







目录
好好学习基础知识,提高自身修养^_^
本文是《程序员的自我修养-链接、装载与库》的读书记录
.c程序编译的全过程
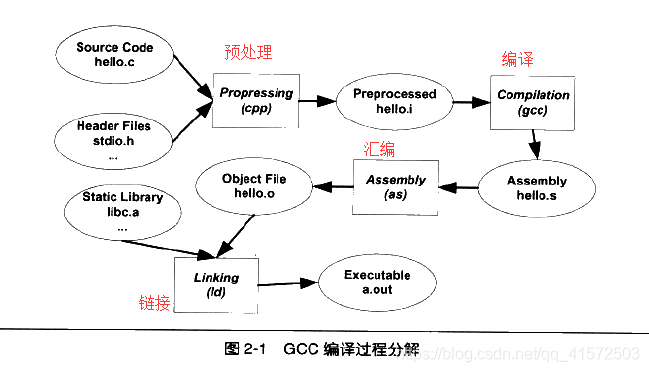
预处理:
预编译器将源代码.c文件和相关的头文件.h等预编译成.i文件。命令为
gcc -E hello.c -o hello.i- 将所有的“#define”删除,并且展开所有的宏定义。
- 处理所有条件预编译指令,比如“#if”、“#ifdef”、“#elif”、“#else”、“#endif”
- 处理“#include”预编译指令,将被包含的文件插入到该预编译指令的位置,注意,这个过程是递归进行的,也就是说被包含的文件可能还包含其他文件
- 删除所有的注释“//”和“/* */”。
- 添加行号和文件名标识,比如#2 “hello.c” 2 以便于编译时编译器产生调试用的行号信息以及用于编译时产生编译错误或警告时能够显示行号
- 保留所有#pragma编译器指令,因为编译器需要使用他们
编译:
编译过程就是把预处理完的文件进行一系列的词法分析、语法分析、语义分析以及优化后生成相应的汇编代码文件,命令为
gcc -S hello.i -o hello.s
汇编:
汇编器是将汇编代码转变成机器可以执行的指令,每一个汇编语句都几乎对应一条机器指令。所以汇编器的汇编过程相对于编译器来讲比较简单,他没有复杂的语法,也没有语义,也不需要做指令优化,只是根据汇编指令和机器指令的对照表一一翻译就可以了。
gcc -c hello.s -o hello.o
链接:

这些问题正是本书所需要介绍的内容,他们看似简单,其实涉及了编译、链接与库,甚至是操作系统一些很底层的内容。我们将紧紧围绕这些内容进行必要的分析,不过在分析这些内容之前,我们还是来关注一下上面这些过程中,编译器担任的一个什么样的角色。
编译器做了什么
- 词法分析
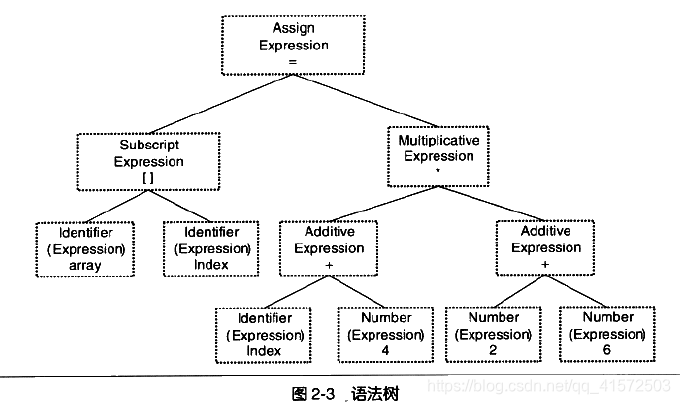
首先源代码程序被输入到扫描器scanner,运用一种类似于有限状态机finite state machine的算法可以很轻松地将源代码的字符序列分割成一系列的记号,比如
array[index] = (index + 4) * (2 + 6)会被分析成


词法分析产生的记号一般可以分为如下几类:关键字、标识符、字面量(包含数字、字符串等)和特殊符号(如加号、等号)
对于一些有预处理的语言比如c语言,他的宏替换和文件包含等工作一般不归入编译器的范围而交给一个独立的预处理器
- 语法分析
接下来语法分析器grammar parser将对由扫描器产生的记号进行语法分析,从而产生语法树。整个分析过程采用了上下文无关语法context-free grammar的分析手段。上面程序产生的语法树如下
- 语义分析
接下来由语义分析器来完成。前面的语法分析仅仅是完成了对表达式的语法层面的分析,但是他并不了解这个语句是否真正有意义,比如c语言里面两个指针做乘法运算是没有意义的,但是这个语句在语法上是合法的。编译器所能分析的语义是静态语义,所谓静态语义是指在编译器可以确定的语义,与之对应的是动态语义,就是只有在运行期才能确定的语义
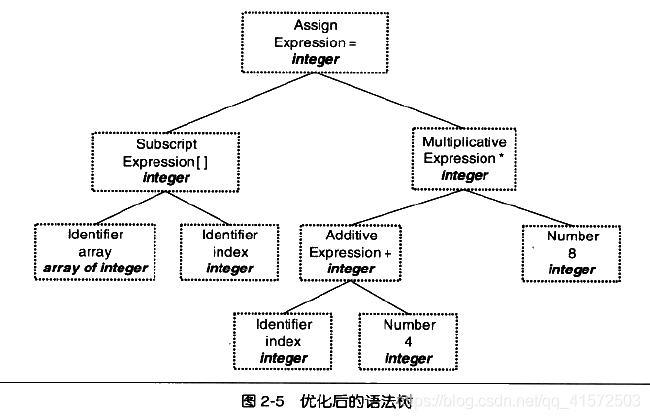
经过语义分析阶段以后,整个语法树的表达式都被标识了类型,如果有些类型需要做隐式转换,语义分析程序会在语法树中插入相应的转换节点。上面的语法树在经过语义分析阶段以后成为:

可以看到,每个表达式都被标识了类型
- 中间语言生成
现代的编译器有很多层次的优化,往往在源代码级别会有一个优化的过程,如(2+6)这个表达式可以被优化掉,因为他的值在编译器就可以确定,类似的还有很多其他复杂的优化过程,此处不详细描述了:
其实直接在语法树上做优化比较困难,所以源代码优化器往往将整个语法树转换成中间代码intermediate code,他是语法树的顺序表示,其实它已经非常接近目标代码了。但是它一般跟目标机器和运行时环境是无关的,比如他不包含数据的尺寸、变量地址和寄存器名字等。

array[index] = t2
中间代码使得编译器可以被分为前端和后端。前端负责产生于机器无关的中间代码,后端将中间代码转换成目标机器代码。这样对于一些可以跨平台的编译器而言,他们可以针对不同的平台使用同一个前端和针对不同的机器平台的数个后端
- 目标代码的生成与优化
编译器后端主要包括代码生成器和目标代码优化器。前者将中间代码转换成目标机器代码,这个过程十分依赖于目标机器,因为不同的机器有着不同的字长、寄存器、整数数据类型和浮点数数据类型等。

最后目标代码优化器对上述的目标代码进行优化,比如选择合适的寻址方式、使用位移来替代乘法运算、删除多余的指令等。上面的例子中,乘法由一条相对复杂的基址比例变址寻址的lea指令完成,随后由一条mov指令完成最后的赋值操作,这条mov指令的寻址方式与lea是一样的



- 再说链接
在计算机程序开发最开始的时候,程序员先把一个程序在纸上写好,当然当时没有很高级的语言,用的都是机器语言,甚至连汇编语言都没有。当程序要被运行时,程序员人工地将他写的程序写入到存储设备上,最原始的存储设备之一就是纸带,即在纸带上打相应的孔。
这个过程如下图,假设有一种计算机,它的每条指令是1字节,也就是8位,假设有一种跳转指令,它的高4位是0001,表示这是一条跳转指令,低4位存放的是跳转目的的绝对地址:即第一条指令就是一条跳转指令,它的目的地址是第5条指令。至于0和1怎么映射到纸带上,这个应该很容易理解,比如我们可以规定纸带上每行有8个孔位,每个孔位代表一位,穿孔表示0,未穿孔表示1.



