






100秒导出百万数据
背景
用户要求能够一次导出一个月的数据(10w量级别)
原理
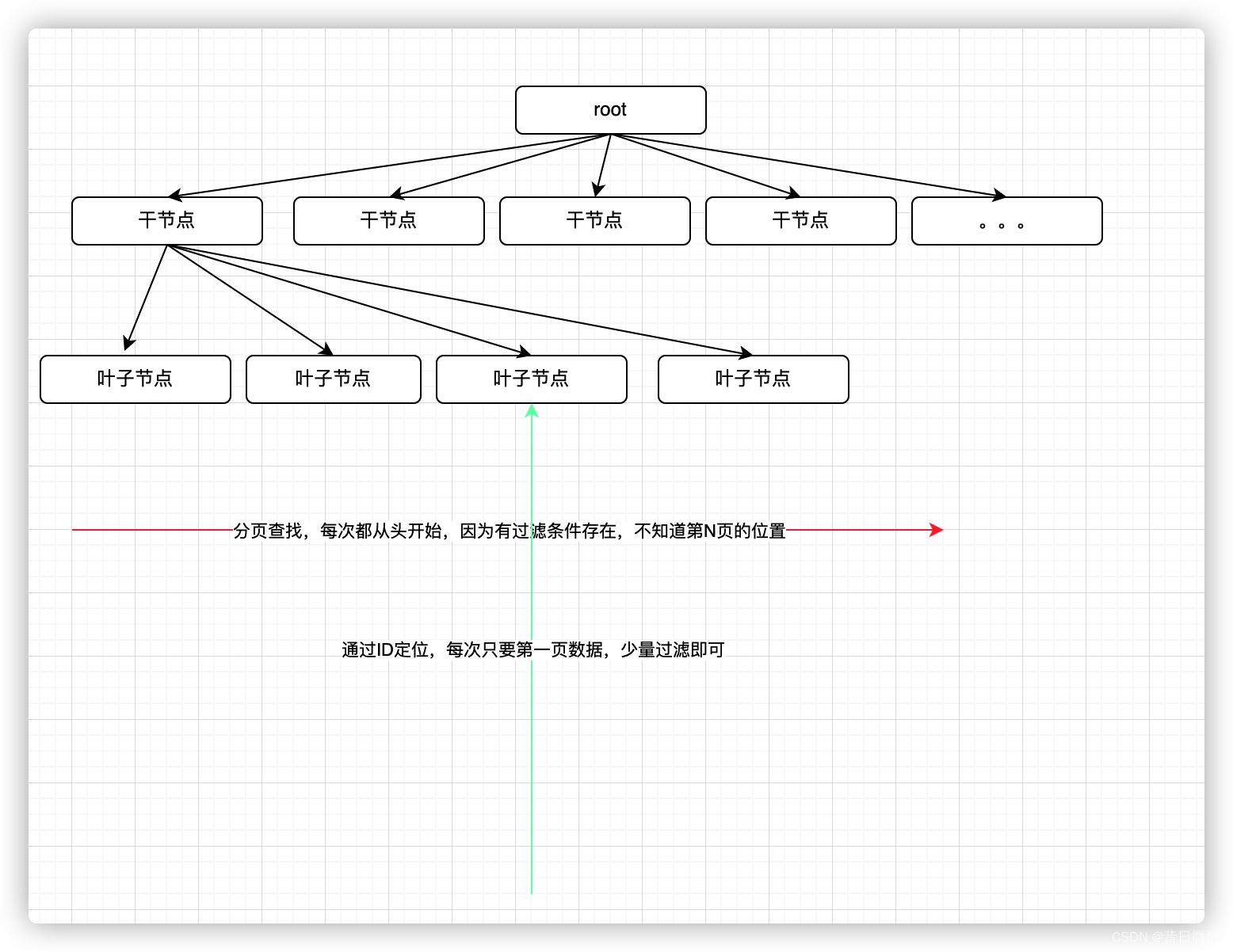
需求分析
- 生产环境担不起风险
- 内存要平稳不能溢出
- 对数据库缓存等中间件影响要小
- 导出要尽可能快
- 异步操作
- 不能重复导出
- 同时导出的操作不能超过10个
- 必要的时候快速强制终止导出操作
代码展示
核心之一是主表的分页逻辑
每次从指定ID的位置读取符合条件的前1000条数据,取代传统的分页;必须用ID排序,让用户在excel自己调整排序;
(经测试每导出5w条数据,pageSize设置为1000或10000,导出时间没有区别,但是设置为100会慢2~3s)
