







链表
1.剑指offer-链表-从尾到头打印链表
利用ArrayList的add(index,value)方法,指定index位置添加value值。在遍历listNode的同时将每个结点的值都插入到index为0的位置,最后返回的ArrayList的值便是链表逆序值。
时间复杂度和空间复杂度均为O(n)。
也可以使用栈来存储遍历到的每个结点的值,但是这样会有额外的空间消耗。
import java.util.ArrayList;
public class Solution {
public ArrayList<Integer> printListFromTailToHead(ListNode listNode) {
ArrayList<Integer> list = new ArrayList<Integer>();
ListNode cur = listNode;
while (cur != null) {
list.add(0,cur.val);
cur = cur.next;
}
return list;
}
}
public class ListNode{
int val;
ListNode next = null;
public ListNode {
this.val = val;
}
}
2.合并两个链表
要注意cur = cur.next;
时间复杂度O(1);空间复杂度O(n)。
public class Solution {
public ListNode Merge(ListNode list1,ListNode list2) {
ListNode newNode = new ListNode(-1);
ListNode cur = newNode;
while (list1 != null && list2 != null) {
if (list1.val <= list2.val) {
cur.next = list1;
list1 = list1.next;
} else {
cur.next = list2;
list2 = list2.next;
}
cur = cur.next;
}
cur.next = list1 != null ? list1 : list2;
return newNode.next;
}
}
class ListNode {
int val;
ListNode next = null;
ListNode(int val) {
this.val = val;
}
}
3 删除链表的节点
首先要判断头节点是否等于设定的值;在判断之后节点的值是否等于设定val时,如果找到符合条件的节点,需要break,跳出循环。
import java.util.*;
/*
* public class ListNode {
* int val;
* ListNode next = null;
* public ListNode(int val) {
* this.val = val;
* }
* }
*/
public class Solution {
/**
* 代码中的类名、方法名、参数名已经指定,请勿修改,直接返回方法规定的值即可
*
*
* @param head ListNode类
* @param val int整型
* @return ListNode类
*/
public ListNode deleteNode (ListNode head, int val) {
// write code here
if (head.val == val) return head.next;
ListNode pre = new ListNode(-1);
ListNode cur = head;
pre.next = cur;
while (cur != null) {
pre = cur;
cur = cur.next;
if (cur.val == val) {
cur = cur.next;
pre.next = cur;
break;//注意此处要break
}
}
return head;
}
}
4 删除链表中重复的节点

使用递归来做,如果当前链表头结点和其之后若干个节点的值相等,则返回第一个具有不相等的值的节点;如果第一个节点和第二个节点值就不相等,就从第二个节点开始递归。
/*
public class ListNode {
int val;
ListNode next = null;
ListNode(int val) {
this.val = val;
}
}
*/
public class Solution {
public ListNode deleteDuplication(ListNode pHead) {
if (pHead == null || pHead.next == null) {
return pHead;
}
ListNode curNode = pHead;
ListNode nextNode = curNode.next;
if (curNode.val == nextNode.val) {//1.
while (nextNode != null && curNode.val == nextNode.val) { //注意此处循环条件
nextNode = nextNode.next;
}
return deleteDuplication(nextNode);
} else {//2.