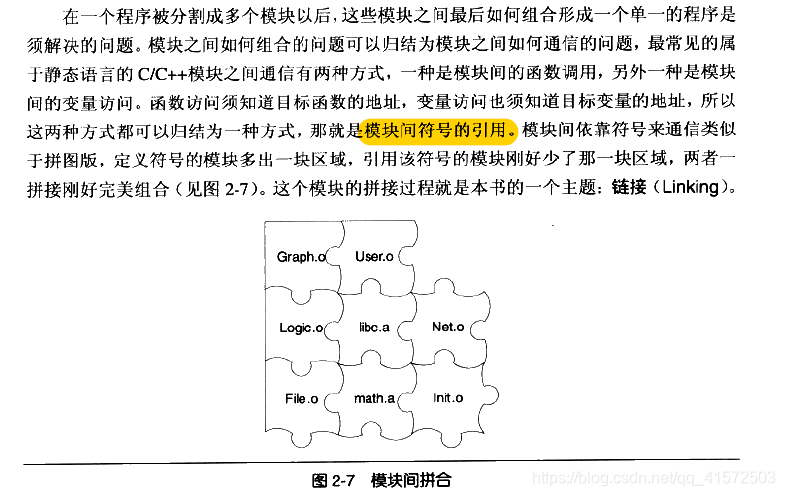
链接过程主要包括了地址和空间分配、符号决议和重定位等步骤。最机基本的静态链接过程如下图所示:
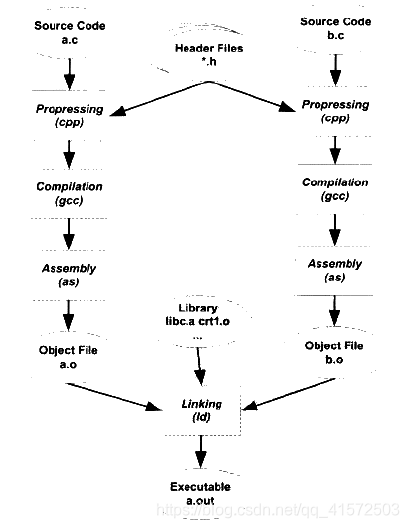

目标文件(ELF)
编译器编译源代码后生成的文件叫做目标文件(.o文件),其主要格式在windows下叫做PE portable executable,在linux下叫做ELF executable linkable format。他们都是COFF common file format格式的变种。
如下:


目标文件是什么样的
一个简单的程序被编译成目标文件后的结构如图:

ELF文件的开头是一个“文件头”,它描述了整个文件的文件属性,包括文件是否可执行、是静态链接还是动态链接及入口地址(如果是可执行文件)、目标硬件、目标操作系统等信息,文件头还包括一个段表,它其实是一个描述文件中各个段的数组。文件头后面就是各个段的内容,比如代码段保存的就是程序的指令(可被多个进程共享,节约内存占用),数据段保存的就是程序的静态变量等。

用一个实际例子挖掘目标文件
如果不彻底深入目标文件的具体细节,就像只知道tcp/ip协议是基于包的结构,却从来没有看到过包的结构是怎么样的,包的头部有哪些内容?目标地址和源地址是怎么存放的?
例子程序如下:
int printf(const char* format, ...);
int global_init_var = 84;
int global_uninit_var;
void func1(int i)
{
printf("%d\n", i);
}
int main(void)
{
static int static_var = 85;
static int static_var2;
int a=1;
int b;
func1(static_var + static_var2 + a + b);
return a;
}只编译:得到
gcc -c elf.c-rw-rw-r-- 1 ubuntu ubuntu 1928 Oct 6 15:56 elf.o使用binutils的工具objdump来查看object内部的结构,64位机器下:
ubuntu@VM-0-12-ubuntu:/home/chenjinan/sometest$ objdump -h elf.o
elf.o: file format elf64-x86-64
Sections:
Idx Name Size VMA LMA File off Algn
0 .text 00000057 0000000000000000 0000000000000000 00000040 2**0
CONTENTS, ALLOC, LOAD, RELOC, READONLY, CODE
1 .data 00000008 0000000000000000 0000000000000000 00000098 2**2
CONTENTS, ALLOC, LOAD, DATA
2 .bss 00000004 0000000000000000 0000000000000000 000000a0 2**2
ALLOC
3 .rodata 00000004 0000000000000000 0000000000000000 000000a0 2**0
CONTENTS, ALLOC, LOAD, READONLY, DATA
4 .comment 0000002c 0000000000000000 0000000000000000 000000a4 2**0
CONTENTS, READONLY
5 .note.GNU-stack 00000000 0000000000000000 0000000000000000 000000d0 2**0
CONTENTS, READONLY
6 .eh_frame 00000058 0000000000000000 0000000000000000 000000d0 2**3
CONTENTS, ALLOC, LOAD, RELOC, READONLY, DATAlinux下还有一个很不错的工具叫readelf,它是专门针对elf文件格式的解析器,很多时候它对elf文件的分析可以跟objdump想相互对照,所以我们下面会经常用到此工具。
参数-h 是把elf文件的各个段的基本信息打印出来,我们也可以使用-x打印出更多更详细的信息。
从上面的结果来看,除了最基本的代码段、数据段和bss段之外,还有3个段分别是只读数据段.rodata、注释信息段.comment和堆栈提示段.note.GNU-stack。
来看看几个重要的属性:
段长度size、段所在位置file offset、还有 “contents” “alloc”等段的属性,其中“content”表示该段在文件中存在,bss段没有“content”,表示他在elf文件中不存在,.note.GNU-stack虽然有“contents”,但是他的长度为0,先忽略。因此elf文件中存在的段大致如下(直接用书上的图了,偏移量和段长度有点不一样,不影响)

