







问题总结
现完成情况
-
使用方法
文本相似度计算方法:余弦相似度
聚类方法:K-Means -
结果及分析
公交坠江数据集 预设相似度值1.24 单位时间长度10min
时间段:2018-10-28 11:28 ----11-06 20:00 窗口数量:34
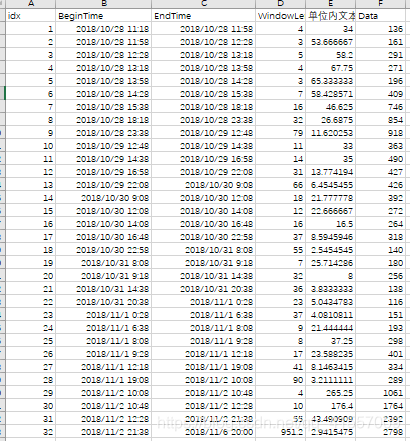
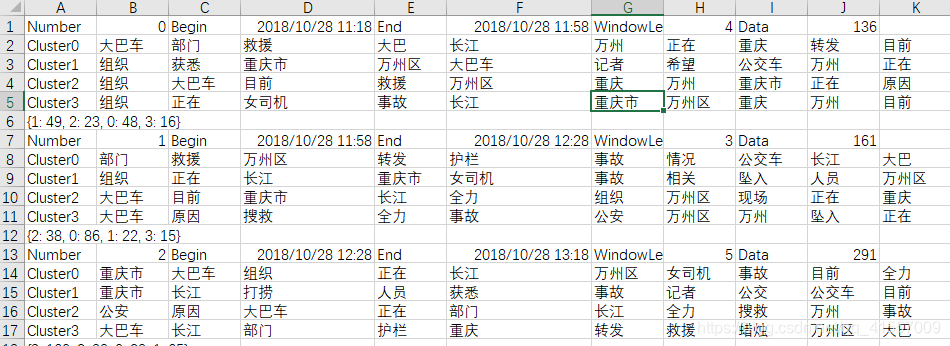
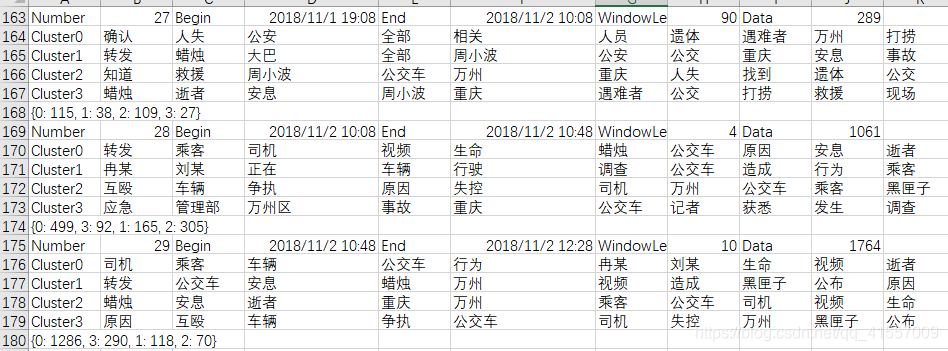
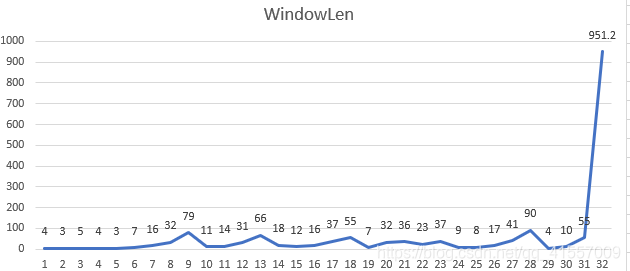
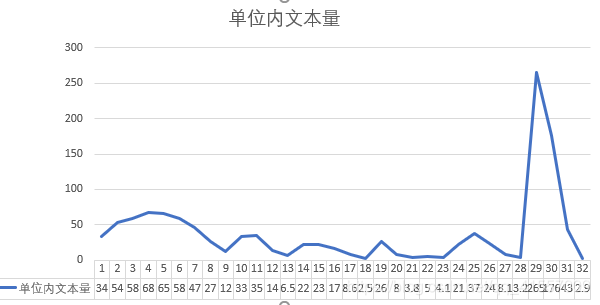
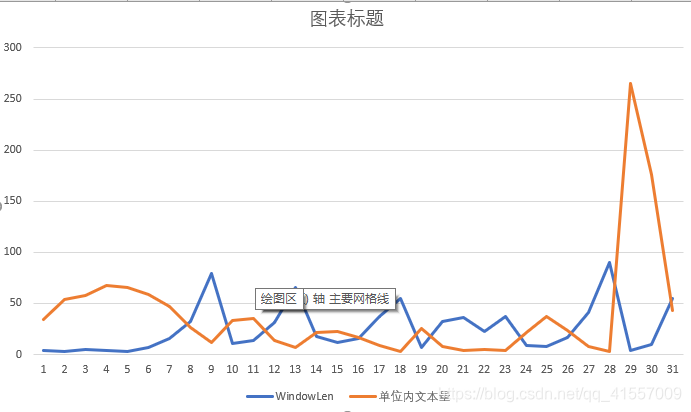
结果分析: -
窗口划分的整体趋势:窗口大小逐渐增大 因时间跨度较小 反应不是很强烈;
-
窗口划分的周期性:晚间(约晚十点到早八点)窗口划分大,发文量小。每天上午时段最活跃。
-
窗口长度和窗口内单位时间文本量有明显的负相关关系。整体上看,讨论热烈程度初始即为高水平并迅速上升至小高峰,随后逐渐下降,在事件结束前夕达到最高峰。此时认为事件发展到新阶段主题发生变化(现成视频曝光,热烈讨论事故责任)
存在的问题
- 相似论文:该论文思路为数据集预处理–LDA获取主题词–根据余弦相似度划分时间窗口–分析评价 。本实验思路为数据集预处理–根据余弦相似度划分时间窗口–k-Means聚类得到主题词–分析评价
- 对时间窗口的评价:
若对聚类结果评价:1.常用的准确率回归率等方法因标签问题难以实现。2.聚类的正确率等评价未必能反应窗口划分的合理性。认为聚类结果主题词的变化程度更有意义,用以验证相似度差异的正确性。
若直接对时间评价:整体上符合作息规律性和事件发展一般规律,但对于大型数据集如九寨沟数据集,时间跨度长文本量大,往往相邻窗口(特别是窗口很小时)主题词重合度高,难以解释。 - .缺少对比实验(因缺少相关指标):现使用的余弦相似度和K-Means为最基本版,没有替换方法或是改进。(仅实验了LDA,聚类效果明显不好,放弃尝试)
- 相邻窗口主题词相似度高:1.文本跨时间长,窗口划分细。2.计算相似度时,设定窗口内相似度比窗口间相似度重要。调整权重后主题词变化变得明显一些,未影响其他因素。














 537
537











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









