







基于Cassandra的分布式存储数据一致性算法研究 技术报告
目录
一、分布式数据一致性概述
1.1 CAP定理
CAP定理由加州大学伯克利分校Eric Brewer教授提出,指的是在一个分布式系统中,Consistency(一致性)、 Availability(可用性)、Partition tolerance(分区容错性)三者不可兼得。并且由于分布式系统必须进行网络分区,将系统部署在不同的数据中心、节点上,故而分区容错性也就是CAP定义中的P必须实现。所以,当前的分布式系统只能在C和A,也就是一致性和可用性之间做出权衡与取舍,不存在完全的CAP三者兼顾的分布式系统。
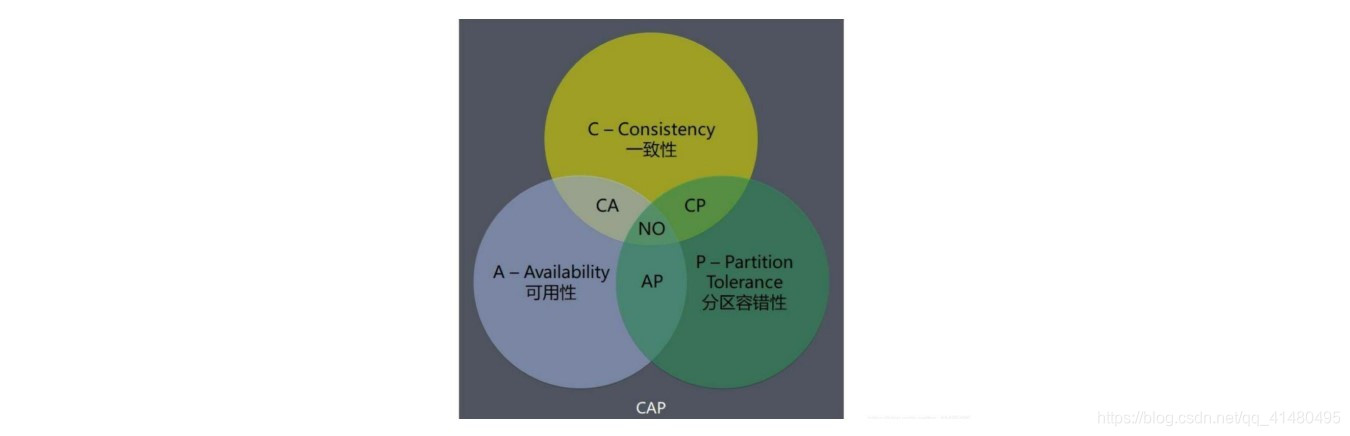
与关系型数据库ACID理论相比,CAP理论的一致性针对的是数据副本,保证同样的一个数据在集群中所有不同服务器上的副本都是相同的,并且达到这种一致性的数据复制需要延迟时间;而ACID的一致性针对的是提交的事务,在事务开始之前和事务结束以后,关系型数据库的完整性约束不能破坏,也就是说数据库事务不能破坏数据的完整性以及业务逻辑上的一致性。
1.2 BASE理论
在CAP定理提出以后,由于存在一部分观点将分布式系统的可用性与一致性简单的分隔开来,形成了错误的观点,eBay的工程师在长期的分布式系统设计与实践之中提出了BASE理论。BASE理论主要阐述了再分布式系统中的可用性与一致性并不是简单的0和1的关系,而是0%到100%的渐进式关系。核心观点是我们虽然无法在分布式系统中始终保持强一致性,但是可以根据具体的业务特点、系统性能需求来调节数据一致性的级别,最终使得系统达到一个最终一致性的阶段,只是达到这个步骤所产生的延迟存在差异。
BASE理论的内容如下
- 基本可用(Basically Available)
基本可用是指系统即时出现短暂故障,但仍然能够持续提供服务,与正常系统相比只存在性能上的损失和功能上的损失。性能上的损失主要表现在延迟时间增大,功能上的损失则是例如电商网站秒杀活动时引导部分用户降级,以确保购物系统稳定性。 - 软状态(Soft State)
软状态是指分布式系统在维护各个节点一致性时的中间状态,这种状态并不影响分布式系统的可用性。具体是指不同节点在同步各自数据期间存在的一种延迟状态 - 最终一致性(Eventually Consistent)
最终一致性是指分布式系统在经过了软状态的数据同步更新后,能在延迟时间结束后达到数据一致的状态,Cassandra自身的实现就是采用最终一致性的策略。
综上,BASE理论否定了对于CAP定理错误的解读,适用于大规模分布式系统,为系统的高可用、易于拓展的需求奠定理论基础。
1.3 分布式数据服务中的不同一致性级别
根据CAP定理和BASE理论,分布式系统在提供数据服务时需要考虑到业务的需求从而设置一致性级别。目前研究表明的一致性级别主要分为:强一致性、弱一致性、最终一致性。
- 强一致性
强一致性要求最为严格,也最为符合用户直觉,任何用户在使用系统时,要求系统写入的数据直接同步更新到所有节点,用户读取数据时保证就是当时写入的值。也就是说任何写操作都立即进行同步,任何读进程都是最新的值。这种策略适用于安全性需求很高的场景如银行存取款业务。
但强一致性也会导致可用性非常低,对系统性能影响极大。 - 弱一致性
弱一致性是指分布式系统在接收到请求后立即返回,接下来再执行存放数据的同步和更新操作,不承诺立即可以读到写入的值,也不具体承诺多久之后数据能够达到一致,但会尽可能保证到某个时间级别后,数据能够达到一致状态。 - 最终一致性
最终一致性是弱一致性的一个特例,系统会保证在一定时间内,能够达到一个数据一致的状态。
这种方式在分布式系统中得到应用,类似Cassandra的AP型分布式数据库都采用最终一致性的策略。
二、Cassandra初探
2.1 Cassandra概述
Cassandra是一套于2008年开源的NoSQL分布式系统,最初由facebook开发,集BigTable的数据模型与Dynamo的完全分布式架构于一身。源代码由Java编写,运行环境则需要JDK1.8和Python2.7以上(cassandra-3.1.1),可以在Apache的开源站点获取Cassandra。