有一个专门的命令叫做“size”,可以用来查看elf文件的代码段、数据段和bss段的长度(dec表示3个段长度的和的十进制,hex表示十六进制)
ubuntu@VM-0-12-ubuntu:/home/chenjinan/sometest$ size elf.o
text data bss dec hex filename
179 8 4 191 bf elf.o- 代码段
objdump的-s参数可以将段的内容以十六进制的方式打印出来,-d参数可以将所有包含指令的段反汇编
ubuntu@VM-0-12-ubuntu:/home/chenjinan/sometest$ objdump -s -d elf.o
elf.o: file format elf64-x86-64
Contents of section .text:
0000 554889e5 4883ec10 897dfc8b 45fc89c6 UH..H....}..E...
0010 488d3d00 000000b8 00000000 e8000000 H.=.............
0020 0090c9c3 554889e5 4883ec10 c745f801 ....UH..H....E..
0030 0000008b 15000000 008b0500 00000001 ................
0040 c28b45f8 01c28b45 fc01d089 c7e80000 ..E....E........
0050 00008b45 f8c9c3 ...E...
Contents of section .data:
0000 54000000 55000000 T...U...
Contents of section .rodata:
0000 25640a00 %d..
Contents of section .comment:
0000 00474343 3a202855 62756e74 7520372e .GCC: (Ubuntu 7.
0010 342e302d 31756275 6e747531 7e31382e 4.0-1ubuntu1~18.
0020 30342e31 2920372e 342e3000 04.1) 7.4.0.
Contents of section .eh_frame:
0000 14000000 00000000 017a5200 01781001 .........zR..x..
0010 1b0c0708 90010000 1c000000 1c000000 ................
0020 00000000 24000000 00410e10 8602430d ....$....A....C.
0030 065f0c07 08000000 1c000000 3c000000 ._..........<...
0040 00000000 33000000 00410e10 8602430d ....3....A....C.
0050 066e0c07 08000000 .n......
Disassembly of section .text:
0000000000000000 <func1>:
0: 55 push %rbp
1: 48 89 e5 mov %rsp,%rbp
4: 48 83 ec 10 sub $0x10,%rsp
8: 89 7d fc mov %edi,-0x4(%rbp)
b: 8b 45 fc mov -0x4(%rbp),%eax
e: 89 c6 mov %eax,%esi
10: 48 8d 3d 00 00 00 00 lea 0x0(%rip),%rdi # 17 <func1+0x17>
17: b8 00 00 00 00 mov $0x0,%eax
1c: e8 00 00 00 00 callq 21 <func1+0x21>
21: 90 nop
22: c9 leaveq
23: c3 retq
0000000000000024 <main>:
24: 55 push %rbp
25: 48 89 e5 mov %rsp,%rbp
28: 48 83 ec 10 sub $0x10,%rsp
2c: c7 45 f8 01 00 00 00 movl $0x1,-0x8(%rbp)
33: 8b 15 00 00 00 00 mov 0x0(%rip),%edx # 39 <main+0x15>
39: 8b 05 00 00 00 00 mov 0x0(%rip),%eax # 3f <main+0x1b>
3f: 01 c2 add %eax,%edx
41: 8b 45 f8 mov -0x8(%rbp),%eax
44: 01 c2 add %eax,%edx
46: 8b 45 fc mov -0x4(%rbp),%eax
49: 01 d0 add %edx,%eax
4b: 89 c7 mov %eax,%edi
4d: e8 00 00 00 00 callq 52 <main+0x2e>
52: 8b 45 f8 mov -0x8(%rbp),%eax
55: c9 leaveq
56: c3 retq Contents of section .text:就是.text的数据以十六进制方式打印出来的内容,总共0x57字节,跟前面了解到的“.text”段长度符合,最左边一列是偏移量,中间4列是十六进制的内容,最右边一列是.text段的ASCII码形式。对照下面的反汇编结果,可以明显地看到,.text段里包含的正是elf.c里面两个函数func1和main的指令。.text段的第一个字节“0x55”就是func1函数的第一条“push %ebp”指令,而最后一个字节0xc3正是main函数的最后一条指令“ret”。
- 数据段和只读数据段
.data段保存的是那些已经初始化了的全局静态变量和局部静态变量。前面的elf.c代码里面一共有两个这样的变量,分别是global_uninit_var和int static_var。这两个变量每个4字节,所以.data这个段的大小为8个字节
elf.c里我们在调用printf的时候,用到了一个字符串常量“%d\n”,它是一种只读数据,所以塔被放到了.rodata段,其4个字节刚好是这个字符串常量的ASCII字节序,最后以\0结尾。
.rodata段存放的是只读变量(如const修饰的变量)和字符串常量。对于这个段的任何修改操作都会作为非法操作处理,保证了程序的安全性,另外在某些嵌入式平台下,有些存储区域是采用只读存储器的,如ROM,这样将.rodata段放在该存储区域中就可以保证程序访问存储器的正确性。(有些编译器会把字符串常量放在.data段而不会单独放在.rodata段,如g++)
- bss段
存放的是未初始化的全局变量和局部静态变量,如上述代码的global_uninit_var、static_var2就是存放在.bss段,其实更准确的说法是.bss段为他们预留了空间,但是我们看到的该段大小只有4个字节,与两个变量的大小8字节不符

- 其他段
elf文件可能包含其他的段,用来保存与程序相关的其他信息,如下
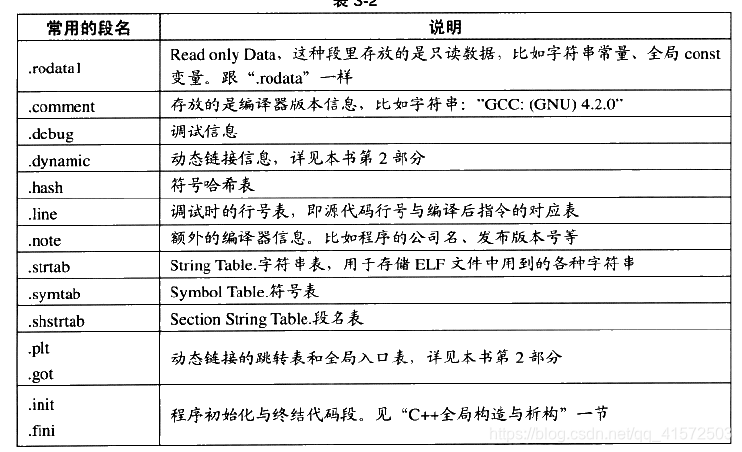


ELF文件结构描述
文件头
我们可以用readelf命令来详细查看elf文件:
ubuntu@VM-0-12-ubuntu:/home/chenjinan/sometest$ readelf -h elf.o
ELF Header:
Magic: 7f 45 4c 46 02 01 01 00 00 00 00 00 00 00 00 00
Class: ELF64
Data: 2's complement, little endian
Version: 1 (current)
OS/ABI: UNIX - System V
ABI Version: 0
Type: REL (Relocatable file)
Machine: Advanced Micro Devices X86-64
Version: 0x1
Entry point address: 0x0
Start of program headers: 0 (bytes into file)
Start of section headers: 1096 (bytes into file)
Flags: 0x0
Size of this header: 64 (bytes)
Size of program headers: 0 (bytes)
Number of program headers: 0
Size of section headers: 64 (bytes)
Number of section headers: 13
Section header string table index: 12从上面输出的结果可以看到,elf文件头中定义了elf魔数、文件机器字节长度、数据存储方式、版本、运行平台、ABI版本、ELF重定位类型、硬件平台、硬件平台版本、入口地址、程序头入口和长度、段表的位置和长度及段的数量等。
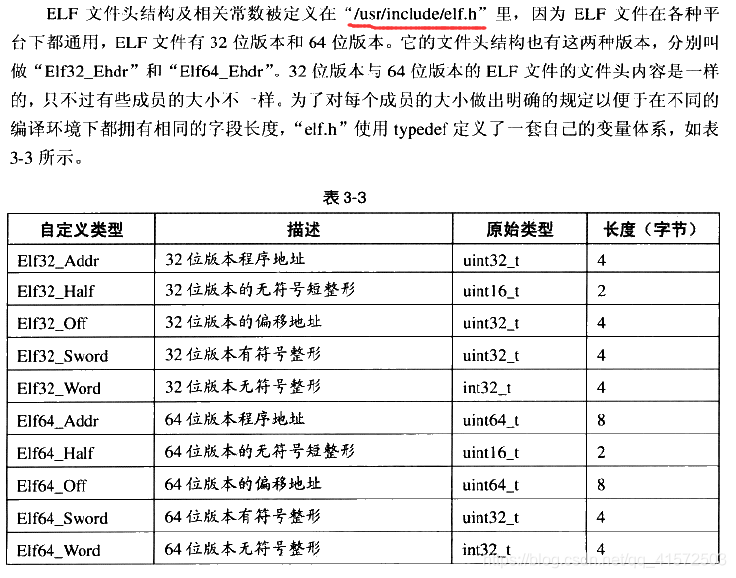
文件头结构如下:
/* ELF Header */
#define EI_NIDENT 16
typedef struct elfhdr {
unsigned char e_ident[EI_NIDENT]; /* ELF Identification */
Elf32_Half e_type; /* object file type */
Elf32_Half e_machine; /* machine */
Elf32_Word e_version; /* object file version */
Elf32_Addr e_entry; /* virtual entry point */
Elf32_Off e_phoff; /* program header table offset */
Elf32_Off e_shoff; /* section header table offset */
Elf32_Word e_flags; /* processor-specific flags */
Elf32_Half e_ehsize; /* ELF header size */
Elf32_Half e_phentsize; /* program header entry size */
Elf32_Half e_phnum; /* number of program header entries */
Elf32_Half e_shentsize; /* section header entry size */
Elf32_Half e_shnum; /* number of section header entries */
Elf32_Half e_shstrndx; /* section header table's "section
header string table" entry offset */
} Elf32_Ehdr;
typedef struct {
unsigned char e_ident[EI_NIDENT]; /* Id bytes */
Elf64_Quarter e_type; /* file type */
Elf64_Quarter e_machine; /* machine type */
Elf64_Half e_version; /* version number */
Elf64_Addr e_entry; /* entry point */
Elf64_Off e_phoff; /* Program hdr offset */
Elf64_Off e_shoff; /* Section hdr offset */
Elf64_Half e_flags; /* Processor flags */
Elf64_Quarter e_ehsize; /* sizeof ehdr */
Elf64_Quarter e_phentsize; /* Program header entry size */
Elf64_Quarter e_phnum; /* Number of program headers */
Elf64_Quarter e_shentsize; /* Section header entry size */
Elf64_Quarter e_shnum; /* Number of section headers */
Elf64_Quarter e_shstrndx; /* String table index */
} Elf64_Ehdr;
ELF文件头中各个成员的含义与readelf输出结果的对照表如下:
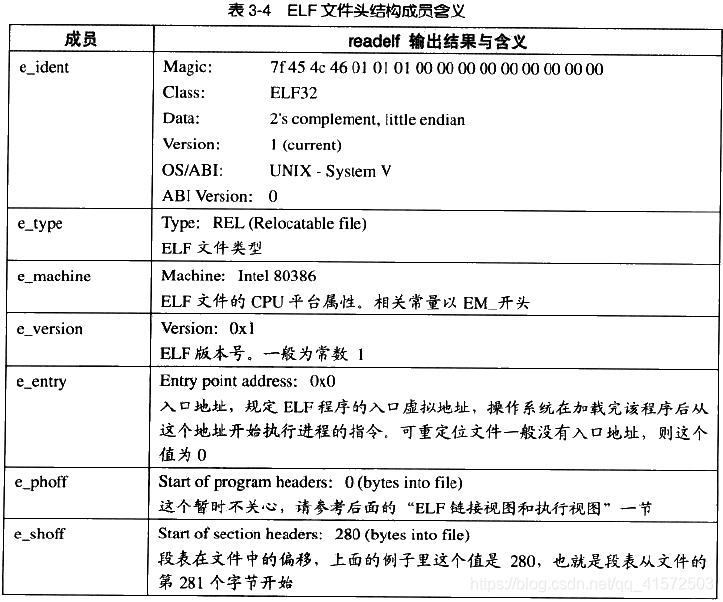
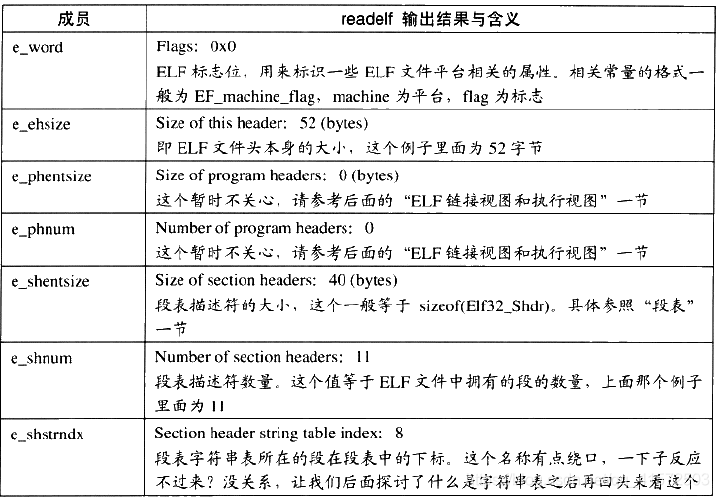
我们可以从前面readelf的输出看到,最前面的“Magic”的16个字节刚好对应“Elf32_Ehdr”的e_ident这个成员。这16个字节被ELF标准规定用来标识ELF文件的平台属性,比如这个ELF字长(32位/64位)、字节序、ELF文件版本,如图3-5所示。