curNode.next = deleteDuplication(nextNode);
return curNode;
}
}
}
5.链表的复制
1.可先定义一个map,map中存储<ListNode,ListNode>这样的键值对,顺序遍历一次原链表,键为原链表的节点,值为新建一个与原链表对应值相等的节点;
2.遍历一次原链表,将对应关系(即新链表节点的next和random)对照原链表连起来。
import java.util.*;
/*
public class RandomListNode {
int label;
RandomListNode next = null;
RandomListNode random = null;
RandomListNode(int label) {
this.label = label;
}
}
*/
public class Solution {
public RandomListNode Clone(RandomListNode pHead) {
if (pHead == null) return null;
HashMap<RandomListNode,RandomListNode> map = new HashMap<>();
for (RandomListNode cur = pHead;cur != null;cur = cur.next) {
map.put(cur,new RandomListNode(cur.label));
}
for (RandomListNode cur = pHead;cur != null;cur = cur.next) {
map.get(cur).next = map.get(cur.next);//注意此处
map.get(cur).random = map.get(cur.random);//注意此处
}
return map.get(pHead);
}
}
6.链表中倒数最后k个结点
使用快慢指针,先让快指针走k步,接着快慢指针同时走,直到快指针下一个节点为null停止,返回慢指针。
注意:如果k超出了链表的长度,则返回值为null。
import java.util.*;
/*
* public class ListNode {
* int val;
* ListNode next = null;
* public ListNode(int val) {
* this.val = val;
* }
* }
*/
public class Solution {
/**
* 代码中的类名、方法名、参数名已经指定,请勿修改,直接返回方法规定的值即可
*
*
* @param pHead ListNode类
* @param k int整型
* @return ListNode类
*/
public ListNode FindKthToTail (ListNode pHead, int k) {
// write code here
ListNode fast = pHead;
ListNode slow = pHead;
while (k > 0) {
if (fast != null) {
fast = fast.next;
k--;
} else {
return null;//注意~
}
}
while(fast != null) {
slow = slow.next;
fast = fast.next;
}
return slow;
}
}
7.链表中环的入口结点
新建两个指针,分别为快慢指针,均指向头节点,快指针每次走两步,慢指针每次走一步,当快慢指针相遇时,让快指针重新指向头节点。接着快慢指针每次走一步,再次相遇的节点则为环的入口结点。
证明:
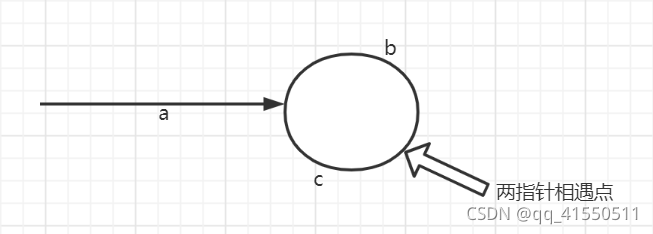
快指针走的步数为:a+k(b+c)+b
慢指针走的步数为:a+b
快指针是慢指针步长的二倍
a+k(b+c)+b = 2(a+b)
得到: a = (k-1)(b+c)+c
/*
public class ListNode {
int val;
ListNode next = null;
ListNode(int val) {
this.val = val;
}
}
*/
public class Solution {
public ListNode EntryNodeOfLoop(ListNode pHead) {
if (pHead == null || pHead.next == null) return null;//注意此处,不写的话,1 这样的单个节点的用例不通过
ListNode fast = pHead.next.next;//注意 一开始就要赋值
ListNode slow = pHead.next;//注意 一开始就要赋值
while(fast != slow) {
if (fast != null) {
fast = fast.next.next;
slow = slow.next;
} else {//注意写else,不写的话,1-->2 这样两个节点的用例则不通过
return null;
}
}
fast = pHead;
while (fast != slow) {
fast = fast.next;
slow = slow.next;
}
return fast;
}
}
8.两个链表的第一个公共结点
第一种方法:
可以使用一个hashset存储第一个链表的所有节点,接着对第二个链表的节点从头开始进行遍历,如果存在相同的节点,那么就为这两个链表的第一个公共节点。
缺点:空间消耗过多。
import java.util.*;
/*
public class ListNode {
int val;
ListNode next = null;
ListNode(int val) {
this.val = val;
}
}*/
public class Solution {
public ListNode FindFirstCommonNode(ListNode pHead1, ListNode pHead2) {
HashSet<ListNode> set = new HashSet<ListNode>();
for (ListNode cur = pHead1;cur != null;cur = cur.next) {
set.add(cur);
}
for (ListNode cur = pHead2;cur != null;cur = cur.next) {
if (set.contains(cur)) {
return cur;
}
}
return null;
}
}
第二种方法:
new 两个指针cur1,cur2,为了让这两个指针走相同的步长,可以让这两个指针分别遍历这两个链表,如果到链表的尾部,让cur1指向pHead2,cur2指向pHead1。如果cur1与cur2相等,则此时两指针指向的节点为所求公共节点。
public class Solution {
public ListNode FindFirstCommonNode(ListNode pHead1, ListNode pHead2) {
ListNode cur1 = pHead1,cur2 = pHead2;
while (cur1 != cur2) {
if (cur1 != null) {
cur1 = cur1.next;
} else {
cur1 = pHead2;