Cassandra名称来源于古希腊神话的凶事预言家,logo自然而然的设计为一只放光的预言之眼,个人理解的寓意是“提前预见不可靠分布式系统中的故障”。确实,cassandra官方文档首页就声明其特点:“Manage massive amounts of data, fast, without losing sleep”,管理海量数据而不存在单点故障。
不存在任何单点故障、线性拓展、去中心化,构成了Cassandra的强大优势。
2.2 Cassandra数据分区策略
Cassandra使用令牌环进行一致性哈希,将每个节点映射到连续哈希环上的一个或多个令牌来对所存储数据进行分区存放,并且受具体键空间的副本数量策略影响。
相比朴素的一致性哈希,Cassandra的一致性哈希策略将所有节点根据哈希值形成环,环的哈希值取值范围为[0~2^32-1],n个数据节点随机分布在哈希环上,形成n个range,即哈希值范围,再将所存储的数据进行一致性哈希,分布在哈希环上。每个range哈希值范围都有一个主节点与之对应,在键空间副本数量为1时,数据会保存到哈希环所在range范围内的主节点上,副本数量增加时,则会依次向后递推保存在副本数量的不同节点上。 这种方式与直接进行哈希取模相比的优势在于提升了Cassandra的伸缩性。在简单的哈希取模中,添加、删除一个节点的数据移动时间复杂度可以达到O(n)级别,而在令牌环一致性哈希内,具有M个数据记录、N个节点的增加、删除节点操作时间复杂度仅为O(M/N),在性能上有很大提升。
这种方式与直接进行哈希取模相比的优势在于提升了Cassandra的伸缩性。在简单的哈希取模中,添加、删除一个节点的数据移动时间复杂度可以达到O(n)级别,而在令牌环一致性哈希内,具有M个数据记录、N个节点的增加、删除节点操作时间复杂度仅为O(M/N),在性能上有很大提升。
但是这样的设计也存在一个问题,就是假如两个物理节点靠的很近,则会导致一台机器拼命工作,另外一台机器饥饿的问题,同样的还会存在机器处理能力不均匀等问题,故无法避免负载上的不均衡。所以,Cassandra的设计中增加了虚拟节点这一负载均衡策略,即每个物理节点多个令牌,映射到环上多个虚拟节点,以实现负载均衡。
2.3 cassandra数据一致性策略
2.3.1 逆熵机制
在cassandra中依靠Gossip协议并配合Merkle Tree检查机制实现逆熵,在杂乱无章的通信之中寻求最终的一致,节点之间定期互相检查数据对象的一致性。并且,Gossip是一种P2P的点对点对等协议,不存在主节点,每个节点靠线程支配每隔一秒使用TCP协议随机向其他节点交换信息,交换的信息包括自己的信息和他们所知道的信息,依靠版本号判断消息是否更新,用新消息覆盖掉旧消息。cassandra集群内节点故障检测和恢复都是通过Gossip实现。
Cassandra群集中的每个节点都独立并定期运行Gossip任务。集群中的每个节点每秒完成以下任务:
- 更新本地节点的心跳版本,并构造集群内每个节点状态的本地视图;
- 在集群中随机选择一个其他节点来交换带有的信息;
- 在一定概率下尝试与任何无法到达的节点(如果存在)交换信息;
- 若步骤2不发生,则尝试与任意一个seeds节点交换信息。
整体上,Gossip算法在运行时可以退化成一颗多叉树,容易得出其算法执行时间复杂度为O(logN),N为节点数量,高效实现了最终一致性。
而Merkle Tree则是构建一颗叶子全部是节点存储数据的哈希值的哈希树,所有分支结点都是子结点所存放哈希值的哈希值。在节点数据一致性比较中直接进行哈希树根结点比较,如果数据一致,则所有叶子结点值相同,自底向上依次生成的哈希值也相同,故两个节点生成Merkle Tree的根结点也相同,如果根结点不同,则可以快速的顺藤摸瓜找到不同的叶子,也就可以快速找到不一致的数据进行修复,最终实现在不同节点数据比对中实现最终一致性。
2.3.3 数据写入过程
Cassandra是一个写优先的分布式存储系统,写入、更新、删除都采用写入操作,牺牲部分读性能换取高性能写。
数据写入步骤如下:
- 将数据的操作日志写到磁盘CommitLog,即Cassandra.yaml配置文件指定的提交日志文件路径下;
- 将数据写入Memtable,即处在内存中的table数据结构;
- 将Memtable数据刷入磁盘中的data路径,形成真实存储的SSTable文件;
- 将多个SSTable文件执行合并操作,完成写入。