最开始的4个字节是所有ELF文件都必须相同的标识码,分别为0x7F、0x45、0x4c、0x46,第一个字节对应ASCII字符里面的DEL控制符,后面3个字节刚好是ELF这3个字母的ASCII码。这4个字节又被称为ELF文件的魔数,几乎所有的可执行文件格式的最开始的几个字节都是魔数。比如a.out格式最开始两个字节为 0x01、0x07;PE/COFF文件最开始两个个字节为0x4d、0x5a,即ASCII字符MZ。这种魔数用来确认文件的类型,操作系统在加载可执行文件的时候会确认魔数是否正确,如果不正确会拒绝加载。
接下来的一个字节是用来标识ELF的文件类的,0x01表示是32位的,0x02表示是64位的;第6个字是字节序,规定该ELF文件是大端的还是小端的(见附录:字节序)。第7个字节规定ELF文件的主版本号,一般是1,因为ELF标准自1.2版以后就再也没有更新了。后面的9个字节ELF标准没有定义,一般填0,有些平台会使用这9个字节作为扩展标志。
各种魔数的由来
a.out格式的魔数为0x01、0x07,为什么会规定这个魔数呢?
UNIX早年是在PDP小型机上诞生的,当时的系统在加载一个可执行文件后直接从文件的第一个字节开始执行,人们一般在文件的最开始放置一条跳转(jump)指令,这条指令负责跳过接下来的7个机器字的文件头到可执行文件的真正入口。而0x01 0x07这两个字节刚好是当时PDP-11的机器的跳转7个机器字的指令。为了跟以前的系统保持兼容性,这条跳转指令被当作魔数一直被保留到了几十年后的今天。
计算机系统中有很多怪异的设计背后有着很有趣的历史和传统,了解它们的由来可以让我们了解到很多很有意思的事情。这让我想起了经济学里面所谓的“路径依赖”,其中一个很有意思的叫“马屁股决定航天飞机”的故事在网上流传很广泛,有兴趣的话你可以在google以“马屁股”和“航天飞机”作为关键字搜索一下。
ELF文件标准历史
20世纪90年代,一些厂商联合成立了一个委员会,起草并发布了一个ELF文件格式标准供公开使用,并且希望所有人能够遵循这项标准并且从中获益。1993年,委员会发布了ELF文件标准。当时参与该委员会的有来自于编译器的厂商,如Watcom和Borland;来自CPU的厂商如IBM和Intel;来自操作系统的厂商如IBM和Microsoft。1995年,委员会发布了ELF 1.2标准,自此委员会完成了自己的使命,不久就解散了。所以ELF文件格式标准的最新版本为1.2。
文件类型 e_type成员表示ELF文件类型,即前面提到过的3种ELF文件类型,每个文件类型对应一个常量。系统通过这个常量来判断ELF的真正文件类型,而不是通过文件的扩展名。相关常量以“ET_”开头,如表3-5所示。

