







**
任务说明
**
1. 实验目的
给出 PL/0 文法规范,要求编写 PL/0 语言的语法分析程序。
通过设计、编制、调试一个典型的自下而上语法分析程序,实现对词法分析程序所提供的单词序列进行语法检查和结构分析,进一步掌握常用的语法分析方法。
选择最有代表性的语法分析方法,如算符优先分析法、LR 分析法;或者调研语法分析器的自动生成工具 YACC 的功能与工作原理,使用YACC 生成一个自底向上的语法分析器。
2. 实验准备
微机安装好 C 语言,或 C++,或 Visual C++.
3.实验内容
已给 PL/0 语言文法,构造表达式部分的语法分析器。
分析对象〈算术表达式〉的 BNF 定义如下:
<表达式> ::= [+|-]<项>{<加法运算符> <项>}
<项> ::= <因子>{<乘法运算符> <因子>}
<因子> ::= <标识符>|<无符号整数>| ‘(’<表达式>‘)’
<加法运算符> ::= +|-
<乘法运算符> ::= *|/
<关系运算符> ::= =|#|<|<=|>|>=
4. 实验要求
将实验一“词法分析”的输出结果,作为表达式语法分析器的输入,进行语法解析,对于语法正确的表达式,报告“语法正确”;对于语法错误的表达式,报告“语法错误”, 指出错误原因。
把语法分析器设计成一个独立一遍的过程。
采用算符优先分析法或者 LR 分析法实现语法分析;或者调研语法分析器的自动生成工具 YACC 的功能与工作原理,使用YACC 生成一个自底向上的语法分析器。
5. 输入输出
输入:
PL/0 表达式,用实验一的输出形式作为输入。 例如: 对于 PL/0 表达式,(a+15)b 用下列形式作为输入:
(lparen,()
(ident,a)
(plus,+)
(number,15)
(rparen,))
(times,)
(ident,b)
输出:
对于语法正确的表达式,报告“语法正确”;
对于语法错误的表达式,报告“语法错误”, 指出错误原因。
具体实现
设计思想
扩充的巴科斯范式
<表达式> ::= [+|-]<项>{<加法运算符> <项>}
<项> ::= <因子>{<乘法运算符> <因子>}
<因子> ::= <标识符>|<无符号整数>| ‘(’<表达式>‘)’
<加法运算符> ::= +|-
<乘法运算符> ::= |/
普通的巴科斯范式
为表示方便:
表达式E、项X、因子Y、标识符b,无符号整数z,加法运算符A,乘法运算符C
E->AX|X|EAX
X->Y|XCY
Y->b|z|(E)
A->+|-
C->|/
项目集&识别活前缀的DFA

其中I1,I3,I10,I18存在归约-移进冲突。
求解所有非终结符的FOLLOW集合
Follow(S`)={#}
Follow(E)={#,),+,-}
Follow(X)={),+,-,#,,/}
Follow(Y)={),+,-,#,,/}
Follow(A)={b,z,(}
Follow©={b,z,(}
I1,I3,I10,I18的冲突可以消解,所以该文法是SLR(1)文法。
分析表
(0)S`->E
(1)E->AX
(2)E->X
(3)E->EAX
(4)X->Y
(5)X->XCY
(6)Y->b
(7)Y->z
(8)Y->(E)
(9)A->+
(10)A->-
(11)C->*
(12)C->

算法流程
main函数相当于总控程序,Analy_action函数对应action表,Analy_goto函数对应goto表。
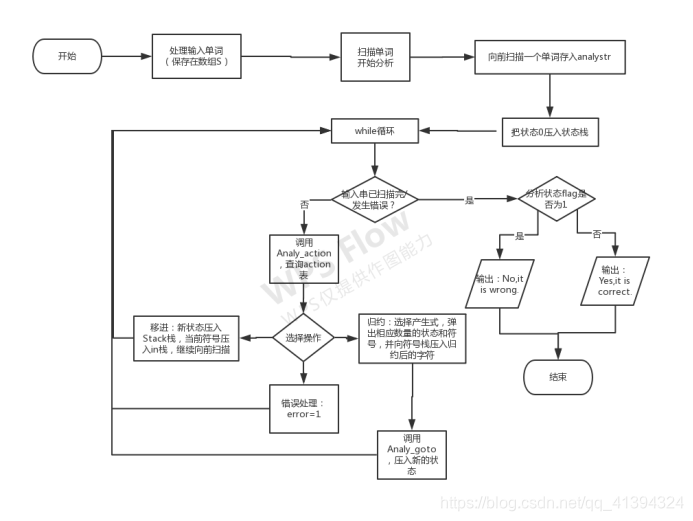
代码
#include <iostream>
#include <string>
#include<stack>
#include<vector>
using namespace std;
int flag=0; //记录分析状态
int p=-1;//指针作用 当前扫描单词的下标
stack <int> State; //状态栈
stack <string> in; //符号栈
int error=0;//错误处理 当置1时就报错结束分析
//分析的单词,s1为编码,s2为单词符号
struct strs
{
string s1,s2;
};
strs analystr;//当前分析的单词
//扫描下一个单词
void Advance(strs *S)
{
p++;
analystr = S[p];
}
//对应goto表,执行归约后,根据当前状态和符号确定哪一个状态应该进入State中
void Analy_goto()
{
int state=State.top(); //取当前栈顶状态
string si=in.top(); //当前符号栈的栈顶符号
char sii=si[0]; //string->char转换
switch(state)
{
//根据goto表,压入状态的代码
case 0:
if(sii=='E') State.push(1);
else if(sii=='X') State.push(3);
else if(sii=='Y') State.push(6);
else if(sii=='A') State.push(2);
else error=1;
break;
case 1:
if(sii=='A') State.push(17);
else error=1;
break;
case 2:
if(sii=='X') State.push(10);
else if(sii=='Y') State.push(6);
else error=1;
break;
case 3:
if(sii=='C') State.push(11);
else error=1;
break;
case 9:
if(sii=='E') State.push(14);
else if(sii=='X') State.push(3);
else if(sii=='Y') State.push(6);
else if(sii=='A') State.push(2);
else error=1;
break;
case 10:
if(sii=='C') State.push(11);
else error=1;
break;
case 11:
if(sii=='Y') State.push(15);
else error=1;
break;
case 14:
if(sii=='A') State.push(17);
else error=1;
break;
case 17:
if(sii=='X') State.push(18);
else if(sii=='Y') State.push(6);
else error&# 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 5813
5813











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









