







文章目录
- 机器学习导论(二)
- 一、机器学习关于数据集的概念
- (二)如何对二分类问题进行评价? 
- (三)概念学习
- (四)初始机器学习分类
- (五)初始机器学习框架
- 二、机器学习分类详解
- 三、机器学习经典案例举例
- 四、机器学习三要素详解及概念强化(熟悉)
- 五、如何设计机器学习系统(了解)
- 六、模型选择——泛化性能体现(掌握)
- 六、机器学习三要素数学理论补充(理解)
- 七、正则化(了解)
- 八、交叉验证
- 九、为什么现在是进入机器学习最佳时机(了解)
机器学习导论(二)
一、机器学习关于数据集的概念




(二)如何对二分类问题进行评价? 
性能矩阵



(三)概念学习


在类别标签列上,小明享受水上运动是离散的值,房价是连续型的数值。
(四)初始机器学习分类

(五)初始机器学习框架

二、机器学习分类详解
(一)监督学习


(二)案例:垃圾邮件的分类问题

(三)非监督学习(unsupervised learning)

聚类:在没有类别标签的情况下,根据特征相似性或相异性进行分类
特征降维:根据算法将高维特征讲道理低维特征低纬的特征不具备可解析性
区别于特征选择:仅是在全部特征中选择部分特征
(四)半监督学习

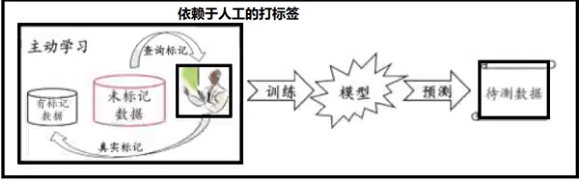


(五)强化学习


(六)迁移学习
有两个数据领域,一个数据领域小,一个数据领域大,先在大的数据领域里构建数据模型,然后迁移到小的数据领域,直接做预测。
深度学习,强化学习和迁移学习的区别
迁移学习能够解决的问题?

(七)机器学习的总结

三、机器学习经典案例举例
手写体识别与车牌号识别—机器学习监督学习中的10分类问题

四、机器学习三要素详解及概念强化(熟悉)
机器学习模型=数据+算法+策略
机器学习模型=模型++算法+策略

(一)模型——寻找规律

(二)策略——模型好不好


(三)算法

五、如何设计机器学习系统(了解)

六、模型选择——泛化性能体现(掌握)
(一)首先看数据

(二)模型选择——那条曲线拟合效果是最好的

(三)泛化
●模型具有好的泛化能力指的是:模型不但在训练数据集上表现的效果很好,对于新数据的适应能力也有很好的效果。
泛化能力的表现:过拟合和欠拟合
●过拟合overfitting:模型在训练数据上表现良好,在未知数据或者测试集_上表现差。
●欠拟合underfitting: 在训练数据和未知数据上表现都很差。

(四)模型选择的——奥卡姆剃刀原则

六、机器学习三要素数学理论补充(理解)
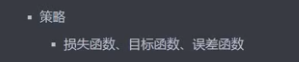
策略:
通过经验函数替代损失函数最小化

结构风险:添加正则项,防止过拟合

模型评估和模型选择

过拟合与模型选择

七、正则化(了解)
(一)什么是正则化?

(二)正则化

八、交叉验证
(一)什么是交叉验证?

(二)简单交叉验证

(三)十则交叉验证

把数据分成10份,每次拿一份数据集做训练集,其余做测试集
(四)留一验证

九、为什么现在是进入机器学习最佳时机(了解)
















 5954
5954











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