}
if (cur2 != null) {
cur2 = cur2.next;
} else {
cur2 = pHead1;
}
}
return cur2;
}
}
9.合并两个有序链表
分别比较两个链表节点的值,把小的放前面。如果某个链表已经到末尾,则不需要比较,直接将另一个还未遍历完的链表的剩余部分添加到已排序好的链表末尾即可。
/*
public class ListNode {
int val;
ListNode next = null;
ListNode(int val) {
this.val = val;
}
}*/
public class Solution {
public ListNode Merge(ListNode list1,ListNode list2) {
if (list1 == null) return list2;
if (list2 == null) return list1;
ListNode cur = new ListNode(-1);
ListNode res = cur;
while(list1 != null && list2 != null) {
if (list1.val <= list2.val) {
cur.next = list1;
list1 = list1.next;
} else {
cur.next = list2;
list2 = list2.next;
}
cur = cur.next;
}
cur.next = list1 != null? list1 : list2; //注意此处简洁写法
return res.next;
}
}
10.反转链表
新建节点cur为当前节点,从head开始遍历。新建pre节点为当前节点的上一个节点。
while循环中 为重点:
每次都要新建一个next节点表示当前节点cur的下一个节点。
cur.next = pre;
pre = cur;
cur = next;
/*
public class ListNode {
int val;
ListNode next = null;
ListNode(int val) {
this.val = val;
}
}*/
public class Solution {
public ListNode ReverseList(ListNode head) {
if (head == null || head.next == null) return head;
ListNode pre = null;
ListNode cur = head;
while (cur != null) {
ListNode next = cur.next;
cur.next = pre;
pre = cur;
cur = next;
}
return pre;
}
}
11.从尾到头打印链表
第一种方法
可以利用栈的先进后出这样的性质,先将链表的节点存储到栈中,再将栈中的每个节点的值添加到list中。
/**
* public class ListNode {
* int val;
* ListNode next = null;
*
* ListNode(int val) {
* this.val = val;
* }
* }
*
*/
import java.util.*;
public class Solution {
public ArrayList<Integer> printListFromTailToHead(ListNode listNode) {
ArrayList<Integer> list = new ArrayList<Integer>();
Stack<ListNode> stack = new Stack<ListNode>();
ListNode cur = listNode;
while (cur != null) {
stack.push(cur);
cur = cur.next;
}
while (!stack.isEmpty()) {
list.add(stack.pop().val);
}
return list;
}
}
第二种方法
先将链表进行反转,然后依次遍历链表的节点并将节点的值添加到list中
import java.util.*;
public class Solution {
public ArrayList<Integer> printListFromTailToHead(ListNode listNode) {
ArrayList<Integer> list = new ArrayList<Integer>();
if (listNode == null) return list;
ListNode cur = listNode;
ListNode pre = null;
while (cur != null) {
ListNode next = cur.next;
cur.next = pre;
pre = cur;
cur = next;
}
while (pre != null) {
list.add(pre.val);
pre = pre.next;
}
return list;
}
}
栈
1.括号匹配
(1)
class Solution {
public boolean isValid(String s) {
Stack<Character> stack = new Stack<Character>();
for (int i = 0;i < s.length();i++) {
if (s.charAt(i) == '{') stack.push('}');
else if (s.charAt(i) == '(') stack.push(')');
else if (s.charAt(i) == '[') stack.push(']');
else if (stack.isEmpty() || s.charAt(i) != stack.pop()) return false;
}
return stack.isEmpty();
}
}
(2)
class Solution {
public boolean isValid(String s) {
Stack<Character> stack = new Stack<Character>();
for (char c : s.toCharArray()) {
if (c == '{') stack.push('}');
else if (c == '(') stack.push(')');
else if (c == '[') stack.push(']');
else if (stack.isEmpty() || c != stack.pop()) return false;
}
return stack.isEmpty();
}
}
s.toCharArray():表示将字符串转换为字符数组
char[] cs = s.toCharArray();
2.最小栈
class MinStack {
Stack<Integer> stack = new Stack<Integer>();
Stack<Integer> stackMin = new Stack<Integer>();
public MinStack() {
}
public void push(int val) {
stack.push(val);
//注意 此处应该先判断stackMin是否为空!
