count_ = 0;
/** True if the page is dirty, i.e. it is different from its corresponding page on disk. */
bool is_dirty_ = false;
/** Page latch. */
ReaderWriterLatch rwlatch_;
其中,data_是实际存放page数据的地方,大小为BUSTUB_PAGE_SIZE,为4KB。其他的成员是page的metadata。
B+树中的tree page数据均存放在page的data成员中。
B_PLUS_TREE_PAGE
b_plus_tree_page是另外两个page的父类,即B+树中tree page的抽象。
IndexPageType page_type_; // leaf or internal. 4 Byte
lsn_t lsn_ // temporarily unused. 4 Byte
int size_; // tree page data size(not in byte, in count). 4 Byte
int max_size_; // tree page data max size(not in byte, in count). 4 Byte
page_id_t parent_page_id_; // 4 Byte
page_id_t page_id_; // 4 Byte
// 24 Byte in total以上的数据组成了tree page的header。

page data的4KB中,24 Bytes用于存放header,剩下的用于存放tree page的数据,即KV对。
B_PLUS_TREE_INTERNAL_PAGE
对应B+树中的内部节点。
MappingType array_[1];internal page中没有新的metadata,header大小仍为24B。它唯一的成员是一个数组,这个数组是一个柔性数组,存储着KV对。
为什么数组要这样定义?
当我们有一个类时,这个类中有一个成员数组。在用这个类初始化一个对象时,我们不确定将该数组的大小设置为多少,但知道这整个对象的大小是多少byte,这时候就可以用到柔型数组。柔型数组必须是类中的最后一个成员,并且仅能有一个柔型数组。在为对象分配内存的时候,柔性数组会自动填充,占用未被其他变量使用的内存,这样就可以确定自己的长度了。
在这个项目中,利用柔性数组的特性来自动填充page data 4KB 减掉 header 24 bytes后剩余的内存。剩下的这些内存用来存放KV对。

