一、iconv库介绍
二、iconv_open()
#include <iconv.h>
iconv_t iconv_open (const char* tocode, const char* fromcode);
- 功能:为字符集转换分配描述符,该描述符适用于从字符编码fromcode转换为tocode
- 返回值:
- 成功:返回一个新分配的转换描述符
- 失败:设置errno并返回(iconv_t)-1
- 支持的errono有:
- EINVAL:不支持从fromcode到tocode的转换
- 参数的注意事项:
- 空的编码名称""等价于“char”,它表示与语言环境有关的字符编码
- 当tocode以字符串“//TRANSLTI”结尾时,音译被激活,意味着当一个字符不能在目标字符集中表示时,可以通过一个或几个看起来与原始字符相似的字符来近似表示
- 当tocode以字符串“//IGNORE”结尾时,目标字符集中无法表示的字符将被默认丢弃
- 返回值说明:
- 返回生成的转换描述符可以与iconv一起使用多次,一直保持有效,直到使用iconv_close()关闭为止
- 转换描述符包含转换状态,使用iconv_open()创建的为初始状态,使用iconv()函数可以修改描述符的状态
- 要将描述符返回到初始状态,请传递NULL给iconv()的inbuf参数
支持的编码
- fromcode和tocode以及允许的组合所允许的值取决于系统。对于libiconv库,所有组合均支持以下编码:
- European languages:ASCII, ISO−8859−{1,2,3,4,5,7,9,10,13,14,15,16}, KOI8−R, KOI8−U, KOI8−RU, CP{1250,1251,1252,1253,1254,1257}, CP{850,866,1131}, Mac{Roman,CentralEurope,Iceland,Croatian,Romania}, Mac{Cyrillic,Ukraine,Greek,Turkish}, Macintosh
- Semitic languages:ISO−8859−{6,8}, CP{1255,1256}, CP862, Mac{Hebrew,Arabic}
- Japanese:EUC−JP, SHIFT_JIS, CP932, ISO−2022−JP, ISO−2022−JP−2, ISO−2022−JP−1ISO−2022−CN−EXT
- Chinese:EUC−CN, HZ, GBK, CP936, GB18030, EUC−TW, BIG5, CP950, BIG5−HKSCS, BIG5−HKSCS:2001, BIG5−HKSCS:1999, ISO−2022−CN, ISO−2022−CN,-EXT
- Korean:EUC−KR, CP949, ISO−2022−KR, JOHAB
- Armenian:ARMSCII−8
- Georgian:Georgian−Academy, Georgian−PS
- Tajik:KOI8−T
- Kazakh:PT154, RK1048
- Thai:TIS−620, CP874, MacThai
- Laotian:MuleLao−1, CP1133
- Vietnamese:VISCII, TCVN, CP1258
- Platform specifics:HP−ROMAN8, NEXTSTEP
- Full Unicode:
- C99, JAVA
- UTF−7
- UTF−8
- UCS−2, UCS−2BE, UCS−2LE
- UCS−4, UCS−4BE, UCS−4LE
- UTF−16, UTF−16BE, UTF−16LE
- UTF−32, UTF−32BE, UTF−32LE
- Full Unicode,以uint16_t或 uint32_t表示(具有与机器相关的字节序和对齐方式)
- 取决于语言环境,以char或 wchar_t表示(具有与机器有关的字节序和对齐方式,并且其语义取决于操作系统和当前的LC_CTYPE语言环境方面)
- 当使用选项 -enable-extra-encodings配置时,它还提供了对一些额外编码的支持:
- European languages:CP{437,737,775,852,853,855,857,858,860,861,863,865,869,1125}
- Semitic languages:CP864
- Japanese:EUC−JISX0213, Shift_JISX0213, ISO−2022−JP−3
- Chinese:BIG5−2003 (实验性的)
- Turkmen:TDS565
- Platform specifics:ATARIST, RISCOS−LATIN1
三、iconv_open_into()
#include <iconv.h>
int iconv_open_into(const char *tocode, const char *fromcode
iconv_allocation_t *resultp);
- 功能:为该函数与iconv_open()函数的功能一样,也是将字符编码fromcode转换为tocode,但是其将转换描述符保存到参数3所指的内存中,iconv_allocation_t与iconv_t一样可以适用于其它函数的使用
- 兼容性:
- 此功能仅在GNU libiconv中实现,而在其他iconv实现中不实现。它没有标准支持
- 您可以通过(_LIBICONV_VERSION> = 0x010D)测试其存在
- 返回值:
- 成功:填充*resultp并返回0
- 失败:设置errno并返回(iconv_t)-1
- 支持的errono有:
- EINVAL:不支持从fromcode到tocode的转换
四、iconv_close()
#include <iconv.h>
int iconv_close (iconv_t cd);
- 功能:关闭参数所指定的转换描述符
- 返回值:
- 支持的errono有:
- EINVAL:不支持从fromcode到tocode的转换
五、iconvctl()
#include <iconv.h>
int iconvctl(iconv_t cd, int request, void *argument);
- 功能:在指定的转换描述符上进行查询,或者调整iconv()函数的行为,具体取决于请求值
- 兼容性:
- 此功能仅在GNU libiconv中实现,而在其他iconv实现中不实现。它没有标准支持
- 您可以通过(_LIBICONV_VERSION> = 0x0108)测试其存在
- 下面是request参数的允许值:
- ICONV_TRIVIALP:argument参数应该是一个int*,如果转换是微不足道的,argument参数将被设置为1,否则为0
- ICONV_GET_TRANSLITERATE:argument参数应该是一个int*,如果在转换中启用了音译功能(见上面iconv_open()函数介绍),argument参数将被设置为1,否则为0
- ICONV_SET_TRANSLITERATE:argument参数应该是一个const int*,如果argument非0表示启用转换中的音译功能,0值表示禁用音译功能
- ICONV_GET_DISCARD_ILSEQ:argument参数应该是一个int*,如果在转换中启用了“非法序列丢弃并继续”功能,argument参数将被设置为1,否则为0
- ICONV_SET_DISCARD_ILSEQ:argument参数应该是一个const int*,如果argument非0表示启用转换中的“非法序列丢弃并继续”功能,0值表示禁用该功能
- 返回值:
- 支持的errono有:
六、iconv()
#include <iconv.h>
size_t iconv(iconv_t cd, char **inbuf, size_t *inbytesleft, char **outbuf,
size_t *outbytesleft);
- 功能:执行字符集转换,从inbuf中读取inbytesleft字节然后转换保存到outbuf指向的内存中,最多写入outbytesleft字节
- 转换可能因为下面四个原因停止:
- ①在输入中遇到无效的多字节序列。在这种情况下,它将errno设置为EILSEQ并返回(size_t)-1。* inbuf指向无效的多字节序列的开头
- ②输入的字节序列已完全转换,即*inbytesleft已降至0。在这种情况下, iconv返回此调用期间执行的不可逆转换的次数
- ③输入中遇到不完整的多字节序列,输入字节序列在此之后终止。在这种情况下,它将errno设置为EINVAL并返回(size_t)-1。* inbuf指向不完整的多字节序列的开头。
- ④输出缓冲区不再有空间容纳下一个转换的字符。在这种情况下,它将errno设置为E2BIG并返回(size_t)-1
- (重点)在转换的过程中,inbuf和outbuf的指针会逐渐的向后偏移,因此inbuf和outbuf指针会改变,因此在操作iconv()之前最后定义两个临时指针分别指向inbuf和outbuf,然后使用这两个临时指针来调用iconv()函数(见下面的演示案例①)
- 当inbuf或outbuf为NULL时函数的表现
- 如果inbuf为NULL或*inbuf为NULL,但是outbuf不为NULL和*outbuf不为NULL。在这种情况下,iconv函数会尝试将cd的转换状态设置为初始状态,并将相应的移位序列存储在*outbuf处。 从*outbuf开始,最多将写入*outbytesleft个字节。如果输出缓冲区没有更多空间可用于此复位序列,则会将errno设置为E2BIG并返回(size_t)-1。否则,它将增加*outbuf并减少*outbytesleft 通过写入的字节
- 如果inbuf为NULL或*inbuf为NULL,且outbuf为NULL或*outbuf为NULL。在这种情况下,iconv函数会将cd的转换状态设置为初始状态
- 返回值:
- 成功:返回转换的所有字符中不可逆转换的字符数,可逆的不计算在内
- 失败:设置errno并返回(size_t)-1
- 支持的errono有:
- E2BIG:*outbuf 没有足够的空间
- EILSEQ:输入中遇到无效的多字节序列
- EINVAL:输入中遇到了不完整的多字节序列
七、演示案例①
- 演示功能:调用iconv_open()、iconv()、iconv_close()三个基本的接口,实现将一个字符串由utf-8编码格式转换为utf-16的格式
代码实现
//utf8_to_utf16.c
//https://github.com/dongyusheng/csdn-code/blob/master/iconv/utf8_to_utf16.c
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#include <iconv.h>
int main()
{
unsigned char *encTo = "UTF-16"; //要转换的编码格式
unsigned char *encFrom = "UTF-8"; //原编码格式
//新建一个转换分配描述符
iconv_t cd = iconv_open(encTo, encFrom);
if(cd == (iconv_t)-1)
{
perror("iconv_open");
return -1;
}
//转换的字符串
unsigned char inbuf[1024] = "CSDN 江南、董少";
size_t inbufLen = strlen(inbuf);
//用来保存转换后的字符串
size_t outbufLen = 1024;
unsigned char outbuf[outbufLen];
memset(outbuf, 0, outbufLen);
//因为iconv()函数会改变inbuf和outbuf指针,因此实现定义两个临时指针指向于这两,然后用这两个指针去操作
unsigned char *inbufSrc = inbuf;