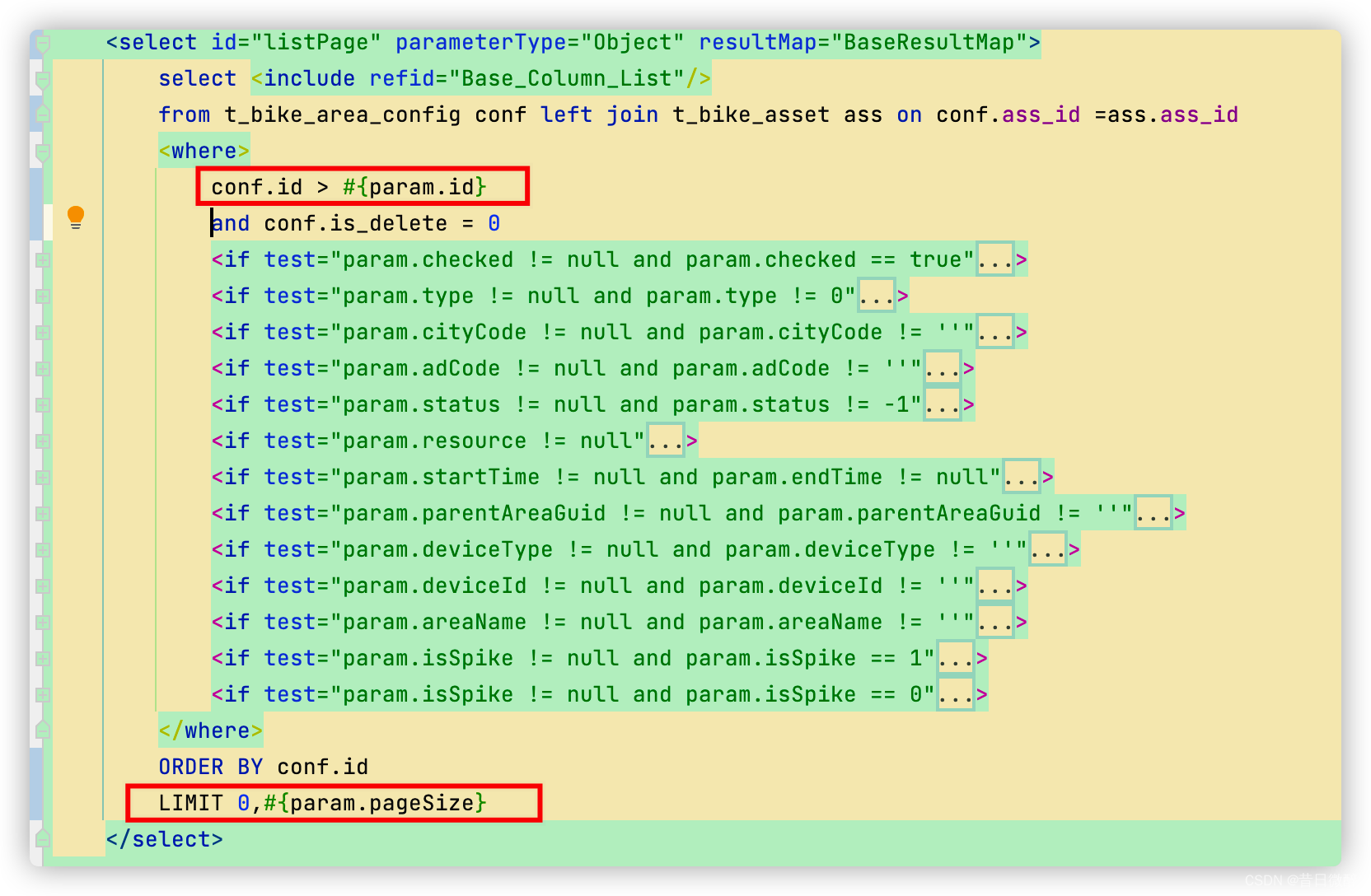
select * from table where id > xx limit 1000,这种查询也有缺点,对于亿级别的数据而言,数据如果比较离散,第一次和最后一次会查询非常久,造成超时。所以可以优化为
select * from table where id > xx and id <(xx+100000) limit 1000
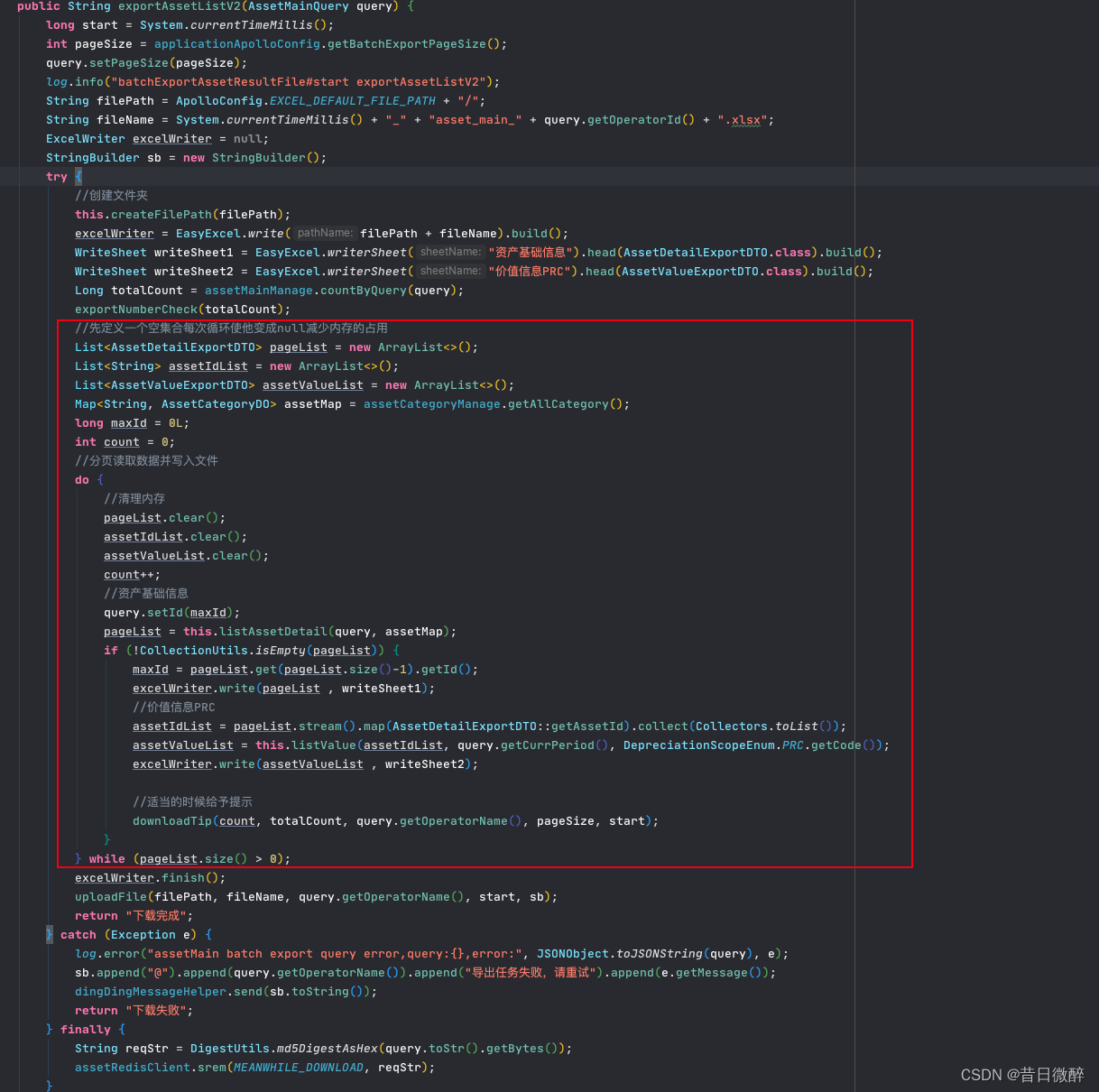
核心之二是每一批次的导出都先清空链表,方便内存回收,重复利用同一个链表,保证内存的稳定不溢出
