







此文章主要是结合哔站shuhuai008大佬的白板推导视频:马尔科夫决策过程_107min
全部笔记的汇总贴:机器学习-白板推导系列笔记
一、背景介绍
Random Variable: X Y X ⊥ Y X\;\;Y\;\;X\bot Y XYX⊥Y
Stochastic Process: { S t } t = 1 ∞ \{S_t\}_{t=1}^\infty {
St}t=1∞
Markov Chain/Process,具有Markov Property的随机过程: P ( S t + 1 ∣ S t , S t − 1 , ⋯ , S 1 ) = P ( S t + 1 ∣ S t ) P(S_{t+1}|S_t,S_{t-1},\cdots,S_1)=P(S_{t+1}|S_t) P(St+1∣St,St−1,⋯,S1)=P(St+1∣St)
State Space Model:(HMM,Kalman Filter,Particle Filter)Markov Chain+Observation
Markov Reward Process:Markov Chain+Reward
Markov Decision Process:Markov Chain+Reward+Action
S : s t a t e s e t → S t A : a c t i o n s e t , ∀ s ∈ S , A ( s ) → A t R : r e w a r d s e t → R t , R t + 1 S:state\;set\rightarrow S_t\\A:action\;set,\forall s\in S,A(s)\rightarrow A_t\\R:reward\;set\rightarrow R_t,R_{t+1} S:stateset→StA:actionset,∀s∈S,A(s)→AtR:rewardset→Rt,Rt+1
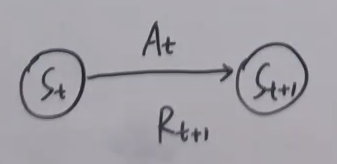
二、动态特性
Markov Chain: S S S
MRP: S , R S,R S,R
MDP: S , A ( s ) , R , P ( 动 态 特 性 ) S,A(s),R,P(动态特性) S,A(s),R,P(动态特性)

P : p ( s ′ , r ∣ s , a ) ≜ P r { S t + 1 = s ′ , R t + 1 = r ∣ S t = s , A t = a } P:p(s',r|s,a)\triangleq Pr\{S_{t+1}=s',R_{t+1}=r|S_t=s,A_t=a\} P:p(s′,r∣s,a)≜Pr{
St+1=s′,Rt+1=r∣St=s,At=a}
状态转移函数:
P ( s ′ ∣ s , a ) ∑ r ∈ R P ( s ′ , r ∣ s , a ) P(s'|s,a)\sum_{r\in R}P(s',r|s,a) P(s′∣s,a)r∈R∑P(s′,r∣s,a)
三、价值函数

Policy: π \pi π表示
- 确定性策略: a ≜ π ( s ) a\triangleq \pi(s) a≜π(s)
- 随机性策略: π ( a ∣ s ) ≜ P r { A t = a ∣ S t = s } \pi(a|s)\triangleq Pr\{A_t=a|S_t=s\} π(a∣s)≜Pr{ At=a∣St=s}
回报:
G t = R t + 1 + γ R t + 2 + γ 2 R t + 3 + ⋯ + γ r − 1 R T = ∑ i = 0 ∞ γ i R t + i + 1 ( T → ∞ ) γ ∈ [ 0
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章















 1804
1804











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









