







前言
论文需要城市道路信息数据,OpenStreetMap平台是一个开源免费的全球地图信息平台,但是对于中国地图信息收录不是很全。我们可以通过API进行获取指定城市的交通道路信息。实验代码在Python3环境中跑,开放环境是Jupyter。
思路
首先获取城市ID,将城市ID进行转换成10位字符串,传递处理后的城市ID生成OSM文件。这里有关键的两个数据包
1、获取城市ID
<osm-script>
<query type="relation">
<has-kv k="boundary" v="administrative"/>
<has-kv k="name:zh" v="合肥市"/>
</query>
<print/>
</osm-script>
2、获取道路信息
<osm-script timeout="1800" element-limit="100000000">
<union>
<area-query ref="10位的城市id"/>
<recurse type="node-relation" into="rels"/>
<recurse type="node-way"/>
<recurse type="way-relation"/>
</union>
<union>
<item/>
<recurse type="way-node"/>
</union>
<print mode="body"/>
</osm-script>
代码
import requests
import re
def getCityRpadDataByOSM(cityName):
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/54.0.2840.99 Safari/537.36",
"Content-Type": "application/x-www-form-urlencoded"
}
data = '<osm-script><query type="relation"><has-kv k="boundary" v="administrative"/><has-kv k="name:zh" v="'+cityName+'"/></query><print/></osm-script>'
url = "http://www.overpass-api.de/api/interpreter"
response = requests.post(url, data = data.encode(), headers = headers)
# 利用正则表达式提取 id
match = re.search('<relation id="(.*?)">',response.text)
id = match.group(1)
# id 需要 10位
if id:
id = str(3600000000+int(id))
print(id)
else:
return
data2 = '<osm-script timeout="1800" element-limit="100000000"><union><area-query ref="'+id+'"/><recurse type="node-relation" into="rels"/><recurse type="node-way"/><recurse type="way-relation"/></union><union><item/><recurse type="way-node"/></union><print mode="body"/></osm-script>'
response2 = requests.post(url, data = data2, headers = headers)
if len(response2.text)>1000:
# 这里设置阀值是因为 网络问题会导致出现超时,丢掉这个包
with open(cityName+".osm","w",encoding='utf-8') as f:
f.write(response2.text)
getCityRpadDataByOSM("合肥市")
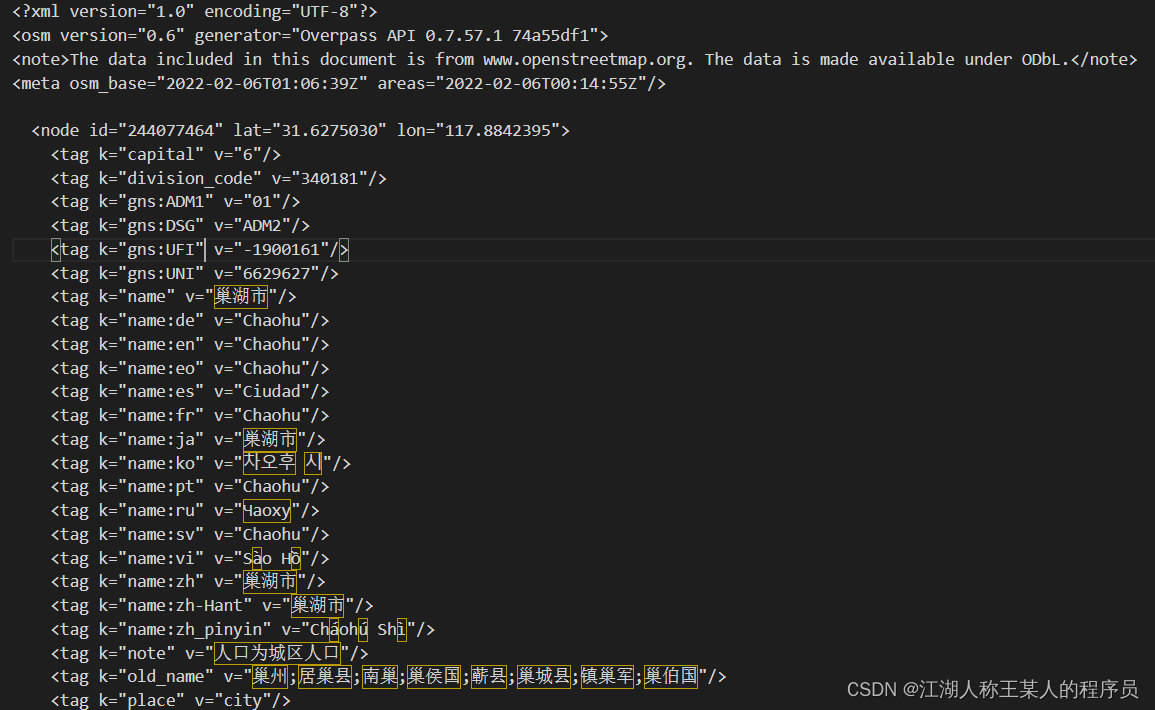
效果
根据代码会打印 3603288965,这是转换后的10位合肥城市ID
生成的“合肥市.osm”文件如果打开有timeout英文,说明是网络问题你超时了,你可以多试几次,最后成功的文件是这样的:
结语
参考博客:
利用OpenStreetMap获取城市路网数据
后面呢是需要提取XML数据中的信息,比如Node标签和Way标签中的信息,这个后面再记录,如果有需要可以评论,然后我把代码发出来。















 1026
1026











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