段表
我们知道ELF文件中有各种各样的段,段表就是保存这些段的基本属性结构。编译器、链接器和装载器都是依靠段表来定位和访问各个段的属性的。段表在ELF文件中的位置由文件头的“e_shoff”成员决定。
前文中我们使用了“objdump -h”来查看ELF文件中包含的段,结果只看到了6个段。实际上objdump -h命令只是把ELF文件中关键的段显示了出来,而省略了其他的辅助性的段,比如:符号表、字符串表、段名字符串表、重定位表等。我们可以使用readelf工具来查看ELF文件的段,它显示出来的结果才是真正的段表结构:
ubuntu@VM-0-12-ubuntu:/home/chenjinan/sometest$ readelf -S elf.o
There are 13 section headers, starting at offset 0x448:
Section Headers:
[Nr] Name Type Address Offset
Size EntSize Flags Link Info Align
[ 0] NULL 0000000000000000 00000000
0000000000000000 0000000000000000 0 0 0
[ 1] .text PROGBITS 0000000000000000 00000040
0000000000000057 0000000000000000 AX 0 0 1
[ 2] .rela.text RELA 0000000000000000 00000338
0000000000000078 0000000000000018 I 10 1 8
[ 3] .data PROGBITS 0000000000000000 00000098
0000000000000008 0000000000000000 WA 0 0 4
[ 4] .bss NOBITS 0000000000000000 000000a0
0000000000000004 0000000000000000 WA 0 0 4
[ 5] .rodata PROGBITS 0000000000000000 000000a0
0000000000000004 0000000000000000 A 0 0 1
[ 6] .comment PROGBITS 0000000000000000 000000a4
000000000000002c 0000000000000001 MS 0 0 1
[ 7] .note.GNU-stack PROGBITS 0000000000000000 000000d0
0000000000000000 0000000000000000 0 0 1
[ 8] .eh_frame PROGBITS 0000000000000000 000000d0
0000000000000058 0000000000000000 A 0 0 8
[ 9] .rela.eh_frame RELA 0000000000000000 000003b0
0000000000000030 0000000000000018 I 10 8 8
[10] .symtab SYMTAB 0000000000000000 00000128
0000000000000198 0000000000000018 11 11 8
[11] .strtab STRTAB 0000000000000000 000002c0
0000000000000072 0000000000000000 0 0 1
[12] .shstrtab STRTAB 0000000000000000 000003e0
0000000000000061 0000000000000000 0 0 1
Key to Flags:
W (write), A (alloc), X (execute), M (merge), S (strings), I (info),
L (link order), O (extra OS processing required), G (group), T (TLS),
C (compressed), x (unknown), o (OS specific), E (exclude),
l (large), p (processor specific)readelf输出的结果就是ELF文件段表的内容。它是一个以“Elf64_Shdr”结构体为元素的数组,元素个数就等于段的个数。“Elf64_Shdr”又被称为段描述符。
struct Elf32_Shdr
{
Elf32_Word sh_name; /* Section name (string tbl index) */
Elf32_Word sh_type; /* Section type */
Elf32_Word sh_flags; /* Section flags */
Elf32_Addr sh_addr; /* Section virtual addr at execution */
Elf32_Off sh_offset; /* Section file offset */
Elf32_Word sh_size; /* Section size in bytes */
Elf32_Word sh_link; /* Link to another section */
Elf32_Word sh_info; /* Additional section information */
Elf32_Word sh_addralign; /* Section alignment */
Elf32_Word sh_entsize; /* Entry size if section holds table */
};
struct Elf64_Shdr
{
Elf64_Word sh_name; /* Section name (string tbl index) */
Elf64_Word sh_type; /* Section type */
Elf64_Xword sh_flags; /* Section flags */
Elf64_Addr sh_addr; /* Section virtual addr at execution */
Elf64_Off sh_offset; /* Section file offset */
Elf64_Xword sh_size; /* Section size in bytes */
Elf64_Word sh_link; /* Link to another section */
Elf64_Word sh_info; /* Additional section information */
Elf64_Xword sh_addralign; /* Section alignment */
Elf64_Xword sh_entsize; /* Entry size if section holds table */
};各个成员含义如表:
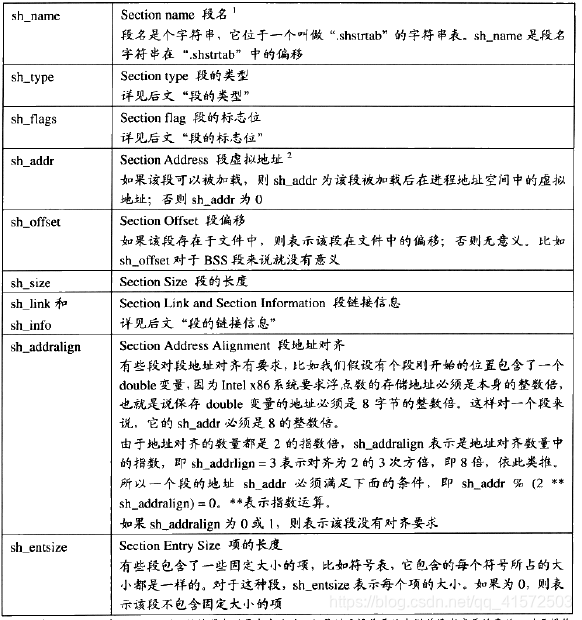

(段的类型和段的标志见p77,此处略去)
我们对照“readelf -S” 的输出结果,可以明显看到,结构体的每一个成员对应于输出结果中从第二列“name”开始的每一列。
因此,ELF文件中段的位置分布如下:(直接拿书上的了,我的机器是64位,略有差别)
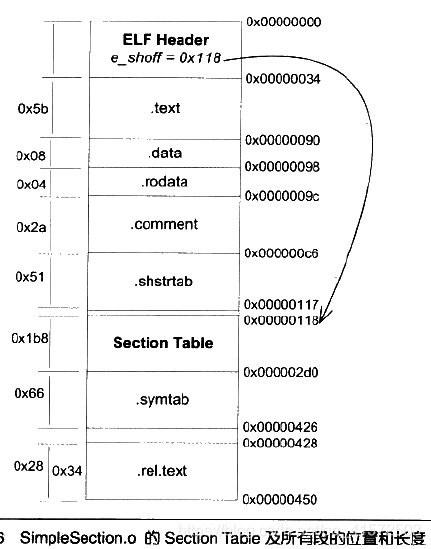
SectionTable的长度为0x1b8,也就是440字节,它包含了11个段描述符,每个段描述符为40个字节,这个长度刚好等于sizeof(Elf32_Shdr)。整个文件的最后一个段“.rel.text”结束后,长度为0x450,即1104字节,刚好就是SimpleSection.o的文件长度。中间SectionTable和.rel.text因为对齐的原因,与前面的段之间分别有一个字节和两个字节的间隔。
重定位表
分析静态链接过程时详细展开
字符串表
ELF文件中用到了很多字符串,比如段名、变量名等。因为字符串的长度往往是不定的,所以用固定的结构来表示它比较困难。一种很常见的做法是把字符串集中起来存放到一个表,然后使用字符串再表中的偏移来引用字符串,如:
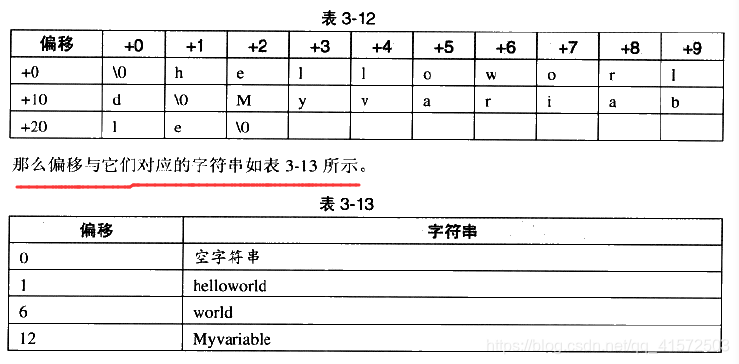
通过这种方法,在ELF文件中引用字符串只须给出一个数字下标即可,不用考虑字符串长度的问题。一般字符串表在ELF文件中也以段的形式保存,常见的段名为“.strtab”或".shstrtab"。这两个字符串表分别为字符串表和段表字符串表。顾名思义,字符串表用来保存普通的字符串,比如符号的名字;段表字符串表用来保存段表中用到的字符串,最常见的就是段名。
链接的接口-符号
链接过程的本质就是要把多个不同的目标文件之间相互“粘”到一起,为了使不同的目标文件之间能够相互粘合,这些目标文件之间必须要有固定的规则才行。在链接中,目标文件之间相互拼合实际上是目标文件之间对地址的引用,即对函数和变量的地址的引用。比如目标文件B要用带了目标文件A中的函数foo,那么我们就称A定义define了函数foo,目标文件B引用了A中的函数foo。这两个概念也同样适用于变量。在链接中,我们将函数和变量统称为符号Symbol,函数名和变量名就是符号名Symbol Name
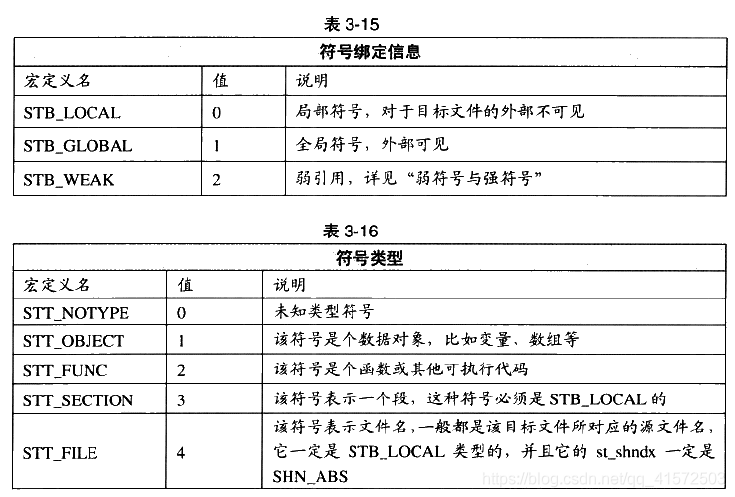
每一个目标文件都会有一个相应的符号表Symbol Table,这个表里面记录了目标文件中所用到的所有符号。每个定义的符号有一个对应的值,叫做符号值,对于变量和函数来说,符号值就是它们的地址,除了函数和变量之外,还存在其他几种不常用到的符号,我们将符号表中所有符号进行分类,它们可能是下面这些类型中的一种:

对于我们来说,最值得关注的就是全局符号,即第一类和第二类。因为链接过程只关心全局符号的相互“粘合”,局部符号、段名、行号等都是次要的,他们对于其他目标文件来说是“不可见”的,在链接过程中也是无关紧要。我们可以使用readelf、objdump、nm等来查看ELF文件的符号表,如:
ubuntu@VM-0-12-ubuntu:/home/chenjinan/sometest$ nm elf.o
0000000000000000 T func1
0000000000000000 D global_init_var
U _GLOBAL_OFFSET_TABLE_
0000000000000004 C global_uninit_var
0000000000000024 T main
U printf
0000000000000004 d static_var.1802
0000000000000000 b static_var2.1803- ELF符号表结构
ELF文件中的符号表往往是文件中的一个段,段名一般叫".symtab"。符号表的结构就是一个Elf32_Sym结构的数组,每个结构对应一个符号,结构体定义如下:
/* Symbol table entry. */
typedef struct
{
Elf32_Word st_name; /* Symbol name (string tbl index) */
Elf32_Addr st_value; /* Symbol value */
Elf32_Word st_size; /* Symbol size */
unsigned char st_info; /* Symbol type and binding */
unsigned char st_other; /* Symbol visibility */
Elf32_Section st_shndx; /* Section index */
} Elf32_Sym;
typedef struct
{
Elf64_Word st_name; /* Symbol name (string tbl index) */
unsigned char st_info; /* Symbol type and binding */
unsigned char st_other; /* Symbol visibility */
Elf64_Section st_shndx; /* Section index */
Elf64_Addr st_value; /* Symbol value */
Elf64_Xword st_size; /* Symbol size */
} Elf64_Sym;我们可以用readelf查看ELD文件的符号:
ubuntu@VM-0-12-ubuntu:/home/chenjinan/sometest$ readelf -s elf.o
Symbol table '.symtab' contains 17 entries:
Num: Value Size Type Bind Vis Ndx Name
0: 0000000000000000 0 NOTYPE LOCAL DEFAULT UND
1: 0000000000000000 0 FILE LOCAL DEFAULT ABS elf.c
2: 0000000000000000 0 SECTION LOCAL DEFAULT 1
3: 0000000000000000 0 SECTION LOCAL DEFAULT 3
4: 0000000000000000 0 SECTION LOCAL DEFAULT 4
5: 0000000000000000 0 SECTION LOCAL DEFAULT 5
6: 0000000000000004 4 OBJECT LOCAL DEFAULT 3 static_var.1802
7: 0000000000000000 4 OBJECT LOCAL DEFAULT 4 static_var2.1803
8: 0000000000000000 0 SECTION LOCAL DEFAULT 7
9: 0000000000000000 0 SECTION LOCAL DEFAULT 8
10: 0000000000000000 0 SECTION LOCAL DEFAULT 6
11: 0000000000000000 4 OBJECT GLOBAL DEFAULT 3 global_init_var
12: 0000000000000004 4 OBJECT GLOBAL DEFAULT COM global_uninit_var
13: 0000000000000000 36 FUNC GLOBAL DEFAULT 1 func1
14: 0000000000000000 0 NOTYPE GLOBAL DEFAULT UND _GLOBAL_OFFSET_TABLE_
15: 0000000000000000 0 NOTYPE GLOBAL DEFAULT UND printf
16: 0000000000000024 51 FUNC GLOBAL DEFAULT 1 main第一列num表示符号表数组的下标,从0开始,共16个符号
第二列value就是符号值,即st_value
第三列size为符号的大小,即st_size
第四列和第五列分别为符号类型和绑定信息,即对应st_info的低4位和高28位
第六列vis目前在c/c++中未使用
第七列nsx即st_shndx,表示该符号所属的段
最后一列就是符号名称
其中符号类型和绑定信息见下:
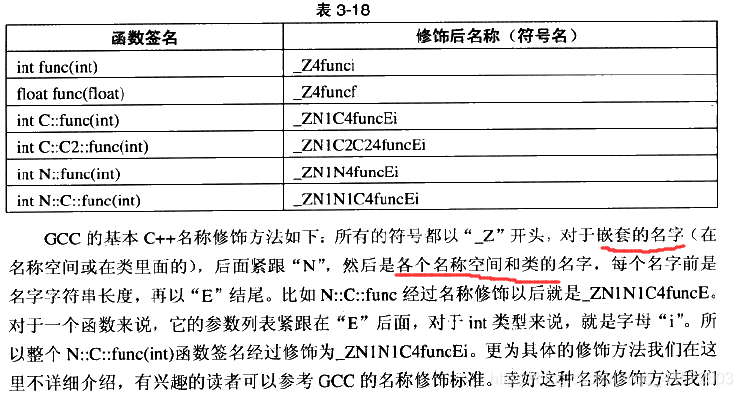
我们知道,c++有命名重整(name mangling)的机制,用以实现函数重载等功能。还有命名空间机制,允许在不同的名称空间有多个同样名字的符号。
编译器在将c++源代码编译成目标文件时,会将函数和变量的名字进行修饰,形成符号名,也就是说,目标文件中的函数和变量名是经过编译器命名重整后的符号名,修饰的简单例子如下:
c++ filt这个工具可以用来解析被修饰过的名称(函数名和变量名),比如:
$ c++filt _ZN1N1C4funcEi
N::C::func(int)
extern“C”
很多时候我们会碰到有些头文件声明了一些C语言的函数和全局变量,但是这个头文件可能会被C语言代码或者C++代码包含。比如很常见的,我们的C语言库函数中的string.h中声明了memset函数,它的原型如下:
void *memset(void *, int , size_t);如果不加任何处理,当C程序包含string.h,并且用到了memset这个函数,编译器会将memset符号引用正确处理;但是在C++语言程序中,编译器就会认为memset函数是一个c++函数,将memset的符号修饰成_Z6memsetPvii,这样链接器就无法与C语言库中的memset符号进行链接。所以对于c++来说,必须使用extern “C”来声明memset这个函数。
我们常用c++的宏“__cplusplus” (c++编译器会在编译c++程序时默认定义这个宏) 结合条件宏来判断当前编译单元是不是c++代码,如下:
#ifdef __cplusplus
extern "C"{
#endif
void *memset(void*,int,size_t);
#ifdef __cplusplus
}
#endif如果当前编译单元是c++代码,那么memset会在extern “C”里面被声明;如果是C代码,就直接声明。
强弱符号的概念见 强弱符号
在《深入理解计算机系统》一书中看到:
链接器的输人是一组可重定位目标模块。每个模块定义一组符号,有些是局部的(只对定义该符号的模块可见),有些是全局的(对其他模块也可见)。如果多个模块定义同名的全局符号,会发生什么呢?下面是Linux 编译系统采用的方法。
在编译时,编译器向汇编器输出每个全局符号,或者是强(strong)或者是弱(weak),汇编器把这个信息隐含地编码在可重定位目标文件的符号表里。函数和已初始化的全局变量是强符号,未初始化的全局变量是弱符号。
根据强弱符号的定义,Linux 链接器使用下面的规则来处理多重定义的符号名
* 规则1: 不允许有多个同名的强符号。
* 规则2: 如果有一个强符号和多个弱符号同名,那么选择强符号。
* 规则3: 如果有多个弱符号同名,那么从这些弱符号中任意选择一个。
比如,假设我们试图编译和链接下面两个C 模块:
/* foo1.c */
int main(){
return 0;
}
/* bar1.c */
int main(){
return 0;
}在这个情况中,链接器将生成一条错误信息,因为强符号main 被定义了多次(规则1):

