










创作本文章初衷:学术交流与技术进步
作者:白鹿(花名)
关于谷歌bert源码
请参考:https://github.com/google-research/bert.git
原始Bert中文预训练问题简述
1、原始bert预训练代码针对中文文本默认采用的是字粒度级别的预训练;
2、原始bert没有考虑到传统NLP中的中文分词问题;
3、原有基于WordPiece的分词方式会把一个完整的词切分成若干个子词,此处的子词具体到中文文本就是字,在生成训练样本时,这些被分开的子词(字)会随机被mask。
4、关于全词mask说明,在全词Mask中,如果一个完整的词的部分WordPiece子词(字)被mask,则同属该词的其他部分也会被mask
关于Bert 的vocab词表说明
vocab.txt 词表长度21128
# 词表头部位置(此处看一眼就非常清晰,就不过多描述了)
[PAD]
[unused1]
[unused2]
...
[unused99]
[UNK]
[CLS]
[SEP]
[MASK]
# 词表中间位置
荳
荷
荸
荻
荼
荽
莅
莆
莉
莊
莎
莒
莓
莖
莘
莞
莠
...
##拙
##拚
##招
##拜
##拟
##拡
##拢
##拣
##拥
##拦
##拧
##拨
##择
##括
# 词表尾部位置
##¥
##👍
##🔥
##😂
##😎
抛出问题:为什么在我们的中文vocab词表中即存在普通中文文本 莞,同时还存在 ##拨,这个问题不知道大家是否思考过?
- 详细解答:
注意“embeddings”一词是如何表示的:
[‘em’, ‘##bed’, ‘##ding’, ‘##s’]
原来的单词被分成更小的子单词和字符。这些子单词前面的两个#号只是我们的tokenizer用来表示这个子单词或字符是一个更大单词的一部分,并在其前面加上另一个子单词的方法。因此,例如,’ ##bed ’ token与’ bed 'token是分开的,当一个较大的单词中出现子单词bed时,使用第一种方法,当一个独立的token “thing you sleep on”出现时,使用第二种方法。
为什么会这样?
这是因为BERT tokenizer 是用WordPiece模型创建的。这个模型使用贪心法创建了一个固定大小的词汇表,其中包含单个字符、子单词和最适合我们的语言数据的单词。由于我们的BERT tokenizer模型的词汇量限制大小为30,000,因此,用WordPiece模型生成一个包含所有英语字符的词汇表,再加上该模型所训练的英语语料库中发现的~30,000个最常见的单词和子单词。这个词汇表包含个东西:
- 1、整个单词
- 2、出现在单词前面或单独出现的子单词(“em”(如embeddings中的“em”)与“go get em”中的独立字符序列“em”分配相同的向量)
- 3、不在单词前面的子单词,在前面加上“##”来表示这种情况
- 4、单个字符
要在此模型下对单词进行记号化,tokenizer首先检查整个单词是否在词汇表中。如果没有,则尝试将单词分解为词汇表中包含的尽可能大的子单词,最后将单词分解为单个字符。注意,由于这个原因,我们总是可以将一个单词表示为至少是它的单个字符的集合。