internal page中,KV对的K是能够比较大小的索引,V是page id,用来指向下一层的节点。
Project中,第一个Key为空。主要就是因为在internal page中,n个key可以将数轴划分为n+1个区域,也就对应着n+1个value。如下:
通过比较key的大小选中下一层的节点。
需要注意的是,internal page中的key并不代表实际上的索引值,仅仅是作为一个引导,引导需要插入/删除/查询的key找到这个key真正所在的leaf page。
B_PLUS_TREE_LEAF_PAGE
leaf page和internal page的内存布局基本是一样的,只是leaf page多了一个成员变量next_page_id,指向下一个leaf page,用于range scan(范围查询)。因此leaf page的header大小为28 Byte。
leaf page的KV对中,K是实际的索引,V是record id。record id用于识别表中的某一条数据。leaf page的KV对是一一对应的,不像是internal page里面value比key多1个。在Bustub所有的B+树索引中,无论是主键索引还是二级索引都是非聚簇索引。
Task 2 B+Tree Data Structure
Task 2是单线程B+树的重点。这部分需要实现的是插入(Insert),点搜索(GetValue)和删除(Delete)。
Search
B+树的节点分为internal page和leaf page,每个page上的key有序排列。当拿到一个key需要查找对应的value时,首先需要经由internal page递归地向下查找,最终找到key所在的leaf page。这个过程可以简化为一个函数Findleaf。
Findleaf从root page开始查找。在查找到leaf page时直接返回。否则根据key在当前internal page中找到对应的child page id,递归调用findleaf。根据key查找对应child id时,由于key是有序的,可以直接进行二分查找。
internal page中存储的是key和child page id,在拿到page id之后可以用P1实现的buffer pool获取page指针,如下:
Page *page = buffer_pool_manager_->FetchPage(page_id);
同样地,假如我们需要新建一个Page,也是调用buffer pool的NewPage()。
在获取到一个page后,如何使用这个page来存储数据?
实际上page的data_字段是实际用于存储数据的4KB大小的字节数组。通过reinterpret_cast将这个字节数组强制转换为我们要使用的类型,例如leaf page:
auto leaf_page = reinterpret_cast<B_PLUS_TREE_LEAF_PAGE_TYPE *>(page->GetData())reinterpret_cast用于无关类型的强制转换,转换方法很简单,原始bits不变,只是对这些bits用新类型进行了重新的解读。这种转换是不安全的,需要确保转换后的内存布局是合法的。在这里原类型是byte数组,新类型是我们需要使用的tree page。
找到leaf page后,接着使用二分查找,找到key对应的record id。
查找的过程是比较简单,但还有一个比较重要且复杂的细节,就是page unpin问题。
我们在拿到page id后,调用buffer pool的FetchPage()函数来获取对应的page的指针。要注意的是,在使用完page之后,需要将page unpin掉,否则最终会导致buffer pool中的所有page都被pin住,无法从disk中读取其他的page。
比较合适的做法是,在本次操作中,找出page最后一次被使用的地方,并在最后一次使用后unpin。
Insert
与Search相同,第一步是根据key找到需要插入的leaf page。同样是调用FindLeaf,得到leaf page后,将key插入leaf page。要注意的是,插入时还需要保证key的有序性,同样可以二分搜索找到合适的位置插入。
在插入后,需要检查当前leaf page size是否等于max size。若相等,则要进行一次leaf page分裂操作。具体步骤为
- 新建一个空的page
- 将原page的一半转移到新的page中(新page放在原page的右边,转移原page的右半部分)
- 更新原page和新page的next page id
- 获取parent page
- 将用于区分原page和新page的key插入parent page中
- 更新parent page中所有child page的父节点指针
这些步骤都比较好理解,需要给parent page插入一个新key的原因是,多了一个子节点,自然需要多一个key来区分。其中第4步是重点,获取parent page并不是简单地通过当前page的parent id来获取,因为parent page也可能发生分裂。
在第5步我们可以拿到parent page安全地插入KV对,是因为在第4步中,我们需要返回一个安全的parent page。
第4步的具体操作如下:1.根据parent page id拿到parent page,2.判断parent page size是否等于max size,(插入前检查)3.若小于,直接返回parent page,4.否则,分裂当前internal page。并根据此后需要插入的key选择分裂后的两个page之一作为parent page返回。
分裂internal page的步骤为:1.新建一个空的page,2.将原page的一半转移到新page中,需要注意原page和新page的第一个key都是无效的,3.更新新page所有child page的父节点指针,指向新page,4.获取parent page,5.将用于区分原page和新page的key插入parent page中,6.更新parent page中所有child page的父节点指针。
可以发现,第4步同样是需要重复上述步骤。这里就发生了向上的递归,直到遇到安全的父节点或者遇到根节点。在遇到根节点时,若根节点也需要分裂,则除了需要新建一个节点用来容纳原根节点一半的KV对,还需要新建一个新的根节点。
Insert的整个流程大概就是先向下递归找到leaf page,插入KV后再向上递归分裂。
Delete
同样地,先找到leaf page。删除leaf page中key对应的KV对后,检查size是否小于min size。如果小于的话,首先尝试从两侧的兄弟节点中拿一个KV对。注意只能从兄弟节点,即父节点相同的节点中选取。假如存在一侧节点有富余的KV对,则成功拿取,结束操作。若两侧都没有多余的KV对,则与一侧节点进行合并。
拿取的过程比较简单,从左侧节点拿取时,把左侧节点最后一个KV对转移到当前节点的第一个KV对位置,从右侧节点拿取时,把右侧节点的第一个KV对转移至当前节点的最后一个KV对位置。leaf page和internal page的拿取过程基本相同,仅需要注意internal page拿取后更新子节点的父节点指针。
稍难的是合并的过程。同样,任选左右侧兄弟节点进行合并。将一个节点的所有KV对转移至另一节点。若合并的是leaf page,要注意更新next page id。若合并的是internal page,记得更新合并后page的子节点的父节点指针。然后,删除parent节点中对应的key,删除后,再次检查size是否小于min size,形成向上递归。
当合并leaf page后,删除父节点中对应的key即可,如下:

合并internal page后,并不是简单地删除父节点中对应的key,而是有一个父节点key下推的过程:

需要注意的是,root page不受min size的限制。但如果root page被删除到size只剩下1,即只有一个child page的时候,应将此child page设置为新的root page。
另外,在合并的时候,两个page合并成一个page,另一个page应该删除,释放资源,删除page时,仍是调用buffer pool的DeletePage()函数。
和Insert类似,Delete过程也是先向下递归查询leaf page,不满足min size后先尝试拿取,无法拿取则合并,并向上递归检查parent page是否满足KV对数量大于min size。
Checkpoint2 Multi Thread B+Tree
Checkpoint2也分为两个部分:
Task 3:实现leaf page的range scan
Task 4:Concurrent Index,支持B+树并发操作
Task 3 Index Iterator
实现一个遍历leaf page的迭代器,在迭代器中存储当前leaf page的指针和当前停留的位置即可。遍历完当前page后,通过next page id找到下一个leaf page。同样,记得unpin已经遍历完的page。
Task 4 Concurrent Index
这是并发B+树的重点,也是P2最难的部分。
直接给整棵树加一把锁理论上是可行的,但是并发执行性能会非常糟糕。
在这个部分,我们会使用一种特殊的加锁方式,即latch crabbing。顾名思义,就像螃蟹一样,移动一只脚,放下,移动另一只脚,再放下。基本思想是:
- 先锁住parent page
- 再锁住child page
- 假设child page是安全的,则释放parent page的锁。安全指当前page在插入或删除操作下都不会发生split/steal/merge。同时,对不同的操作,安全的定义是不同的。Search时,任何节点都是安全的,Insert时,判断max size,Delete时,判断min size。
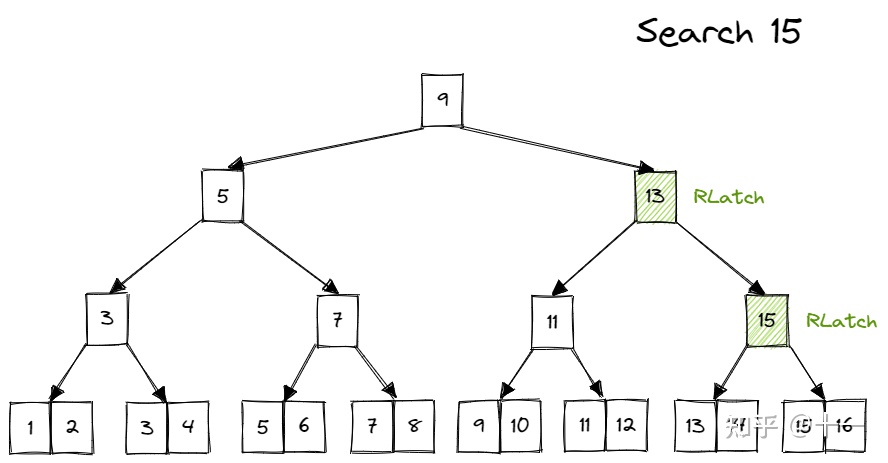
Search
Search时,从root page开始,先给parent上读锁,再给child page上读锁,然后释放parent page的锁,如此向下递归,如下:


Insert
Insert时,从root page开始,先给parent上写锁,再给child page上写锁。假如child page安全,则释放所有祖先的锁,否则不释放锁,继续向下递归。




在child page不安全的时候,需要持有祖先的写锁,并在出现安全的child page后,释放所有祖先的写锁。
如何记录哪些page当前持有锁呢?
- Transaction
transaction就是Bustub里面的事务。当一个事务(插入、删除或者查找)开始时,我们需要在函数的一开始创建一个transaction对象,然后在对B+树进行操作时,我们调用transaction的AddIntoPageSet方法来 跟踪当前线程获取的page锁,在发现一个安全的child page后,将transaction中记录的page锁全部释放掉。释放锁的顺序可以从上到下也可以从下到上,但由于上层节点的竞争一般更加激烈,所以我们采取从上到下释放锁的方法。
在完成整个Insert操作后,释放所有锁,删除事务(表示事务已经完成)。
Delete
和Insert基本一样,仅仅是判断是否安全的方法不同(判断min size)。需要注意的是,当需要steal/merge sibling时,也需要对sibling加锁。并在完成steal/merge后马上释放。这里是为了避免其他线程正在对sibling进行Search/Insert操作,从而发生data race(数据竞争)。这里的加锁就不需要在transaction里面记录了,只是临时使用,使用完之后直接释放sibling锁。
重点:脏页记录
在插入或删除的过程中,我们会对B+树上的节点进行修改,此时要设置某些页是脏的,在插入或删除时,可能会发生分裂或者合并等操作,我们使用一个全局整数变量dirty来记录当前transaction操作的页序列中最后面有几个页被修改过了,即dirty表示的是脏的页层数,也即transaction操作页序列的倒数dirty个页面,在释放所有锁的时候,我们会在unpin某个页的同时结合这个页在操作序列中的位置以及dirty大小设置该页是否被修改过,被修改过的话要设置为dirty。
Optimization
对于latch crabbing,存在一种比较简单的优化。在普通的latch crabbing中,Insert/Delete均需要对节点上写锁,而越上层的节点被访问的可能性越大,锁竞争也越激烈,频繁对上层节点上互斥的写锁对性能影响较大。因此可以进行以下的优化:
Search操作不变,在Insert/Delete操作中,我们可以先乐观地认为不会发生split/steal/merge,对沿途的节点上读锁,并及时释放,对leaf page上写锁,当发现操作对leaf/page确实不会造成split/steal/merge时,可以直接完成操作。当发现操作会使leaf page进入split/steal/merge状态时,则放弃所有持续的锁,从root page开始重新悲观地进行这次操作,即沿途上写锁。
















 1731
1731











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