if (stackMin.isEmpty()) {
stackMin.push(val);
} else if (val <= stackMin.peek()) {
stackMin.push(val);
} else {
stackMin.push(stackMin.peek());
}
}
public void pop() {
stackMin.pop();
stack.pop();
}
public int top() {
return stack.peek();
}
public int getMin() {
return stackMin.peek();
}
}
/**
* Your MinStack object will be instantiated and called as such:
* MinStack obj = new MinStack();
* obj.push(val);
* obj.pop();
* int param_3 = obj.top();
* int param_4 = obj.getMin();
*/
3.两个栈实现队列
实现队列的添加和删除操作。
class CQueue {
Stack<Integer> stack1 = new Stack<Integer>();
Stack<Integer> stack2 = new Stack<Integer>();
public CQueue() {
}
public void appendTail(int value) {
stack1.push(value);
}
public int deleteHead() {
if (!stack2.isEmpty()) return stack2.pop();
else {
while (!stack1.isEmpty()) {
stack2.push(stack1.pop());
}
if (!stack2.isEmpty()) return stack2.pop();
}
return -1;
}
}
/**
* Your CQueue object will be instantiated and called as such:
* CQueue obj = new CQueue();
* obj.appendTail(value);
* int param_2 = obj.deleteHead();
*/
4.表达式求值
2021/12/4
1.用栈保存每个部分计算的和
2.遍历表达式,使用sign变量记录运算符,sign初始化为’+’; num变量记录字符串中的数字部分的数字值为多少。
+ 2.1遇到数字时继续遍历求这个完整的数字的值,将值保存到num中
+ 2.2遇到左括号时候递归求这个括号中表达式的值
+ 2.2.1先遍历找到对应的右括号,由于其中可能嵌套有多对括号,使用一个变量flag统计其中的括号对数,直到flag变为0;
+ 2.3当遇到运算符或者表达式末尾时,就去计算上一个运算符并将结果push进栈,然后将新的运算符保存到sign中。
+ 2.3.1如果是‘+’,不需要计算,直接push进去。
+ 2.3.2如果是‘-’,push进去负的当前的数
+ 2.3.3如果是‘*’或者‘/’,pop出一个运算数和当前数做计算。
3.最后将栈中的结果求和。
import java.util.*;
public class Solution {
/**
* 代码中的类名、方法名、参数名已经指定,请勿修改,直接返回方法规定的值即可
* 返回表达式的值
* @param s string字符串 待计算的表达式
* @return int整型
*/
public int solve (String s) {
// write code here
Stack<Integer> stack = new Stack<Integer>();
char[] charArr = s.toCharArray();
int num = 0;
char sign = '+';
for (int i = 0;i < charArr.length;i++) {
char c = charArr[i];
if (Character.isDigit(c)) {
num = num * 10 + c - '0';
}
if (c == '(') {
int flag = 1;
int j = i+1;
while (flag > 0) {
if (charArr[j] == ')') {
flag--;
}
if (charArr[j] == '(') {
flag++;
}
j++;
}
num = solve(s.substring(i+1,j-1));
i = j-1;
}
if (!Character.isDigit(c) || i == charArr.length-1) {
if (sign == '+') {
stack.push(num);
} else if (sign == '-') {
stack.push(-1*num);
} else if (sign == '*') {
stack.push(stack.pop() * num);
} else if (sign == '/') {
stack.push(stack.pop() / num);
}
num = 0;
sign = c;
}
}
int res = 0;
while (!stack.isEmpty()) {
res += stack.pop();
}
return res;
}
}
二叉树
1.二叉树的层序遍历
输入:二叉树根节点
输出:二维列表。其中的每一个一维列表为二叉树的每一层结点的值。
思路:使用广度优先的方法。从根节点开始,将二叉树的每层结点放入一个queue队列中,当队列不为空时,不断poll出队列中的结点。并将弹出的结点的值记录到临时的list中,当遍历完之前的queue时,就将list这个一维列表添加到最终的结果中。
不断重复上述步骤,直到queue为空,则说明已经将二叉树的最底层结点处理了。此时结束,将结果返回。
import java.util.*;
/*
* public class TreeNode {
* int val = 0;
* TreeNode left = null;
* TreeNode right = null;
* }
*/
public class Solution {
public ArrayList<ArrayList<Integer>> levelOrder (TreeNode root) {
// write code here