相似地,链接器对于下面的模块也会生成一条错误信息,因为强符号X 被定义了两次(规则1):
/* foo2.c */
int x = 15213;
int main(){
return 0;
}
/* bar2.c */
int x = 15213;
void f()
{}然而,如果在一个模块里X 未被初始化,那么链接器将安静地选择在另一个模块中定义的强符号(规则2):
/* foo3.c */
#include <stdio.h>
void f(void);
int x = 15213;
int main(){
f();
printf("x = %d\n", x);
return 0;
}
/* bar3.c */
int x;
void f()
{
x = 15212;
}在运行时,函数f 将X 的值由15213 改为15212,这会给main 函数的作者带来不受欢迎的意外!注意,链接器通常不会表明它检测到多个x 的定义:
ubuntu@VM-0-12-ubuntu:/home/chenjinan/deepincomputer$ gcc -o foobar3 foo3.c bar3.c
ubuntu@VM-0-12-ubuntu:/home/chenjinan/deepincomputer$ ./foobar3
x = 15212如果x 有两个弱定义,也会发生相同的事情(规则3).
规则2 和规则3 的应用会造成一些不易察觉的运行时错误,对于不警觉的程序员来说,是很难理解的,尤其是如果重复的符号定义还有不同的类型时。考虑下面这个例子,其中x 不幸地在一个模块中定义为int, 而在另一个模块中定义为double:
/* foo5.c */
#include <stdio.h>
void f(void);
int x = 15213;
int y = 15212;
int main(){
f();
printf("x = 0x%x y = 0x%x \n", x,y);
printf("y = %d\n",y);
printf("x addr = %p y addr = %p \n", &x,&y);
return 0;
}
/* bar5.c */
double x;
void f()
{
x = -0.0;
}在一台x86-64/Linux 机器上,double 类型是8 个字节,而int 类型是4 个字节。在我们的系统中,x 的地址是0x558e7ade2010, y 的地址是0x558e7ade2014。因此,bar5.c 的第6 行中的赋值x= -0.0 将用负零的双精度浮点表示覆盖内存中x 和y 的位置!
ubuntu@VM-0-12-ubuntu:/home/chenjinan/deepincomputer$ gcc -o foobar3 foo3.c bar3.c
/usr/bin/ld: Warning: alignment 4 of symbol `x' in /tmp/ccauYNR0.o is smaller than 8 in /tmp/cccfF7Ch.o
ubuntu@VM-0-12-ubuntu:/home/chenjinan/deepincomputer$ ./foobar3
x = 0x0 y = 0x80000000
y = -2147483648
x addr = 0x558e7ade2010 y addr = 0x558e7ade2014 这是一个细微而令人讨厌的错误,尤其是因为它只会触发链接器发出一条警告,而且通常要在程序执行很久以后才表现出来,且远离错误发生地。在一个拥有成百上千个模块的大型系统中,这种类型的错误相当难以修正,尤其因为许多程序员根本不知道链接器是如何工作的。当你怀疑有此类错误时,用像GCC-fno-common标志这样的选项调用链接器,这个选项会告诉链接器,在遇到多重定义的全局符号时,触发一个错误。或者使用-Werror选项,它会把所有的警告都变为错误。
在7.5 节中,我们看到了编译器如何按照一个看似绝对的规则来把符号分配为COMMON 和.bss实际上,采用这个惯例是由于在某些情况中链接器允许多个模块定义同名的全局符号。当编译器在翻译某个模块时,遇到一个弱全局符号,比如说x, 它并不知道其他模块是否也定义了x,如果是,它无法预测链接器该使用x 的多重定义中的哪一个, 所以编译器把x 分配成COMMON,把决定权留给链接器。另一方面,如果x 初始化为0,那么它是一个强符号(因此根据规则2 必须是唯一的), 所以编译器可以很自信地将它分配成.bss。类似地,静态符号的构造就必须是唯一的,所以编译器可以自信地把它们分配成.data 或.bss。
静态链接
以a.c b.c为例子展示两个目标文件是如何链接成一个可执行文件的
a.c:
extern int shared;
int main(){
int a = 100;
swap(&a,&shared);
} b.c:
int shared = 1;
void swap(int *a, int*b)
{
*a ^= *b ^= *a ^= *b;
}gcc -c a.c b.c 之后得到了a.o b.o两个目标文件,我们接下来要做的就是把这两个目标文件链接在一起并最终形成一个可执行文件。
空间与地址分配
我们知道,可执行文件中的代码段和数据段都是由输入的目标文件中合并而来的。那么我们链接过程就很明显产生了第一个问题:对于多个输入目标文件,链接器如何将他们的各个段合并到输出文件?或者说,输出文件中的空间如何分配给输入文件?
- 方式一:按序叠加
最简单的方案就是将输入的目标文件按照次序叠加起来:
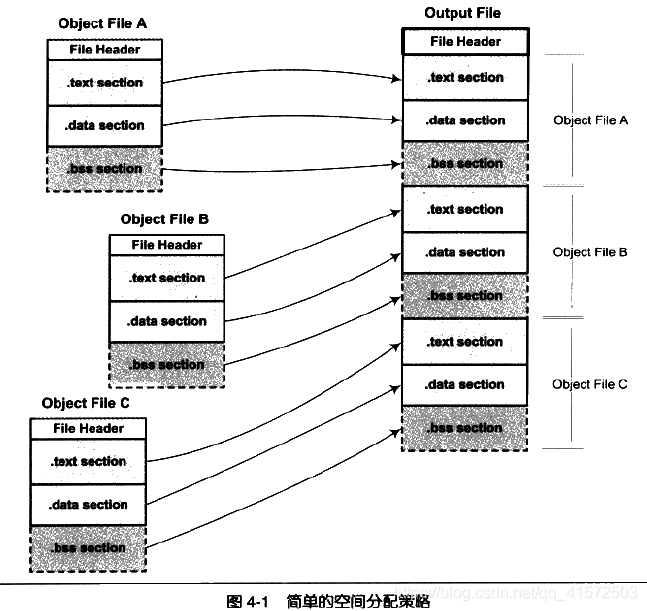
这种做法存在问题:在有很多输入文件的情况下,输出文件将会有很多零散的段。这种做法非常浪费空间,因为每个段都需要有一定的地址和空间对齐要求,比如对于x86的硬件来说,段的加载地址和空间的对齐单位是页,也就是4096字节。那么就是说如果一个段的长度只有1字节,它也要在内存中占用4096字节,这样会造成内存空间大量的内部碎片。
- 方案二:相似段合并
一种更实际的方法是将相同性质的段合并到一起,比如将所有输入文件的“.text”合并到输出文件的“.text”段,接着是“.data”段、“.bss”段。p100
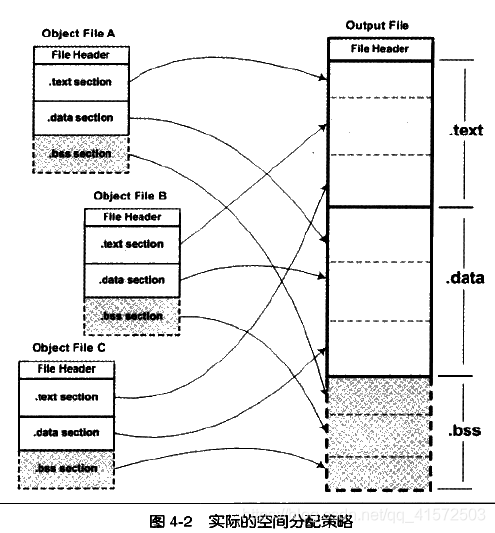
现在的链接器空间分配策略基本上采用这种方法,一般使用两步链接(two-pass linking)
第一步: 空间与地址分配
扫描所有的输入目标文件,并且获得它们各个段的长度、属性和位置,并将输入目标文件中的符号表的所有符号定义和符号引用收集起来,统一放到一个全局符号表。这一步中,链接器能够获得所有输入目标文件的段长度,并且将他们合并,计算输出文件中各个段合并后的长度与位置,并建立映射关系。
第二步: 符号解析与重定位
使用上一步的信息,读取输入文件中段的数据、重定位信息,并且进行符号解析与重定位、调整代码中的地址等。
我们可以使用ld链接器将a.o b.o 链接起来:
ubuntu@VM-0-12-ubuntu:/home/chenjinan/sometest/elf$ ld a.o b.o -e main -o ab
a.o: In function `main':
a.c:(.text+0x4b): undefined reference to `__stack_chk_fail'
ubuntu@VM-0-12-ubuntu:/home/chenjinan/sometest/elf$ gcc a.o b.o -o ab用ld链接时报错了undefined reference to `__stack_chk_fail',用gcc不报错
网上说报这个错误应该在Makefile中的$(CFLAGS)后面加上-fno-stack-protector,是取消堆栈保护检查
链接前后各个段的属性如下:
ubuntu@VM-0-12-ubuntu:/home/chenjinan/sometest/elf$ objdump -h a.o
a.o: file format elf64-x86-64
Sections:
Idx Name Size VMA LMA File off Algn
0 .text 00000051 0000000000000000 0000000000000000 00000040 2**0
CONTENTS, ALLOC, LOAD, RELOC, READONLY, CODE
1 .data 00000000 0000000000000000 0000000000000000 00000091 2**0