因此,不是将词汇表中的单词分配给诸如“OOV”或“UNK”之类的全集令牌,而是将词汇表中没有的单词分解为子单词和字符令牌,然后我们可以为它们生成嵌入。
因此,我们没有将“embeddings”和词汇表之外的每个单词分配给一个重载的未知词汇表标记,而是将其拆分为子单词标记[’ em ‘、’ ##bed ‘、’ ##ding ‘、’ ##s '],这些标记将保留原单词的一些上下文含义。我们甚至可以平均这些子单词的嵌入向量来为原始单词生成一个近似的向量。
声明:以上解析文本,本文作者在调研的时候参考了用户 weixin_39792475的一篇博客中的观点,本文作者对该博客比较认同,在此特别感谢以上博主的不吝赐教。
关于中文字粒度tokens
[‘[CLS]’, ‘进’, ‘入’, ‘10’, ‘月’, ‘份’, ‘,’, ‘日’, ‘本’, ‘新’, ‘增’, ‘确’, ‘诊’, ‘人’, ‘数’, ‘锐’, ‘减’, ‘。’, ‘[SEP]’, ‘着’, ‘大’, ‘量’, ‘[UNK]’, ‘新’, ‘奇’, ‘特’, ‘[UNK]’, ‘展’, ‘品’, ‘的’, ‘第’, ‘四’, ‘届’, ‘进’, ‘博’, ‘会’, ‘消’, ‘费’, ‘品’, ‘展’, ‘区’, ‘,’, ‘讲’, ‘述’, ‘着’, ‘这’, ‘样’, ‘的’, ‘[UNK]’, ‘美’, ‘美’, ‘与’, ‘共’, ‘[UNK]’, ‘故’, ‘事’, ‘。’, ‘[UNK]’, ‘新’, ‘奇’, ‘特’, ‘[UNK]’, ‘全’, ‘球’, ‘新’, ‘品’, ‘来’, ‘这’, ‘里’, ‘首’, ‘发’, ‘米’, ‘技’, ‘国’, ‘际’, ‘控’, ‘股’, ‘有’, ‘限’, ‘公’, ‘司’, ‘董’, ‘事’, ‘长’, ‘季’, ‘残’, ‘月’, ‘的’, ‘进’, ‘博’, ‘会’, ‘行’, ‘程’, ‘满’, ‘满’, ‘当’, ‘当’, ‘,’, ‘她’, ‘将’, ‘与’, ‘四’, ‘五’, ‘十’, ‘个’, ‘来’, ‘自’, ‘全’, ‘国’, ‘各’, ‘地’, ‘的’, ‘上’, ‘下’, ‘游’, ‘合’, ‘作’, ‘伙’, ‘伴’, ‘见’, ‘面’, ‘,’, ‘进’, ‘一’, ‘步’, ‘加’, ‘深’, ‘[SEP]’]
关于中文词粒度tokens
[‘[CLS]’, ‘进’, ‘入’, ‘10’, ‘月’, ‘份’, ‘,’, ‘日’, ‘##本’, ‘新’, ‘##增’, ‘确’, ‘##诊’, ‘人’, ‘##数’, ‘锐’, ‘减’, ‘。’, ‘[SEP]’, ‘着’, ‘大’, ‘量’, ‘[UNK]’, ‘新’, ‘##奇’, ‘##特’, ‘[UNK]’, ‘展’, ‘##品’, ‘的’, ‘第’, ‘四’, ‘届’, ‘进’, ‘##博’, ‘##会’, ‘消’, ‘##费’, ‘##品’, ‘展’, ‘##区’, ‘,’, ‘讲’, ‘述’, ‘着’, ‘这’, ‘样’, ‘的’, ‘[UNK]’, ‘美’, ‘美’, ‘与’, ‘共’, ‘[UNK]’, ‘故’, ‘##事’, ‘。’