







目录
论文地址:
https://openaccess.thecvf.com/content_CVPR_2020/papers/Yu_Deformable_Siamese_Attention_Networks_for_Visual_Object_Tracking_CVPR_2020_paper.pdf
代码地址:
https://github.com/msight-tech/research-siamattn
创新点:
通过引入一种新的孪生网络注意机制来计算变形自我注意和交叉注意,提出了变形孪生注意网络,称为SiamAttn。此外,还设计了一个区域细化模块,用于计算注意特征之间的深度交叉相关,以实现更精确的跟踪。
一、 动机
目标模板不会在线更新,目标模板和搜索图像的特征在孪生网络体系结构中独立计算。
二、 主要贡献
①介绍了一种新的孪生网络注意机制,它联合计算变形自我注意和交叉注意。自我注意通过空间注意捕获丰富的上下文信息,同时通过通道注意选择性地增强相互依赖的通道特征。交叉注意聚合目标模板和搜索图像之间有意义的上下文相关性,这些相关性被自适应地编码到目标模板中以提高可辨别性。
②设计了一个区域细化模块,通过计算注意特征之间的深度交叉相关。这进一步增强了特征表示,通过生成对象的边界框和mask,实现更精确的跟踪。
③该方法在六个基准上表现出了先进的结果。表现优于SiamRPN++和SiamMask。
三、 主要内容
网络架构:
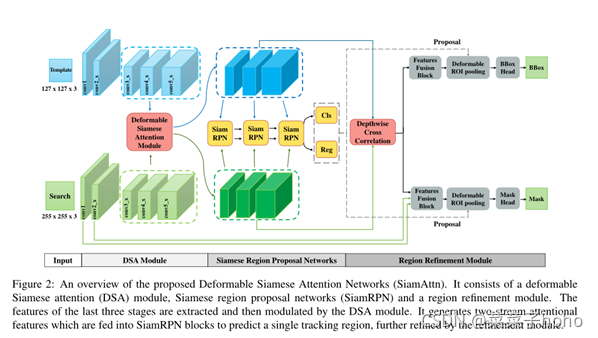
1、Siamese-based Trackers
该算法在SiamRPN++的基础上进行改进,主要引入了新的注意模块,注意模块能够增强学习到的目标对象和搜索图像的辨别性表示,从而提高跟踪精度和鲁棒性。
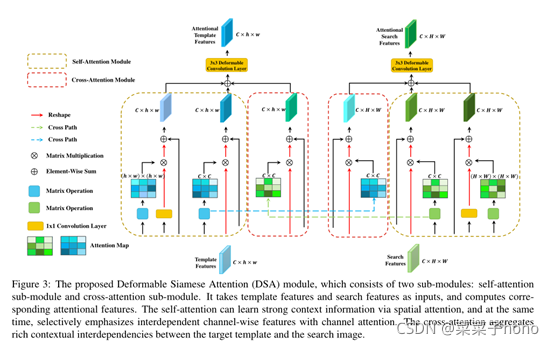
2、Deformable Siamese Attention Module
==DSA模块将一对孪生网络计算得到的卷积特征作为输入,并输出经过孪生注意机制调整处理的特征。DSA模块由两个子模块组成:自我注意子模块和交叉注意子模块。==我们将目标和搜索图像的特征映射表示为Z和X,特征形状为C×h×w和C×H×W。
Self-Attention
自我注意子模块关注两个方面,即通道和特殊位置。在整个跟踪过程中,目标类别是固定的。高级卷积特征的每个通道图通常响应特定的对象类。在所有通道中平等地对待特征会妨碍表示能力。类似地,受感受野的限制,在地图的每个空间位置计算的特征只能从局部patch块捕获信息。因此,从整体图像中了解全局背景至关重要。
在目标分支和搜索分支上分别计算通道自我注意和空间自我注意。假设输入特征是X ∈ RC×H×W,我们首先在X上应用两个卷积核为1 × 1的独立卷积层,分别生成查询特征Q和关键特征K,其中Q,K∈RC′×H×W , C′= 1/8C是缩减的通道数。然后将这两个特征重新整形为杠Q,杠K∈RC′×N这里N = H × W。我们可以生成一个空间自注意图Ass∈ RN×N通过矩阵乘法和column-wise softmax计算如下:
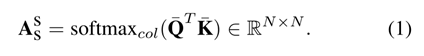
同时,将具有重塑操作的1×1卷积层应用于特征X以生成值特征V ∈ RC×N,该值特征与关注图相乘,然后加上带有剩余连接的重塑特征杠X∈RC×N如下:
