




NVIDIA AI-AGENT夏季训练营
项目名称:AI-AGENT夏季训练营 — RAG智能药方分析专家
报告日期:2024年8月18日
项目负责人:Astron-fjh
Github项目链接:MediAssist-RAG-Chatbot
1. 项目概述
本项目旨在开发一个基于RAG(Retrieval-Augmented Generation)技术的智能对话机器人,能够从药单图片中提取信息,并结合大模型分析药品信息,推测病情,进一步为用户提供健康咨询。项目亮点包括OCR图像文本提取、结合NVIDIA LLaMA 3大模型的药品分析与病情推测、以及基于提取信息的智能对话功能。此系统特别适用于医疗场景中的辅助诊断和用户健康咨询。
2. 技术方案与实施步骤
2.1 模型选择
- 大模型选择:项目采用了NVIDIA
LLaMA 3-70B-Instruct大模型,因其在处理复杂语言任务(如医学文本解析、对话生成等)上表现优越。RAG模型的优势在于通过结合检索和生成技术,能够在对话过程中实时引入相关背景信息,从而提高对话的专业性和准确性。 - RAG模型的优势:RAG模型结合了检索和生成的能力,能够在回答问题时调用预训练知识库中的信息,从而提升回答的准确性与深度。这种模型非常适合需要在大规模数据基础上进行准确回答的场景,如药品信息的查询与病情推测。
2.2 数据的构建
- 数据构建过程:数据主要来源于药单图像,通过OCR技术提取文本信息。使用Tesseract OCR工具进行图像文字识别,并结合中文语言包优化识别效果。将提取的文本数据作为输入,传入大模型进行分析和生成对话。
2.3 功能整合
- 多模态功能整合:项目结合了OCR技术和大语言模型,OCR用于从图像中提取药品信息,而大语言模型则用于解析药品作用、推测病情与对话生成等功能。此多模态整合策略使系统能够处理复杂的输入,并输出符合预期的结果。
2.4 实施步骤
2.4.1 环境搭建
-
开发环境:使用Python作为主要开发语言,依赖库包括
pytesseract用于OCR,gradio用于创建前端界面,langchain用于模型集成。 -
安装Python库:首先配置NVIDIA的API密钥,接着安装Tesseract OCR和相关Python库。使用Tesseract支持中文的语言包以实现对药单中中文信息的提取。
# 安装Tesseract OCR库
pip install pytesseract
# 安装Gradio库,用于构建前端界面
pip install gradio
# 安装LangChain库,用于与NVIDIA API的集成
pip install langchain
# 安装langchain_core
pip install langchain_core
# 安装Pillow库,用于处理图像
pip install pillow
# 安装NVIDIA API的端点库
pip install langchain_nvidia_ai_endpoints
- 安装 Tesseract OCR
- 下载Tesseract安装包并安装。
- 从GitHub Tesseract 项目中下载中文语言包
chi_sim.traineddata(简体中文)或chi_tra.traineddata(繁体中文)。将该文件放置在Tesseract的tessdata目录中。默认情况下,这个目录通常在Tesseract-OCR安装目录下的tessdata文件夹中,例如D:\Tesseract-OCR\tessdata。 - 确保
pytesseract.pytesseract.tesseract_cmd指向Tesseract的可执行文件路径。如:
pytesseract.pytesseract.tesseract_cmd = r'C:\Program Files\Tesseract-OCR\tesseract.exe'
-
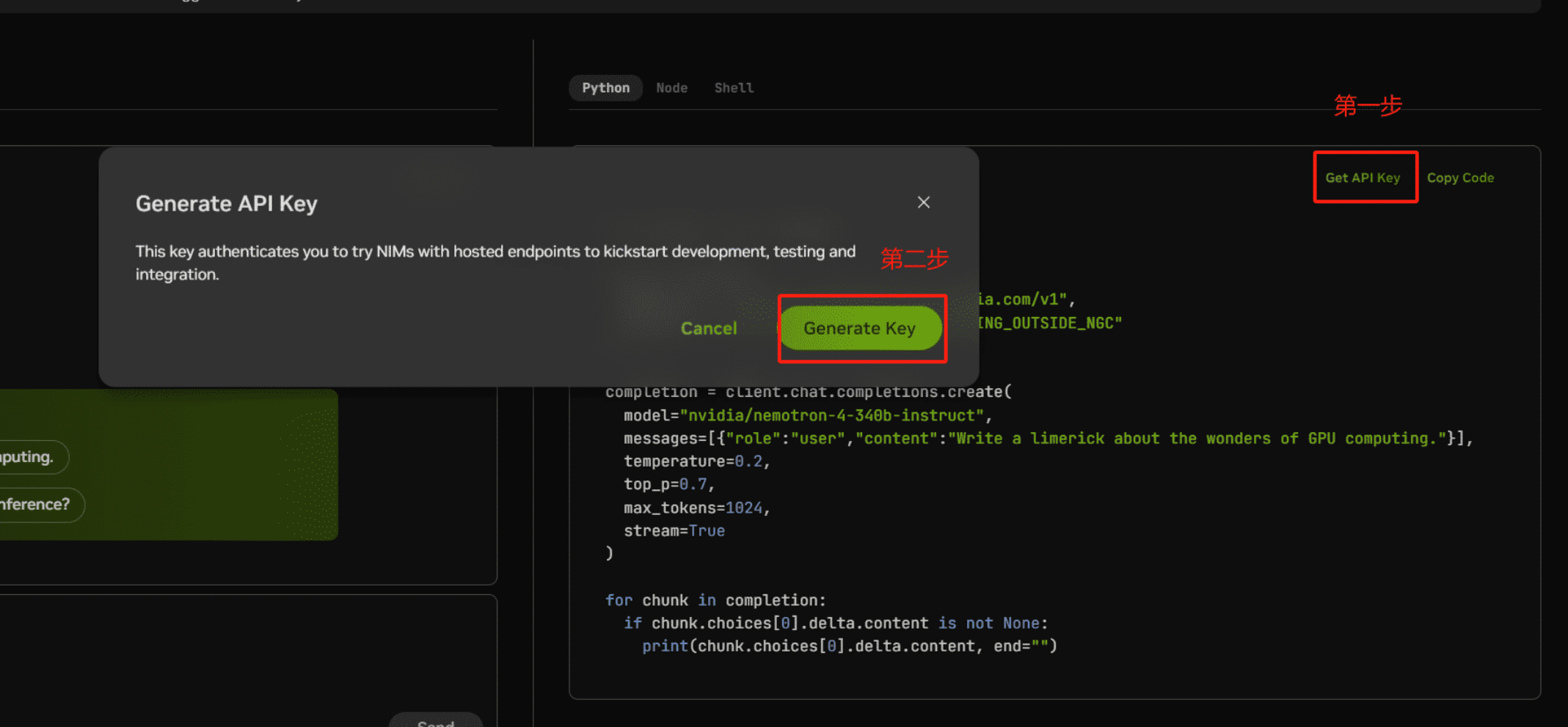
申请NIM的API Key,来调用NIM的计算资源
进入https://build.nvidia.com/microsoft/phi-3-vision-128k-instruct,点击Get API Key按钮,生成一个秘钥。
2.4.2 代码实现
-
导入工具包
import gradio as gr import pytesseract from PIL import Image from langchain_nvidia_ai_endpoints import ChatNVIDIA from langchain_core.prompts import ChatPromptTemplate from langchain.schema.<
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 594
594

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











