






HDFS、MR、Kafka、Storm、Spark、Hbase、Redis原理图
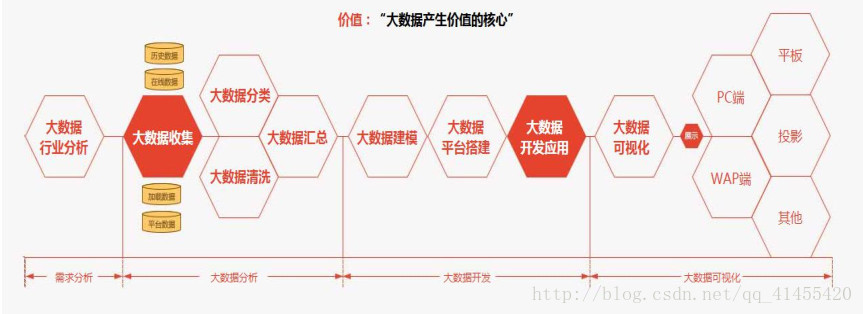
1、大数据分析阶段图
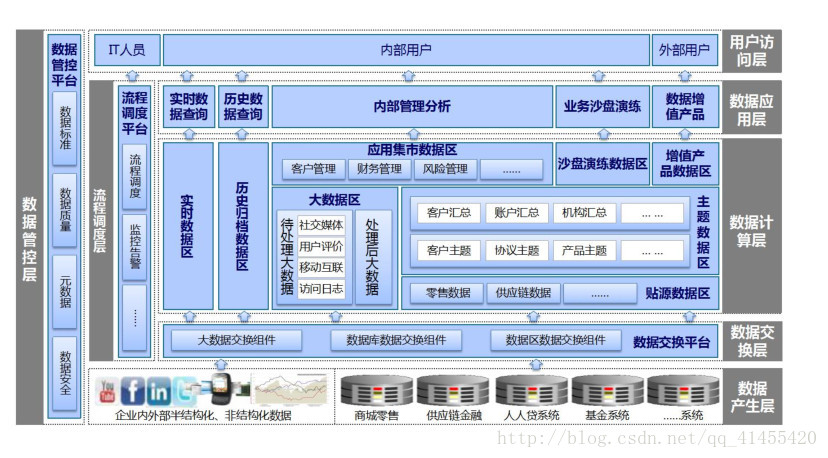
2、大数据分析平台总体架构
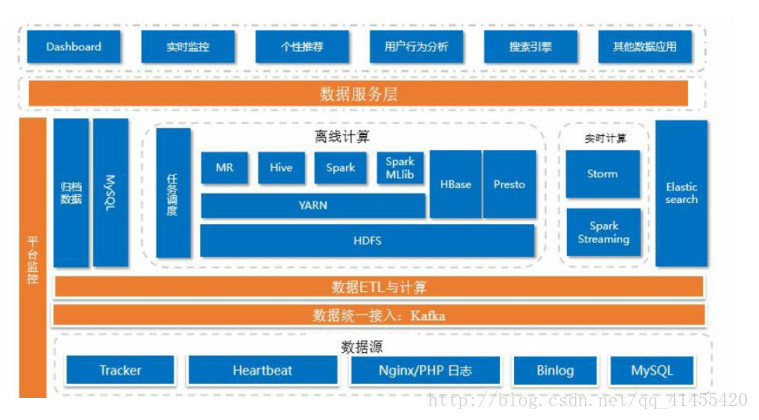
3、大数据分析平台技术栈
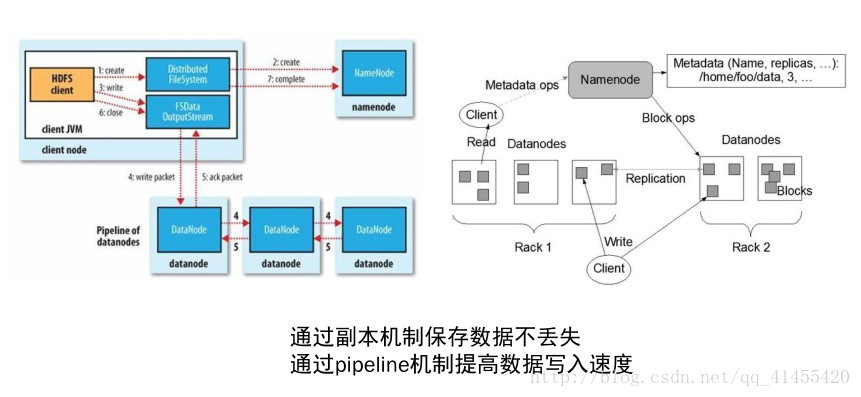
4、HDFS分布式存储原理图
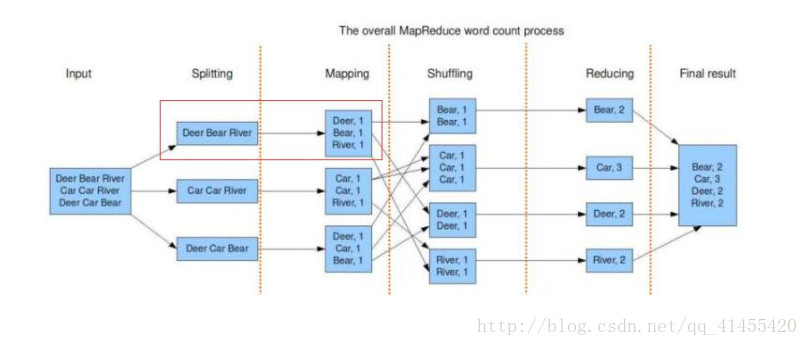
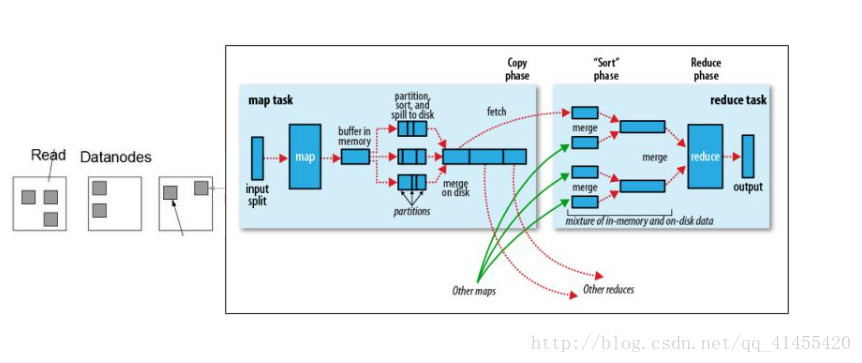
5、MR计算原理图
6、Kafka分布式消息队列原理图