ArrayList<ArrayList<Integer>> res = new ArrayList<>();
if (root == null) return res;
Queue<TreeNode> queue = new LinkedList<TreeNode>();
queue.add(root);
while (!queue.isEmpty()) {
int size = queue.size();
ArrayList<Integer> list = new ArrayList<>();
for (int i = 0;i < size;i++) {
TreeNode tmpNode = queue.poll();
list.add(tmpNode.val);
if (tmpNode.left != null) {
queue.add(tmpNode.left);
}
if (tmpNode.right != null) {
queue.add(tmpNode.right);
}
}
res.add(list);
}
return res;
}
}
2.按Z子形层序打印二叉树

本题在层序打印二叉树的基础上需要将二叉树的偶数层倒序打印。
思路:可以在获取到二叉树的层序遍历的二维列表后,对二维列表进行从第0个开始遍历,如果i%2 == 1的话,就将其反转。
import java.util.*;
/*
public class TreeNode {
int val = 0;
TreeNode left = null;
TreeNode right = null;
public TreeNode(int val) {
this.val = val;
}
}
*/
public class Solution {
public ArrayList<ArrayList<Integer> > Print(TreeNode pRoot) {
ArrayList<ArrayList<Integer>> res = new ArrayList<>();
if (pRoot == null) return res;
// Boolean flag = true;
Queue<TreeNode> queue = new LinkedList<TreeNode>();
queue.add(pRoot);
while (!queue.isEmpty()) {
int size = queue.size();
ArrayList<Integer> tmpList = new ArrayList<>();
for (int i = 0;i < size;i++) {
TreeNode tmpNode = queue.poll();
tmpList.add(tmpNode.val);
if (tmpNode.left != null) {
queue.add(tmpNode.left);
}
if (tmpNode.right != null) {
queue.add(tmpNode.right);
}
}
res.add(tmpList);
}
int resSize = res.size();
for (int i = 0;i < resSize;i++) {
if (i % 2 == 1) {
Collections.reverse(res.get(i));
}
}
return res;
}
/*
public static ArrayList reverse(ArrayList<Integer> arr) {
arr.toArray();
int arrSize = arr.size();
for (int i = 0;i < arrSize/2;i++) {
int tmp = arr[i];
arr[i] = arr[arrSize-1-i];
arr[arrSize-1-i] = tmp;
}
}
*/
}
总结ArrayList的反转的方法
List<Integer> list = new ArrayList<Integer>();
list.add(1);
list.add(2);
list.add(3);
//方法1:
Iterator it1 = list.iterator();
while (it1.hasNext()) {
System.out.println(it1.next());
}
//方法2:
for (Iterator it2 = list.iterator();it2.hasNext();) {
System.out.println(it2.next());
}
//方法3:
for (Integer tmp : list) {
System.out.println(tmp);
}
//方法4:
for (int i = 0;i < list.size();i++) {
System.out.println(list.get(i));
}
ArrayList 反转以及ArrayList介绍:
https://www.cnblogs.com/interdrp/p/3663602.html
3.二叉树前序遍历
1.递归:
/**
* Definition for a binary tree node.
* public class TreeNode {
* int val;
* TreeNode left;
* TreeNode right;
* TreeNode() {}
* TreeNode(int val) { this.val = val; }
* TreeNode(int val, TreeNode left, TreeNode right) {
* this.val = val;
* this.left = left;
* this.right = right;
* }
* }
*/
class Solution {
ArrayList<Integer> arr = new ArrayList<Integer>();
public List<Integer> preorderTraversal(TreeNode root) {
preOrder(root);
return arr;
}
public void preOrder(TreeNode root) {
if (root == null) return;
else {
arr.add(root.val);
preOrder(root.left);
preOrder(root.right);
}
}
}
2.非递归
用栈
/**
* Definition for a binary tree node.