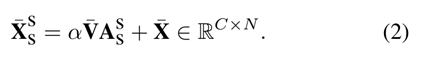
其中α是标量参数。然后,输出被重新整形回原来的大小,即Xss∈RC×H×W。
我们可以以类似的方式计算通道注意Asc和通道方向上的注意特征Xsc。需要注意的是:在计算通道自我注意和相应的注意特征时,query、key和value特征是直接从孪生网络计算得到的最初的卷积特征,没有使用1x1卷积。最终的自我注意特征Xs是通过简单的结合元素求和得到的空间和通道方向的注意特征实现的。
理解图:

目标部分与搜索部分同理。
Cross-Attention
==孪生网络通常在最后阶段进行预测,而来自两个分支的特征是分开计算的,但是可以相互补偿。==常见的是,多个对象同时出现,即使在跟踪过程中被遮挡。因此,对于搜索分支来说,学习目标信息是非常重要的,这使得它能够生成更有区别的表示,这有助于更准确地识别目标。同时,当来自搜索图像的上下文信息被编码时,目标表示可以更有意义。为此,我们提出了一个交叉注意子模块来从两个孪生分支学习这种相互信息,这反过来又允许这两个分支更加协作地工作。
具体来说,我们使用Z∈RC×h×w和杠X ∈ RC×H×W分别表示模板特征和搜索特征。以搜索分支为例,我们首先将目标特征Z重塑为杠Z∈RC×n这里n = h×w,然后通过执行与通道自我注意类似的操作来计算来自目标分支的交叉注意:
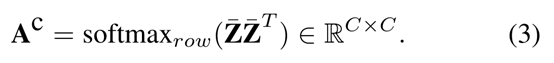
其中行方式的softmax在计算的矩阵上实现。然后从目标分支计算的交叉注意力被编码到搜索特征中:
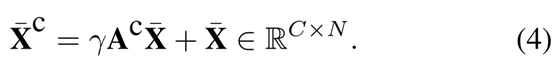
其中γ是标量参数,重塑特征Xc∈ RC×H×W是子模块的输出。
最后,将自我注意特征Xs和交叉注意特征Xc简单地与元素方向的和相结合,生成搜索图像的注意特征。目标图像的注意特征可以以类似的方式计算。
Deformable Attention
==CNN中像卷积或者池化都是固定的几何架构。假设物体是刚性的。==对于目标跟踪来说,复杂的几何变换建模是非常重要的,因为由于视点、姿态、遮挡等各种因素的影响,跟踪目标通常会产生较大的变形。提议的注意机制可以在某种程度上应对这些挑战。我们进一步引入了可变形的注意,以增强处理这种几何变换的能力。
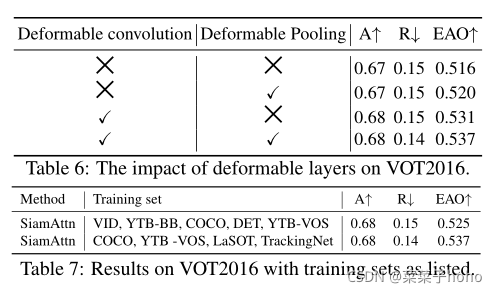
==可变形注意力可以在可变位置而不是固定位置对输入特征图进行采样,使它们关注具有变形的对象的内容。==因此,它特别适用于目标跟踪,目标的视觉外观可以随着时间的推移而发生显著变化。具体而言,3 × 3可变形卷积被进一步应用于计算的注意特征,产生更精确、更有辨别力和更鲁棒的最终注意特征。如图4所示,使用DSA模块,注意力特征的置信度图更准确地聚焦在感兴趣的对象上,使得对象对干扰物和背景更具辨别性。

Region Proposals
DSA模块输出目标图像和搜索图像的孪生注意特征。然后,==我们将三个孪生RPN块应用在注意力特征上来生成一组目标建议,并带有相应的边界框和分类得分,如图2所示。==具体来说,SiamRPN块是多个完全卷积层的组合,深度方向互相关,顶部有回归头和分类头。它采用一对卷积特征从孪生网络的两个分支输出,并输出密集的预测图。通过遵循SiamRPN++,我们对从最后三个阶段计算的孪生网络特征应用三个SiamRPN块,生成三个预测图,这些预测图通过加权和进一步组合。组合图的每个空间位置预测对应于预定义锚点的一组区域提议。然后选择分类得分最高的预测方案作为输出跟踪区域。
