







Mysql查询优化器

Mysql的查询优化器会优先查询缓存,若缓存没有命中,再去解析SQL,查询优化器还会优化SQL,即使where条件中的等值查询条件按照索引的顺序进行排序。
1.不在索引列上做任何操作
如果查询的列不是独立的,Mysql就不会走索引,不是独立的列是指索引的列不能是表达式或者是函数的参数。
例:索引中使用表达式,Mysql走的是全表扫描

 优化:
优化:
- 将索引列单独放在比较符号的一侧
- 索引列尽量不使用函数
2.尽量全值匹配
要查询的列尽量在联合索引中一一匹配,能在where条件中使用索引就尽量使用,这样可以提高key_len
例:要查询unique_id,name,holder,ip,建立(asset_number,unique_id,name,holder,ip)的联合索引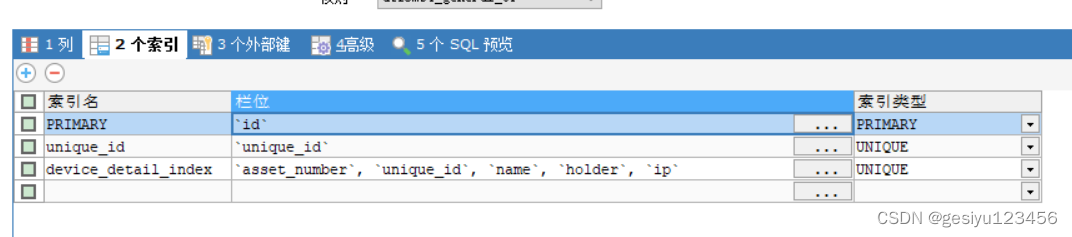


优化:
- 尽量在where中使用联合索引中的字段
3.最佳左前缀
Mysql的索引底层是B+树,所有的索引都在B+树的叶子节点并且是连续的,叶子节点会按照索引建的顺序进行构建,即最左边的索引会在叶子节点的最高层并按照升序进行排序,当第一个索引的列相等时,第二个索引才会小范围排序,这样就导致查询索引会首先匹配叶子节点的第一层,如果跳过第一层直接查询第二层是不会走索引的。

例:查询unique_id,NAME,holder,ip,建立(unique_id,NAME,holder,ip)的索引,查询条件直接根据name匹配,会使联合索引中的第一个索引失效。

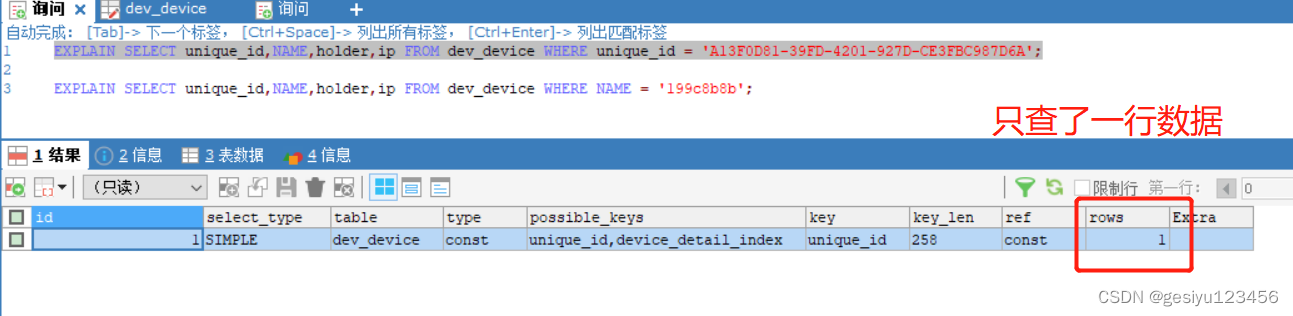

优化
- 建立了联合索引,尽量按照联合索引的最左边的索引进行匹配
- 若需要跳过最左边的列进行匹配,可单独建立索引
4.范围条件放最后(索引定义顺序的最后)
当查询条件中间有范围查询时,会使后面的索引失效
Mysql的查询优化器会使where条件中的查询条件按照索引的顺序进行排序,因此将要范围查询的索引列放到联合索引的最后是最合适的,因为前面的等值条件已经筛选出了小部分数据,过滤掉了无用的数据,因此范围查询放最后效率也是很高的
例:


优化:
- 将要范围查询的索引列放到联合索引的最后
5.尽量使用覆盖索引
要查询的列尽量全部建立联合索引,这样可以避免Mysql的B+树要查询索引中没有的列而进行的回表操作(甚至全表扫描),降低了IO的使用率。
例:要查询unique_id,name,holder,ip,就建立(unique_id,name,holder,ip)的联合索引