* public class TreeNode {
* int val;
* TreeNode left;
* TreeNode right;
* TreeNode() {}
* TreeNode(int val) { this.val = val; }
* TreeNode(int val, TreeNode left, TreeNode right) {
* this.val = val;
* this.left = left;
* this.right = right;
* }
* }
*/
class Solution {
public List<Integer> preorderTraversal(TreeNode root) {
ArrayList<Integer> arr = new ArrayList<Integer>();
preOrder(root,arr);
return arr;
}
public void preOrder(TreeNode root,List<Integer> arr) {
Stack<TreeNode> stack = new Stack<TreeNode>();
if (root == null) return ;
while (root != null || !stack.isEmpty()) {
while (root != null) {
// 一直遍历root的左子树,同时将节点存入栈中,一直到没有左节点为止。
stack.push(root);
arr.add(root.val);
root = root.left;
}
// 将stack中的节点的右子节点作为根节点进行遍历
root = stack.pop().right;
}
}
}
4.二叉树中序遍历
1.递归
/**
* Definition for a binary tree node.
* public class TreeNode {
* int val;
* TreeNode left;
* TreeNode right;
* TreeNode() {}
* TreeNode(int val) { this.val = val; }
* TreeNode(int val, TreeNode left, TreeNode right) {
* this.val = val;
* this.left = left;
* this.right = right;
* }
* }
*/
class Solution {
public List<Integer> inorderTraversal(TreeNode root) {
ArrayList<Integer> res = new ArrayList<Integer>();
if (root == null) return res;
inOrder(root,res);
return res;
}
public void inOrder(TreeNode root,ArrayList<Integer> res) {
if (root.left != null) inOrder(root.left,res);
res.add(root.val);
if (root.right != null) inOrder(root.right,res);
}
}
2.迭代
使用栈
/**
* Definition for a binary tree node.
* public class TreeNode {
* int val;
* TreeNode left;
* TreeNode right;
* TreeNode() {}
* TreeNode(int val) { this.val = val; }
* TreeNode(int val, TreeNode left, TreeNode right) {
* this.val = val;
* this.left = left;
* this.right = right;
* }
* }
*/
class Solution {
public List<Integer> inorderTraversal(TreeNode root) {
ArrayList<Integer> res = new ArrayList<Integer>();
if (root == null) return res;
inOrder(root,res);
return res;
}
public void inOrder(TreeNode root,ArrayList<Integer> res) {
Stack<TreeNode> stack = new Stack<TreeNode>();
while (!stack.isEmpty() || root != null) {
// if (root != null) {
// stack.push(root);
// root = root.left;
// } else {
// root = stack.pop();
// res.add(root.val);
// root = root.right;
// }
while (root != null) {
stack.push(root);
root = root.left;
}
root = stack.pop();
res.add(root.val);
root = root.right;
}
}
}
5.二叉树后序遍历
/**
* Definition for a binary tree node.
* public class TreeNode {
* int val;
* TreeNode left;
* TreeNode right;
* TreeNode() {}
* TreeNode(int val) { this.val = val; }
* TreeNode(int val, TreeNode left, TreeNode right) {
* this.val = val;
* this.left = left;
* this.right = right;
* }
* }
*/
class Solution {
public List<Integer> postorderTraversal(TreeNode root) {
List<Integer> arr = new ArrayList<Integer>();
postOrder(root,arr);
return arr;
}
public void postOrder(TreeNode root,List<Integer> arr) {
Stack<TreeNode> stack = new Stack<TreeNode>();
TreeNode preNode = null; //记录上一个节点
TreeNode curNode = root; //记录当前节点
while (curNode != null || !stack.isEmpty()) {
while (curNode != null) {
stack.push(curNode);
curNode = curNode.left;
}
curNode = stack.peek();
//如果当前节点的右节点是空的 或者 当前节点的右节点 就是之前遍历过的节点,
//此时应该将当前节点添加到结果集中
if (curNode.right == null || curNode.right == preNode) {
arr.add(curNode.val);
preNode = curNode;
curNode = null;
stack.pop();
} else {
curNode = curNode.right;
}
}
}
}
6.二叉树的最近公共祖先
给定两个节点的值o1,o2,求这两个节点的最近公共祖先
1.使用一个队列记录距离二叉树距离根节点较近的包含这两个的所有父节点