3、Region Refinement Module
我们进一步开发了区域细化模块,以提高预测目标区域的定位精度。==我们首先在两个注意特征之间应用跨多个阶段的深度交叉相关,生成多个相关图。然后,相关图被馈送到融合块,其中具有不同大小的特征图在空间域和信道域中对齐。==例如通过使用上采样或下采样,具有1 × 1卷积。然后,对准的特征被进一步融合(以元素方式求和),用于预测目标的边界框和掩模。==此外,我们进一步执行两个额外的操作:(1)我们将前两个阶段的卷积特征合并到融合特征中,该融合特征编码更丰富的局部细节信息用于掩码预测;(2)应用可变形RoI池化层来更精确地计算目标特征。包围盒回归和掩码预测通常需要不同级别的卷积特征。因此,我们生成空间分辨率为64 × 64的卷积特征用于掩码预测,空间分辨率为25 × 25的卷积特征用于包围盒回归。
注意,由于视觉对象跟踪是一项与类无关的任务,因此没有应用分类头。==边界框头部的输入分辨率为4 × 4。通过使用具有512个维度的两个完全连接的层,边界框头部预测4元组t = (tx,ty,tw,th)。类似地,掩模预测头的输入具有16 × 16的空间分辨率。通过使用四个卷积层和一个去卷积层,掩码头为跟踪对象预测了一个64 × 64的类不可知二进制掩码。与密集预测包围盒和遮罩的ATOM和SiamMask相比,我们的细化模块使用轻量级卷积头来预测单个跟踪区域的包围盒和掩码,这在计算上要高效得多。
4、Training Loss
模型以端到端的方式进行训练,其中训练损失是来自SiamRPN和区域细化模块的多个函数的加权组合:
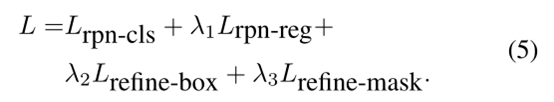
其中Lrpn-cls和Lrpn-lreg孪生网络RPN中的分类损失和回归损失。采用负对数似然损失和相应的平滑L1损失。同样的,在区域细化模块中,Lrefine-box和Lrefine-mask表示边界框回归的平滑L1损失和掩码分割的二元交叉熵损失。权重参数λ1、λ2和λ3用于平衡不同的任务,在我们的实现中根据经验设置为0.2、0.2和0.1。即:λ1=0.2、λ2=0.2、λ3=0.1
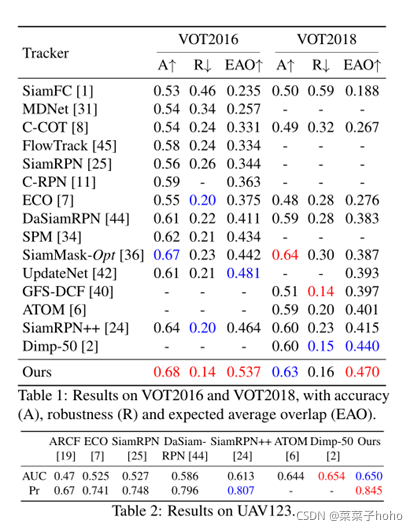
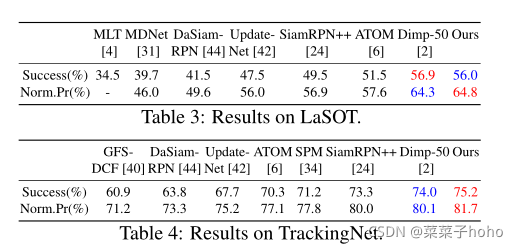
四、 实验结果
训练数据集:VID, YTB-BB, COCO, DET, YTB-VOS和COCO, YTB -VOS, LaSOT, TrackingNet
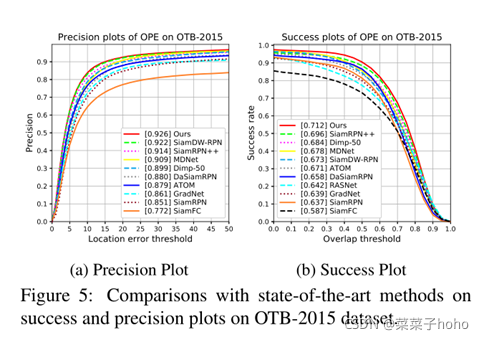
评测数据集:OTB-2015、UAV123、VOT2016、VOT2018、LaSOT、TrackingNet
五、 结论
提出了一种新的用于视觉目标跟踪的可变形孪生注意网络。介绍了一种由自我注意和交叉注意组成的可变形的连体注意机制。该方法在增强目标识别能力的同时,提高了对大范围外观变化、复杂背景和干扰的鲁棒性。此外,还设计了区域细化模块,进一步提高了跟踪精度。在六个基准上进行了广泛的实验,我们的方法获得了新的最先进的结果,具有实时的运行速度。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