优化:
- 要查询的列全部建立联合索引
6.慎用不等于(!= <>)
Mysql的查询条件中用到了不等于(!= <>)会使索引失效,导致查询走全表扫描
7.Like要当心(%)
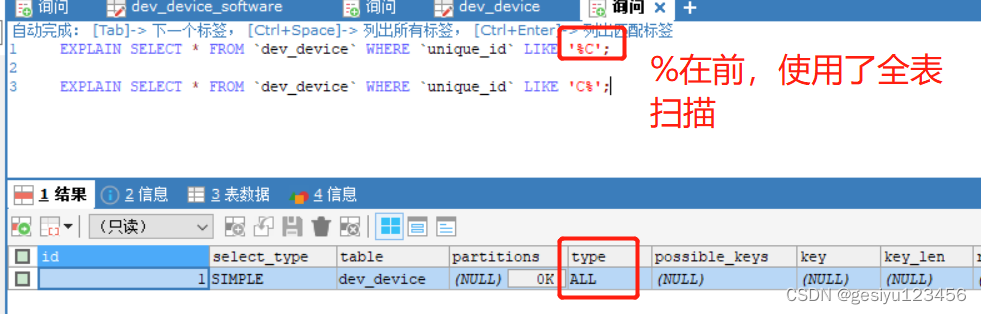
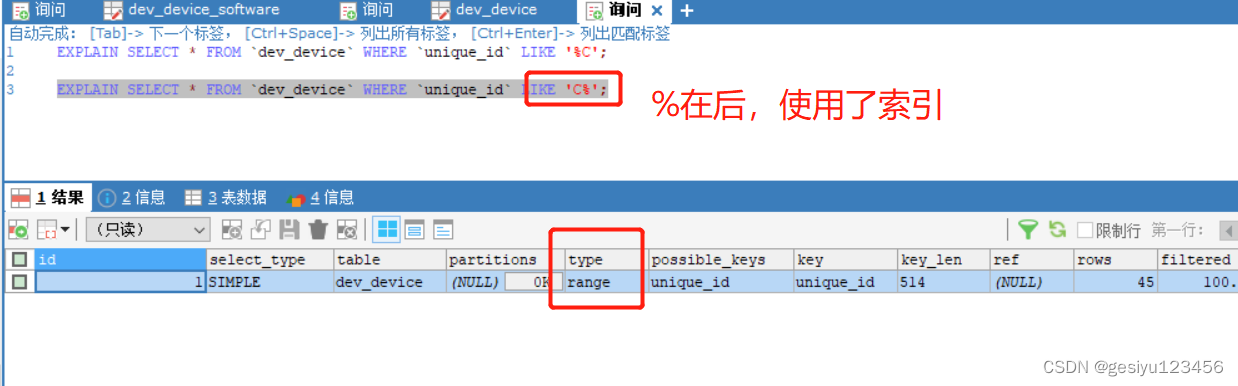
当Mysql的模糊查询 % 在前面时,会使索引列失效,走全表扫描
因为Mysql的底层是B+树,B+树叶子节点的索引数据是连续的(根据索引列升序排序),因此当 % 在前面会使B+树不知道怎样去使用索引查询,从而使索引失效
例:根据索引(unique_id)查询

8.字符串类型加引号
Mysql的查询优化器会自动进行类型转换,因此当查询条件不加引号时,会使索引列失效
9.使用or要注意
当Mysql查询时使用到了or,且其中一个不是索引列时,Mysql不会走索引,会走全表扫描
优化:
- 使用union all代替or
- 使用覆盖索引
10.排序要小心
当Mysql的排序(ASC,DESC)后使用了两个列,且两个列来自不同的索引,是不会走索引的。
当Mysql的排序既用到了ASC,又用到了DESC,Mysql是不会走索引的
优化:
- 排序要么都用DESC,要么都用ASC
- 当需要对多个列排序时,将这两个列按照顺序建立联合索引
11.主键按照顺序进行插入
最好避免随机的(不连续且值的分布范围非常大)聚簇索引,特别是对于I/O密集型的应用。例如,从性能的角度考虑,使用UUID来作为聚簇索引则会很糟糕,它使得聚簇索引的插入变得完全随机,这是最坏的情况,使得数据没有任何聚集特性
最简单的方法是使用AUTO_INCREMENT自增列。这样可以保证数据行是按顺序写入,对于根据主键做关联操作的性能也会更好
12.优化分页(LIMIT)
Mysql的分页语句LIMIT会将偏移量前的数据全部查询出来,然后抛弃掉不需要的数据,返回需要的数据,因此当LIMIT的偏移量很大时,代价是很高的。
例:


优化:
- 使用子查询,先查询到需要查询的id,然后进行关联查询















 4720
4720











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









