






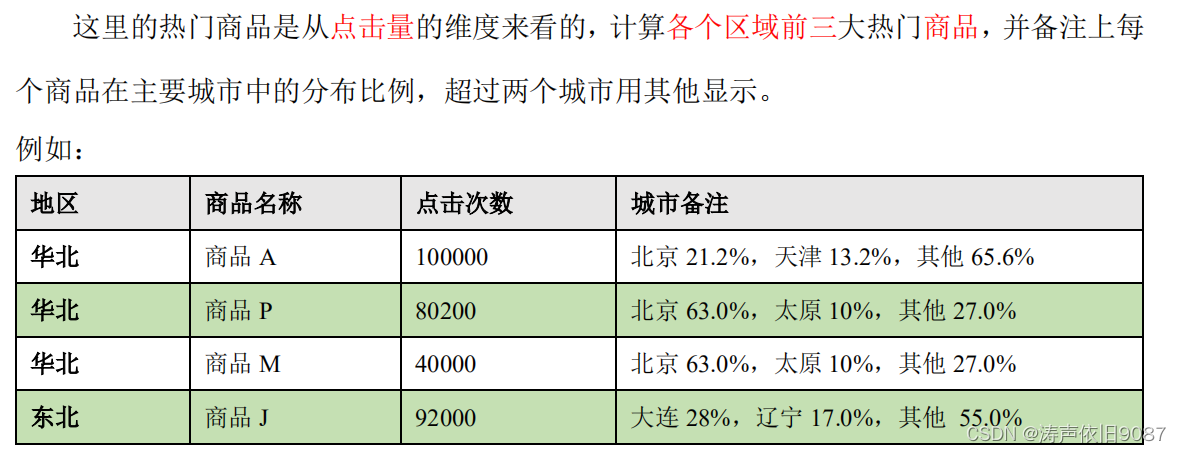
需求分析
➢ 查询出来所有的点击记录,并与 city_info 表连接,得到每个城市所在的地区,与Product_info 表连接得到产品名称
➢ 按照地区和商品 id 分组,统计出每个商品在每个地区的总点击次数
➢ 每个地区内按照点击次数降序排列
➢ 只取前三名
➢ 城市备注需要自定义 UDAF 函数
功能实现
➢ 连接三张表的数据,获取完整的数据(只有点击)
➢ 将数据根据地区,商品名称分组
➢ 统计商品点击次数总和,取 Top3
➢ 实现自定义聚合函数显示备注

import org.apache.spark.SparkConf
import org.apache.spark.sql._
object SparkSQL12_Req_Coding1 {
def main(args: Array[String]): Unit = {
System.setProperty("HADOOP_USER_NAME", "atguigu")
// TODO 开发SparkSQL程序
val sparkConf = new SparkConf().setMaster("local[*]").setAppName("SparkSQL")
val spark = SparkSession.builder().enableHiveSupport().config(sparkConf).getOrCreate()
// 生成模拟数据
spark.sql("use atguigu200523")
spark.sql(
"""
|select
| *
|from (
| select
| *,
| rank() over( partition by area order by clickCnt desc ) as rank
| from (
| select
| area,
| product_name,
| count(*) as clickCnt
| from (
| select
| a.*,
| p.product_name,
| c.area,
| c.city_name
| from user_visit_action a
| join product_info p on a.click_product_id = p.product_id
| join city_info c on a.city_id = c.city_id
| where a.click_product_id != -1
| ) t1 group by area, product_name
| ) t2
|) t3 where rank <= 3 order by rank
""".stripMargin).show
spark.stop()
}
}
import org.apache.spark.SparkConf
import org.apache.spark.sql._
import org.apache.spark.sql.expressions.Aggregator
import scala.collection.mutable
import scala.collection.mutable.ListBuffer
object SparkSQL12_Req_Coding2 {
def main(args: Array[String]): Unit = {
System.setProperty("HADOOP_USER_NAME", "atguigu")
// TODO 开发SparkSQL程序
val sparkConf = new SparkConf().setMaster("local[*]").setAppName("SparkSQL")
val spark = SparkSession.builder().enableHiveSupport().config(sparkConf).getOrCreate()
// 生成模拟数据
spark.sql("use atguigu200523")
spark.sql(
"""
|select
| a.*,
| p.product_name,
| c.area,
| c.city_name
| from user_visit_action a
| join product_info p on a.click_product_id = p.product_id
| join city_info c on a.city_id = c.city_id
| where a.click_product_id != -1
""".stripMargin).createOrReplaceTempView("t1")
// 聚合函数:同一个区域中多个城市 => 城市备注
spark.udf.register("cityRemark", functions.udaf(new CityRemarkUDAF()))
spark.sql(
"""
| select
| area,
| product_name,
| count(*) as clickCnt,
| cityRemark(city_name) as cityRemark
| from t1 group by area, product_name
""".stripMargin).createOrReplaceTempView("t2")
spark.sql(
"""
| select
| *,
| rank() over( partition by area order by clickCnt desc ) as rank
| from t2
""".stripMargin).createOrReplaceTempView("t3")
spark.sql(
"""
| select
| *
| from t3 where rank <= 3 order by rank
""".stripMargin).show(20, false)
spark.stop()
}
case class CityBuffer(var total: Long, var cityMap: mutable.Map[String, Long])
/**
* 城市备注聚合函数
* 1. 继承Aggregator,定义泛型
* IN: String
* BUF: CityBuffer
* OUT: String
* 2. 重写方法(6)
*/
class CityRemarkUDAF extends Aggregator[String, CityBuffer, String] {
override def zero: CityBuffer = {
CityBuffer(0L, mutable.Map[String, Long]())
}
override def reduce(buff: CityBuffer, cityName: String): CityBuffer = {
buff.total += 1L
val newVal = buff.cityMap.getOrElse(cityName, 0L) + 1
buff.cityMap.update(cityName, newVal)
buff
}
override def merge(b1: CityBuffer, b2: CityBuffer): CityBuffer = {
b1.total += b2.total
b2.cityMap.foreach {
case (cityName, cnt) => {
val newCnt = b1.cityMap.getOrElse(cityName, 0L) + cnt
b1.cityMap.update(cityName, newCnt)
}
}
b1
}
// 生成remark
override def finish(buff: CityBuffer): String = {
val cityClickList = ListBuffer[String]()
val totalCnt = buff.total
val cityDataList: List[(String, Long)] = buff.cityMap.toList.sortBy(_._2)(Ordering.Long.reverse).take(2)
val hasMoreCity = buff.cityMap.size > 2
var p = 100L
cityDataList.foreach {
case (city, cnt) => {
val r = cnt * 100 / totalCnt
if (hasMoreCity) {
p = p - r
}
val s = city + " " + r + "%"
cityClickList.append(s)
}
}
if (hasMoreCity) {
cityClickList.append("其他" + p + "%")
}
cityClickList.mkString(",")
}
override def bufferEncoder: Encoder[CityBuffer] = Encoders.product
override def outputEncoder: Encoder[String] = Encoders.STRING
}
}















 240
240











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