这里用的阿里的easyExcel,这玩意写数据的时候会把整个excel文件一直放在内存;直到最后的finish(),71w数据的文件总大小为72M,平均每1W笔数据1M;可以考虑替换成XSSF(XSSF可以设置内存中的大小恒定为1M);
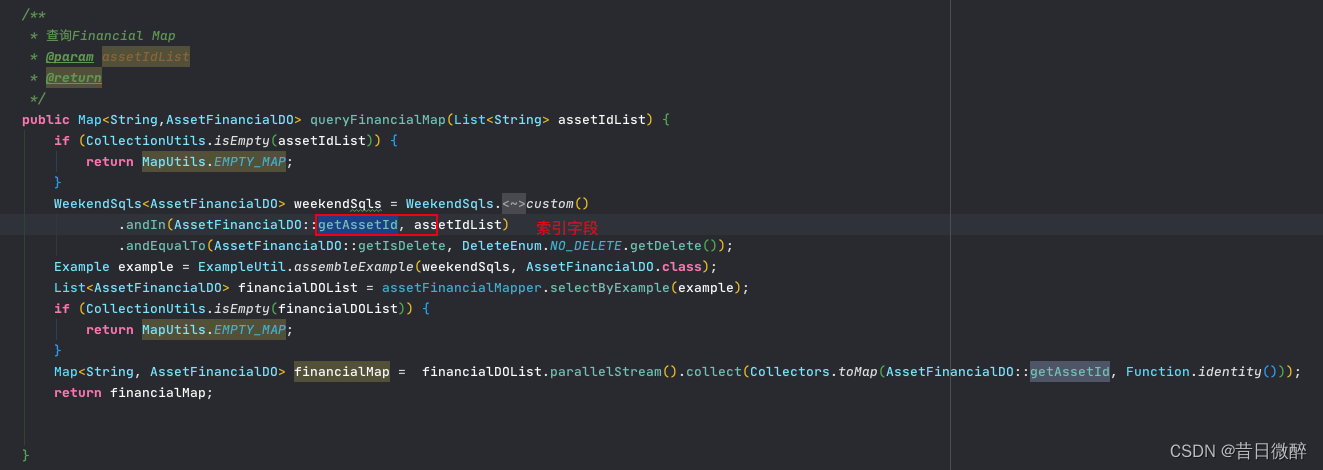
非核心之三利用in(索引值),取代偷懒的一条一条查库操作,减少网络传输次数,对导出时间能够提升一个数量级
非核心之四利用guava的本地缓存或者自己写个LRU解决一些需要远程查寻且重复度较高的数据,减少网络传输次数,避免用redis和内存溢出