, ‘[UNK]’, ‘新’, ‘##奇’, ‘##特’, ‘[UNK]’, ‘全’, ‘##球’, ‘新’, ‘##品’, ‘来’, ‘这’, ‘里’, ‘首’, ‘发’, ‘米’, ‘##技’, ‘##国’, ‘##际’, ‘##控’, ‘##股’, ‘##有’, ‘##限’, ‘##公’, ‘##司’, ‘董’, ‘##事’, ‘##长’, ‘季’, ‘##残’, ‘##月’, ‘的’, ‘进’, ‘##博’, ‘##会’, ‘行’, ‘##程’, ‘满’, ‘满’, ‘当’, ‘##当’, ‘,’, ‘她’, ‘将’, ‘与’, ‘四’, ‘五’, ‘十’, ‘个’, ‘来’, ‘自’, ‘全’, ‘##国’, ‘##各’, ‘##地’, ‘的’, ‘上’, ‘##下’, ‘##游’, ‘合’, ‘##作’, ‘伙’, ‘##伴’, ‘见’, ‘面’, ‘,’, ‘进’, ‘一’, ‘步’, ‘加’, ‘深’, ‘[SEP]’]
中文词粒度mask_tokens
[‘[CLS]’, ‘进’, ‘入’, ‘10’, ‘月’, ‘份’, ‘,’, ‘日’, ‘##本’, ‘新’, ‘##增’, ‘确’, ‘##诊’, ‘人’, ‘##数’, ‘锐’, ‘减’, ‘。’, ‘[SEP]’, ‘着’, ‘大’, ‘量’, ‘[UNK]’, ‘新’, ‘##奇’, ‘##特’, ‘[UNK]’, ‘展’, ‘##品’, ‘的’, ‘第’, ‘四’, ‘届’, ‘进’, ‘##博’, ‘##会’, ‘消’, ‘##费’, ‘##品’, ‘展’, ‘##区’, ‘,’, ‘讲’, ‘述’, ‘着’, ‘这’, ‘样’, ‘的’, ‘[UNK]’, ‘美’, ‘美’, ‘与’, ‘共’, ‘[UNK]’, ‘[MASK]’, ‘[MASK]’, ‘。’, ‘[UNK]’, ‘新’, ‘##奇’, ‘##特’, ‘[UNK]’, ‘全’, ‘##球’, ‘新’, ‘##品’, ‘来’, ‘这’, ‘里’, ‘首’, ‘发’, ‘[MASK]’, ‘[MASK]’, ‘##oh’, ‘[MASK]’, ‘##ㄉ’, ‘[MASK]’, ‘##有’, ‘[MASK]’, ‘[MASK]’, ‘##司’, ‘[MASK]’, ‘[MASK]’, ‘[MASK]’, ‘[MASK]’, ‘[MASK]’, ‘[MASK]’, ‘的’, ‘进’, ‘##博’, ‘##会’, ‘行’, ‘##程’, ‘满’, ‘满’, ‘当’, ‘##当’, ‘,’, ‘她’, ‘将’, ‘与’, ‘四’, ‘五’, ‘十’, ‘个’, ‘来’, ‘自’, ‘全’, ‘##国’, ‘##各’, ‘##地’, ‘的’, ‘上’, ‘##下’, ‘##游’, ‘合’, ‘##作’, ‘伙’, ‘##伴’, ‘见’, ‘面’, ‘,’, ‘进’, ‘一’, ‘步’, ‘加’, ‘深’, ‘[SEP]’]
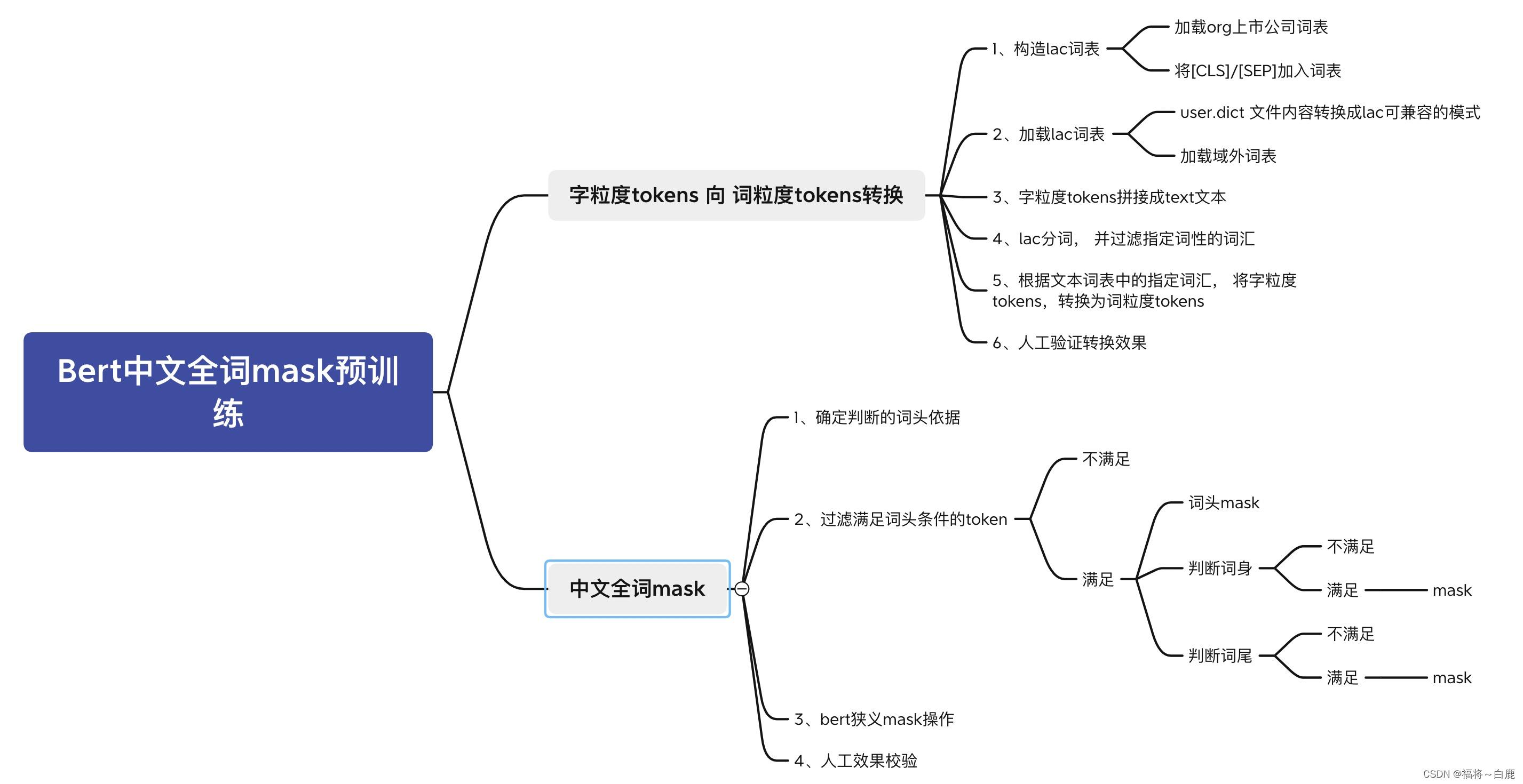
关于中文全词mask预训练核心点
1、词粒度tokens;
2、中文全词mask部分;
特别说明:本人在此对bert预训练, 第一阶段的源码进行了调整,整体调整代码,大约160行左右,在此就不贴了,我们需要尊重下公司版权问题,谢谢各位,能看到此处的朋友,赶紧关注、点赞、收藏吧, 同道中人。
脑图逻辑















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