unsigned char *outbufSrc = outbuf;
//转换之前打印一下原字符串和每个字符串的二进制值
printf("inbuf: %s, len: %ld\n", inbuf, strlen(inbuf));
printf("utf8:\n");
for(int i = 0; i < inbufLen; ++i)
{
printf("%02x ", inbuf[i]);
}
printf("\n\n\n");
//转换
size_t ret = iconv(cd, (char**)&inbufSrc, &inbufLen, (char**)&outbufSrc, &outbufLen);
if(ret == -1)
{
perror("iconv");
iconv_close(cd);
return -1;
}
//打印转换之后的字符串和每个字符串的二进制值(因为outbuf中间会有0,所以不能简单的使用strlen来计算长度)
printf("outbuf: %s len: %ld\n", outbuf, outbufSrc - outbuf);
printf("utf16:\n");
//不能以strlen(outbuf)作为参数2,因为outbuf中间有0,会导致for循环只打印部分的内容
for(int i = 0; i < (int)(outbufSrc - outbuf); ++i)
{
printf("%02x ", outbuf[i]);
}
printf("\n");
//关闭句柄
iconv_close(cd);
return 0;
}
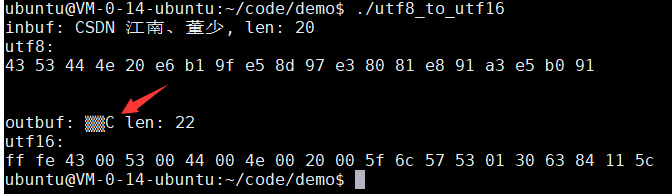
- 演示效果如下:
- 上面是转换之前的信息,下面是转换之后的信息
- 下面箭头处是程序打印的一处错误,因为将inbuf转换为utf-16存储之后,通过二进制可以看到其字符串中间有0值,但是printf()打印的时候遇到0就会终止打印,因此转换后的字符串不能通过printf()打印出来
八、演示案例②
- 演示功能:下面的功能与上面一样,不过这一次我们将iconv的各种接口进行封装
代码实现
//charset_converter.c
//https://github.com/dongyusheng/csdn-code/blob/master/iconv/charset_converter.c
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#include <errno.h>
#include <iconv.h>
typedef struct charset_converter
{
iconv_t cd; //字符转换描述符
int error; //错误码
} charset_converter_t;
/*****************************************************************************
函 数 名: charset_convert_init
功能描述 : 创建字符转换描述符,并封装charset_converter_t结构返回
输入参数 : const char*tocode ---> 目标编码格式
const char *fromcode ---> 源编码格式
输出参数 : 无
返 回 值: charset_converter_t * ---> 成功返回charset_converter_t*对象,失败返回NULL
调用函数 :
被调函数 :
修改历史 :
1.日 期 : 2020年6月10日
作 者 : 董雨生
修改内容 : 新生成函数
*****************************************************************************/
charset_converter_t *charset_convert_init(const char*tocode, const char *fromcode)
{
charset_converter_t *converter = (charset_converter_t*)malloc(sizeof(charset_converter_t));
if(converter == NULL)
{
perror("malloc");
return NULL;
}
converter->cd = (iconv_t)-1;
converter->error = 0;
converter->cd = iconv_open(tocode, fromcode);
if(converter->cd == (iconv_t)-1)
{
printf("iconv_open failed, errno = %d, %s\n",errno, strerror(errno));
free(converter);
return NULL;
}
return converter;
}
/*****************************************************************************
函 数 名: charset_convert_iconv
功能描述 : 执行字符集转换
输入参数 : charset_converter_t *converter --->charset_converter_t*对象
char **inbuf --->源编码缓冲区
size_t *inbytesleft --->源编码缓冲区中字符串的大小
char **outbuf --->目标编码缓冲区
size_t *outbytesleft --->目标编码缓冲区接收的最大大小
输出参数 : 无
返 回 值: int ---> 成功返回0,失败返回-1
调用函数 :
被调函数 :
修改历史 :
1.日 期 : 2020年6月10日
作 者 : 董雨生
修改内容 : 新生成函数