2.3.4 可调节的读写一致性
可调节的读写一致性是Cassandra的一大优势,可以根据业务需求分别设置不同的读写一致性以适应不同场景。
| 级别 | 描述 |
|---|---|
| ONE | 只有单个副本必须响应 |
| TWO | 两个副本必须响应 |
| THREE | 三个副本必须响应 |
| QUORUM | 多数副本(n / 2 +1)必须响应 |
| ALL | 所有副本都必须响应 |
| ANY | 仅写操作支持,单副本响应,一致性最低,可用性最高 |
除上表所示内容之外,还存在诸如LOCAL_QUORUM、EACH_QUORUM、LOCAL_ONE三个级别,这三种情况在多数据中心情况下使用,不做赘述。
Cassandra默认的一致性级别为ONE,可以通过cqlsh工具的CONSISTENT命令来进行查看
 针对经常性使用的QUORUM策略,接下来引入NWR策略进行讲解。
针对经常性使用的QUORUM策略,接下来引入NWR策略进行讲解。
2.3.4 NWR策略
NWR策略广泛应用于NoSQL分布式系统的一致性级别控制中,其中N代表系统内同一份数据在系统中所具有的副本数,W表示完成一次写操作需要成功写入的最小副本数,R则代表一次读操作需要成功读取的最小副本数。
当W+R>N时,例如有5个副本,一个写请求写入3个副本,一次读请求读出3个副本,满足W+R>N。效果图如下:
 由于读写必定发生重叠,显然在读请求时至少会读出一个写请求写入的数据,故当W+R>N时系统是满足强一致性的。
由于读写必定发生重叠,显然在读请求时至少会读出一个写请求写入的数据,故当W+R>N时系统是满足强一致性的。
而当W+R<=N时,例如W=2、R=3、N=5,则可能会出现如下图所示读写不一致情况:
 此时写集合为{Node1,Node3},读集合为{Node2,Node4,Node5},没有产生重叠,导致读写不一致。
此时写集合为{Node1,Node3},读集合为{Node2,Node4,Node5},没有产生重叠,导致读写不一致。
Cassandra基于NWR策略实现了QUORUM一致性策略,要求副本中的多数派(N/2+1)进行响应之后才返回成功。但是基于QUORUM机制还不能完全实现强一致性,在Cassandra中依靠读修复(READ REPAIR)机制进行实现。
2.4 CQL操作Cassandra
CQL为Cassandra Query Language的缩写,目前作为Cassandra默认并且主要的交互接口。CQL和SQL语法很相似,主要特性在于列不用预先定义,可以随时增删列,在表(列族)中增加字段,这个特性非常适合于分布式系统,保证了高可用;并且支持集合类型list、map、set,以及任意字节blob,计数器列count,时间戳timestamp等数据类型。
值得注意的是,CQL语句在创建键空间时指定了副本的复制策略和副本数量,如以下代码:
CREATE KEYSPACE test_keyspace WITH replication = {'class' : 'SimpleStrategy', 'replication_factor': 3};
该行代码指定了副本策略为SimpleStrategy,即为不考虑数据中心的简单策略,适合单数据中心,而replication_factor为3则声明该键空间在3个节点保存副本。
可以通过Cassandra的cqlsh工具通过配置文件指定端口(默认9042)连接到Cassandra数据库,当然也可以通过各种图形化工具如TablePlus连接数据库。
针对使用CQL语句对Cassandra进行增删改查的操作,可以通过com.datastax.cassandra的Java客户端驱动编程实现,实例程序如下:
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章















 162
162











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