非核心之五,对于总数不多(1000以内)但是需要用到的表数据,一次加载在内存,或者考虑分页预热到缓存
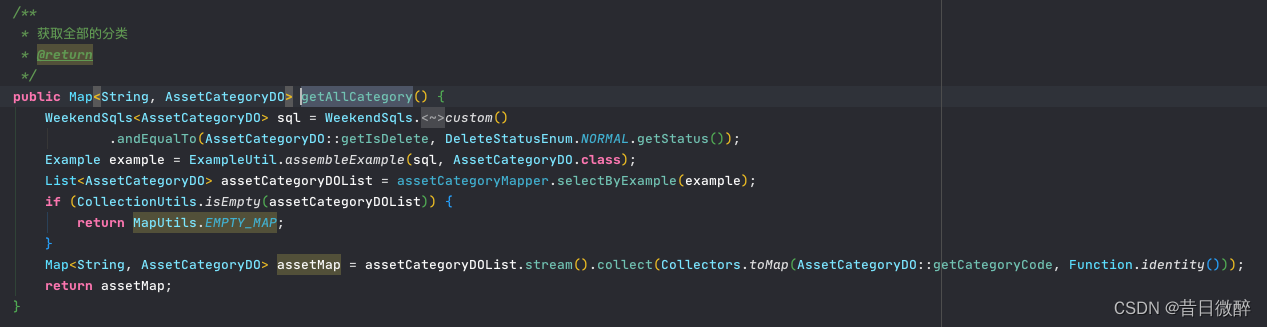
异步友好提示
利用redis的set解决导出前校验
重写toString(), 解决重复查询问题

如何更快,导出更多
- 更快:多线程+多sheet;比如两个线程,A线程处理0-50W的数据
B线程处理了50W-100W的数据,分别写到两个sheet - 更多:利用数仓
















 1362
1362











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