2.使用一个HashMap记录从根节点到这两个节点的所有父节点的映射。map中存储形式为<node.val,node.parent.val>。
3.使用一个HashSet记录o1和它的所有父节点的值;接着查看o1和它的祖先节点是否包含o2节点,如果不包含的话再看看是否包含o2的父节点,直到找到为止。
import java.util.*;
/*
* public class TreeNode {
* int val = 0;
* TreeNode left = null;
* TreeNode right = null;
* }
*/
public class Solution {
/**
*
* @param root TreeNode类
* @param o1 int整型
* @param o2 int整型
* @return int整型
*/
public int lowestCommonAncestor (TreeNode root, int o1, int o2) {
Queue<TreeNode> queue = new LinkedList<TreeNode>();
HashMap<Integer,Integer> map = new HashMap<>();
map.put(root.val,Integer.MIN_VALUE);
queue.add(root);
while (!map.containsKey(o1) || !map.containsKey(o2)) {
TreeNode tmpNode = queue.poll();
if (tmpNode.left != null) {
queue.add(tmpNode.left);
map.put(tmpNode.left.val,tmpNode.val);
}
if (tmpNode.right != null) {
queue.add(tmpNode.right);
map.put(tmpNode.right.val,tmpNode.val);
}
}
HashSet<Integer> set = new HashSet<>();
while (map.containsKey(o1)) {
set.add(o1);
o1 = map.get(o1);
}
while (!set.contains(o2)) {
o2 = map.get(o2);
}
return o2;
}
}
7.重构二叉树
给定两个数组,一个前序遍历节点值构成的数组pre,一个中序遍历节点值构成的数组vin;
输出根节点。
/**
* Definition for binary tree
* public class TreeNode {
* int val;
* TreeNode left;
* TreeNode right;
* TreeNode(int x) { val = x; }
* }
*/
public class Solution {
public TreeNode reConstructBinaryTree(int [] pre,int [] vin) {
if (pre.length == 0) return null;
TreeNode root = build(pre,0,pre.length-1,vin,0,vin.length-1);
return root;
}
public TreeNode build(int[] pre,int lp,int rp,int[] vin,int li,int ri) {
if (lp > rp) return null;
TreeNode res = new TreeNode(pre[lp]);
int index = li;
while (index < ri && pre[lp] != vin[index]) {
index++;
}
int len = index-li;
res.left = build(pre,lp+1,lp+len,vin,li,li+len);
res.right = build(pre,lp+len+1,rp,vin,index+1,ri);
return res;
}
}
8.二叉树的右视图
输入:二叉树的前序遍历和中序遍历节点值的数组;
输出:二叉树的右视图节点值的数组
思路:
1.定义TreeNode节点类
2.重构二叉树
3.对二叉树进行层序遍历,等到每层的最后一个节点时,将节点值添加到结果中。
import java.util.*;
public class Solution {
/**
* 代码中的类名、方法名、参数名已经指定,请勿修改,直接返回方法规定的值即可
* 求二叉树的右视图
* @param xianxu int整型一维数组 先序遍历
* @param zhongxu int整型一维数组 中序遍历
* @return int整型一维数组
*/
public int[] solve (int[] xianxu, int[] zhongxu) {
// write code here
if (xianxu.length == 0) return null;
TreeNode root = build(xianxu,0,xianxu.length-1,zhongxu,0,zhongxu.length-1);
ArrayList<Integer> resList = layerTravesal(root);
int[] res = new int[resList.size()];
for (int i = 0;i < resList.size();i++) {
res[i] = resList.get(i);
}
return res;
}
public ArrayList<Integer> layerTravesal(TreeNode root) {
ArrayList<Integer> list = new ArrayList<>();
Queue<TreeNode> queue = new LinkedList<>();
queue.add(root);
while (!queue.isEmpty()) {
int size = queue.size();
for (int i = 0;i < size;i++) {
TreeNode node = queue.poll();
if (node.left != null) {
queue.add(node.left);
}
if (node.right != null) {
queue.add(node.right);
}
if (i == size-1) {
list.add(node.val);
}
}
}
return list;
}
public TreeNode build(int[] xianxu,int startP,int endP,int[] zhongxu,int startI,int endI) {
if (startP > endP) return null;
TreeNode root = new TreeNode(xianxu[startP]);
int index = startI;
while (index <= endI && xianxu[startP] != zhongxu[index]) {
index++;
}
int len = index - startI;
root.left = build(xianxu,startP+1,startP+len,zhongxu,startI,startI+len);
root.right = build(xianxu,startP+len+1,endP,zhongxu,index+1,endI);
return root;
}
}
class TreeNode {
int val;
TreeNode left;
TreeNode right;
TreeNode(int x) {
val = x;
}
}
9.二叉树的深度
输入一个二叉树的根节点,输出这个二叉树的最大深度
思路:
与二叉树的层序遍历类似,每遍历一次,深度+1。
(1).