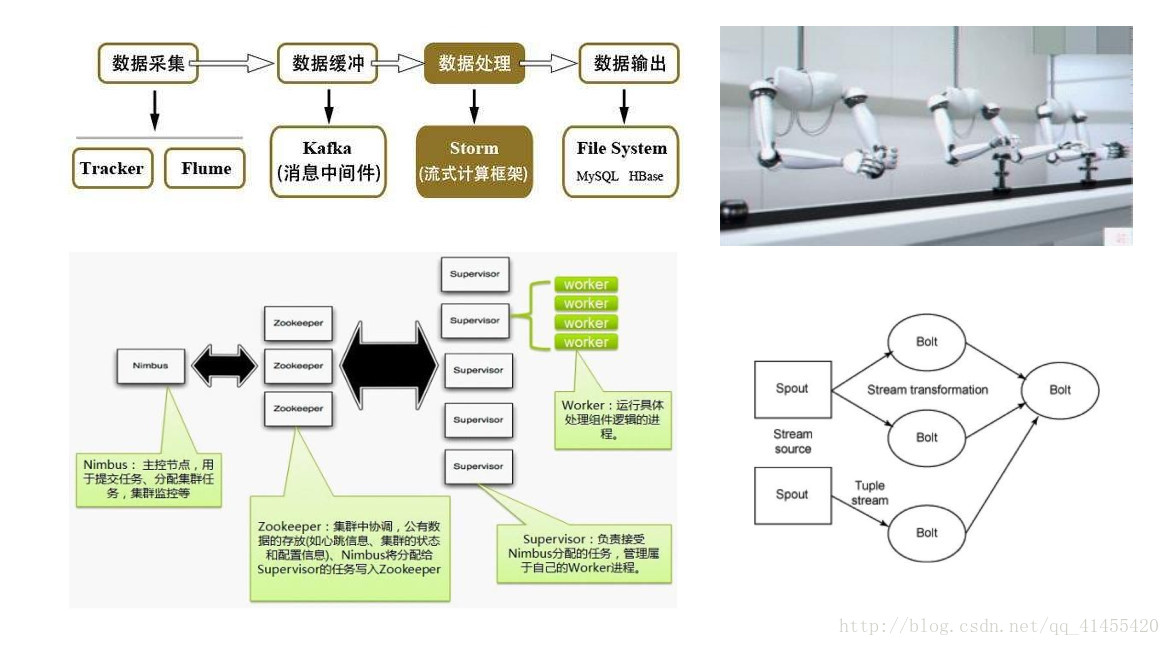
7、Storm分布式流式计算原理图
8、Spark内存计算原理图

9、Hbase列式存储数据库原理图

10、Redis

喜欢就点赞评论+关注吧

感谢阅读,希望能帮助到大家,谢谢大家的支持!

喜欢就点赞评论+关注吧
感谢阅读,希望能帮助到大家,谢谢大家的支持!
 1276
1276

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言
