*****************************************************************************/
int charset_convert_iconv(charset_converter_t *converter, char **inbuf, size_t *inbytesleft,
char **outbuf, size_t *outbytesleft)
{
if(converter != NULL)
{
size_t ret = iconv(converter->cd, inbuf, inbytesleft, outbuf, outbytesleft);
if(ret == (size_t)-1)
{
converter->error = errno;
printf("iconv failed, errno = %d, %s\n", converter->error, strerror(converter->error));
switch(converter->error)
{
case E2BIG:
printf("E2BIG\n");
break;
case EILSEQ:
printf("EILSEQ\n");
break;
case EINVAL:
printf("EINVAL\n");
break;
default:
printf("unknown\n");
}
return -1;
}
return 0;
}
printf("converter error\n");
return -1;
}
/*****************************************************************************
函 数 名: charset_convert_close
功能描述 : 释放charset_converter_t结构
输入参数 : charset_converter_t *converter --->charset_converter_t*对象
输出参数 : 无
返 回 值: int ---> 成功返回0,失败返回-1
调用函数 :
被调函数 :
修改历史 :
1.日 期 : 2020年6月10日
作 者 : 董雨生
修改内容 : 新生成函数
*****************************************************************************/
int charset_convert_close(charset_converter_t *converter)
{
if((converter != NULL))
{
int ret = iconv_close(converter->cd);
if(ret == -1)
{
perror("iconv_close");
return -1;
}
free(converter);
return 0;
}
printf("converter error\n");
return -1;
}
int main()
{
//创建charset_converter_t结构
const char *encTo =
"UTF-16";
const char *encFrom = "UTF-8";
charset_converter_t *converter = charset_convert_init(encTo, encFrom);
if(converter == NULL)
return -1;
//要转码的字符串
char inbuf[1024] = "CSDN 江南、董少";
size_t inbufLen =strlen(inbuf);
//转码后的保存缓冲区
size_t outbufLen = 1024;
char outbuf[outbufLen];
memset(outbuf, 0, outbufLen);
//转码之前打印一下字符串的相关信息
printf("inbuf: %s, len: %ld\n", inbuf, strlen(inbuf));
printf("utf-8:\n");
for(int i = 0; i < inbufLen; ++i)
{
printf("%02x ", inbuf[i]);
}
printf("\n\n\n");
//开始转换
//因为iconv()函数会改变inbuf和outbuf指针,因此实现定义两个临时指针指向于这两,然后用这两个指针去操作
char *inbufSrc = inbuf;
char *outbufSrc = outbuf;
int ret = charset_convert_iconv(converter, &inbufSrc, &inbufLen, &outbufSrc, &outbufLen);
if(ret == -1)
return -1;
//转码之后打印一下字符串的相关信息
printf("outbuf: %s len: %ld\n", outbuf, outbufSrc - outbuf);
printf("utf16:\n");
for(int i = 0; i < (int)(outbufSrc - outbuf); ++i)
{
printf("%02x ", outbuf[i]);
}
printf("\n");
//释放关闭charset_converter_t结构
ret = charset_convert_close(converter);
if(ret == -1)
return -1;
return 0;
}
- 演示效果如下:与上面的演示案例①一致,但是不知道为什么会在前面补齐f

九、演示案例③









 本文深入解析Linux下的iconv库,涵盖iconv_open、iconv_close、iconv等核心函数的使用方法与细节,通过实例展示如何进行字符编码转换。
本文深入解析Linux下的iconv库,涵盖iconv_open、iconv_close、iconv等核心函数的使用方法与细节,通过实例展示如何进行字符编码转换。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