import java.util.*;
/*
* public class TreeNode {
* int val = 0;
* TreeNode left = null;
* TreeNode right = null;
* }
*/
public class Solution {
/**
*
* @param root TreeNode类
* @return int整型
*/
public int maxDepth (TreeNode root) {
// write code here
int res = 0;
if (root == null) return res;
Queue<TreeNode> queue = new LinkedList<TreeNode>();
queue.add(root);
while (!queue.isEmpty()) {
int size = queue.size();
for (int i = 0;i < size;i++) {
TreeNode tmpNode = queue.poll(); //注意此行,写正确位置
if (tmpNode.left != null) {
queue.add(tmpNode.left);
}
if (tmpNode.right != null) {
queue.add(tmpNode.right);
}
}
res++;
}
return res;
}
}
(2).递归
import java.util.*;
/*
* public class TreeNode {
* int val = 0;
* TreeNode left = null;
* TreeNode right = null;
* }
*/
public class Solution {
public int maxDepth (TreeNode root) {
if (root == null) return 0;
int l = maxDepth(root.left);
int r = maxDepth(root.right);
return Math.max(l,r)+1;
}
}
10判断是否为平衡二叉树
平衡二叉树:它是一棵空树或者它的左右两个子树的高度差绝对值不超过1,并且它的左右两个子树都是一棵平衡二叉树。
思路:
判断二叉树的深度的基础上加上判断左右两个子树的差值:若 |左子树深度-右子树深度| > 1,则不是平衡树。
public class Solution {
boolean flag = true;
public boolean IsBalanced_Solution(TreeNode root) {
getDepth(root);
return flag;
}
public int getDepth(TreeNode root) {
if (root == null) return 0;
int leftDepth = getDepth(root.left);
int rightDepth = getDepth(root.right);
if (Math.abs(leftDepth-rightDepth) > 1) {
flag = false;
}
return Math.max(leftDepth,rightDepth)+1;
}
}
跳台阶
1.递归
时间复杂度:O(n)
空间复杂度:O(n*n)
public class Solution {
public int jumpFloor(int target) {
if (target <= 1) return 1;
return jumpFloor(target-1) + jumpFloor(target-2);
}
}
2.使用数组或者hashmap来存储
时间复杂度:O(n)
空间复杂度:O(n)
import java.util.*;
public class Solution {
int[] arr = new int[100];
public int jumpFloor(int target) {
if (target <= 1) return 1;
if (arr[target] > 0) {
return arr[target];
}
return arr[target] = (jumpFloor(target-1) + jumpFloor(target-2));
}
}
public class Solution {
HashMap<Integer,Integer> map = new HashMap<Integer,Integer>();
public int jumpFloor(int target) {
if (target <= 1) return 1;
if (map.get(target) != null) {
return map.get(target);
}
map.put(target,(jumpFloor(target-1) + jumpFloor(target-2)));
return map.get(target);
}
}
3.动态规划
方法2是从上往下递归,然后从下往上再回溯,最后回溯的时候来合并子树从而得到答案。
(1)
时间复杂度:O(n)
空间复杂度:O(n)
使用动态规划直接从下往上,从而得到答案。
public class Solution {
int[] dp = new int[100];
public int jumpFloor(int target) {
dp[0] = 1;
dp[1] = 1;
for (int i = 2;i < target+1;i++) {
dp[i] = dp[i-1] + dp[i-2];
}
return dp[target];
}
}
(2)
时间复杂度:O(n)
空间复杂度:O(1)
改进:只需要三个变量即可 -->空间复杂度为O(1)
public class Solution {
public int jumpFloor(int target) {
int res = 1;
int pre = 1,preBefore = 1;
for (int i = 2;i < target+1;i++) {
res = pre + preBefore;
preBefore = pre;
pre = res;
}
return res;
}
}















 4万+
4万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