CONTENTS, ALLOC, LOAD, DATA
2 .bss 00000000 0000000000000000 0000000000000000 00000091 2**0
ALLOC
3 .comment 0000002c 0000000000000000 0000000000000000 00000091 2**0
CONTENTS, READONLY
...
ubuntu@VM-0-12-ubuntu:/home/chenjinan/sometest/elf$ objdump -h b.o
b.o: file format elf64-x86-64
Sections:
Idx Name Size VMA LMA File off Algn
0 .text 0000004b 0000000000000000 0000000000000000 00000040 2**0
CONTENTS, ALLOC, LOAD, READONLY, CODE
1 .data 00000004 0000000000000000 0000000000000000 0000008c 2**2
CONTENTS, ALLOC, LOAD, DATA
2 .bss 00000000 0000000000000000 0000000000000000 00000090 2**0
ALLOC
3 .comment 0000002c 0000000000000000 0000000000000000 00000090 2**0
CONTENTS, READONLY
...
ubuntu@VM-0-12-ubuntu:/home/chenjinan/sometest/elf$ objdump -h ab
ab: file format elf64-x86-64
Sections:
Idx Name Size VMA LMA File off Algn
...
CONTENTS, ALLOC, LOAD, READONLY, CODE
13 .text 00000222 0000000000000560 0000000000000560 00000560 2**4
CONTENTS, ALLOC, LOAD, READONLY, CODE
...
CONTENTS, ALLOC, LOAD, DATA
22 .data 00000014 0000000000201000 0000000000201000 00001000 2**3
CONTENTS, ALLOC, LOAD, DATA
23 .bss 00000004 0000000000201014 0000000000201014 00001014 2**0
ALLOC
24 .comment 0000002b 0000000000000000 0000000000000000 00001014 2**0
CONTENTS, READONLYVMA是virutal memory address 虚拟地址,LMA load memory address即加载地址,正常情况下两个值是一样的,但在有些嵌入式系统中,特别是那些将程序放在ROM的系统中,LMA VMA是不同的,这里我们只需关注VMA即可
链接前后程序所使用的地址已经是程序在进程中的虚拟地址,即VMA和size。在链接之前,目标文件所有段的VMA都是0,因为虚拟空间还没有分配,所以默认是0.等到链接之后,可执行文件ab中的各个段都被分配到了相应的虚拟地址,可见.text .data 段的地址和大小,程序虚拟地址如图:(书上程序的地址分配,与我机器上的略有不同)
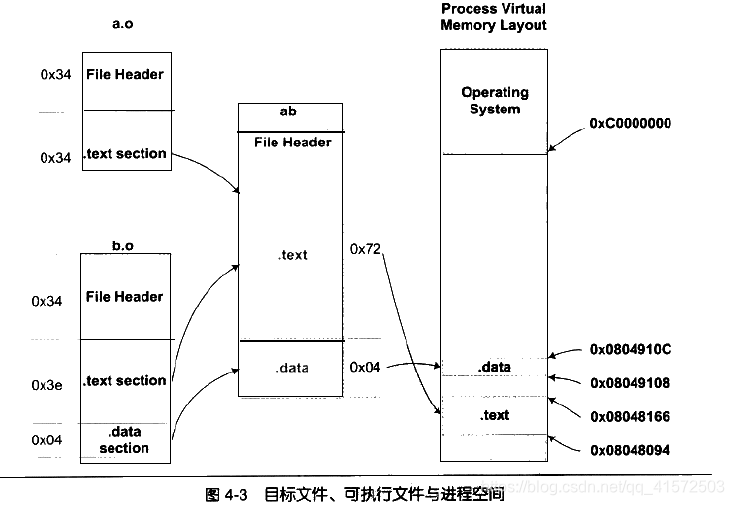
图中省略了.commom .bss和其他段的内存分布。
我们可以看看链接前后符号的地址变化:
使用objdump -d 可以看到链接前的a.o的反汇编:
ubuntu@VM-0-12-ubuntu:/home/chenjinan/sometest/elf$ objdump -d a.o
a.o: file format elf64-x86-64
Disassembly of section .text:
0000000000000000 <main>:
0: 55 push %rbp
1: 48 89 e5 mov %rsp,%rbp
4: 48 83 ec 10 sub $0x10,%rsp
8: 64 48 8b 04 25 28 00 mov %fs:0x28,%rax
f: 00 00
11: 48 89 45 f8 mov %rax,-0x8(%rbp)
15: 31 c0 xor %eax,%eax
17: c7 45 f4 64 00 00 00 movl $0x64,-0xc(%rbp)
1e: 48 8d 45 f4 lea -0xc(%rbp),%rax
22: 48 8d 35 00 00 00 00 lea 0x0(%rip),%rsi # 29 <main+0x29> shared的地址00000000
29: 48 89 c7 mov %rax,%rdi
2c: b8 00 00 00 00 mov $0x0,%eax
31: e8 00 00 00 00 callq 36 <main+0x36> //调用swap
36: b8 00 00 00 00 mov $0x0,%eax
3b: 48 8b 55 f8 mov -0x8(%rbp),%rdx
3f: 64 48 33 14 25 28 00 xor %fs:0x28,%rdx
46: 00 00
48: 74 05 je 4f <main+0x4f>
4a: e8 00 00 00 00 callq 4f <main+0x4f>
4f: c9 leaveq
50: c3 retq 未进行空间分配前,main的起始地址为0x0000000000000000,等空间分配完成后,各个函数才会确定自己在虚拟空间中的位置
64位机器用的是rsp,rbp,32位机器是esp,ebp,分别表示栈顶和栈底
----------------------------------------------------------------------------------------------
寄存器简介
X86-64中,所有寄存器都是64位,相对32位的x86来说,标识符发生了变化,比如:从原来的%ebp变成了%rbp。为了向后兼容性,%ebp依然可以使用,不过指向了%rbp的低32位。
X86-64寄存器的变化,不仅体现在位数上,更加体现在寄存器数量上。新增加寄存器%r8到%r15。加上x86的原有8个,一共16个寄存器。
刚刚说到,寄存器集成在CPU上,存取速度比存储器快好几个数量级,寄存器多了,GCC就可以更多的使用寄存器,替换之前的存储器堆栈使用,从而大大提升性能。
让寄存器为己所用,就得了解它们的用途,这些用途都涉及函数调用,X86-64有16个64位寄存器,分别是:%rax,%rbx,%rcx,%rdx,%esi,%edi,%rbp,%rsp,%r8,%r9,%r10,%r11,%r12,%r13,%r14,%r15。其中:
- %rax 作为函数返回值使用。
- %rsp 栈指针寄存器,指向栈顶
- %rdi,%rsi,%rdx,%rcx,%r8,%r9 用作函数参数,依次对应第1参数,第2参数。。。
- %rbx,%rbp,%r12,%r13,%14,%15 用作数据存储,遵循被调用者使用规则,简单说就是随便用,调用子函数之前要备份它,以防他被修改
- %r10,%r11 用作数据存储,遵循调用者使用规则,简单说就是使用之前要先保存原值
----------------------------------------------------------------------------------------------------------------------------
链接之后:
ubuntu@VM-0-12-ubuntu:/home/chenjinan/sometest/elf$ objdump -d ab
ab: file format elf64-x86-64
...
000000000000066a <main>:
66a: 55 push %rbp
66b: 48 89 e5 mov %rsp,%rbp
66e: 48 83 ec 10 sub $0x10,%rsp
672: 64 48 8b 04 25 28 00 mov %fs:0x28,%rax
679: 00 00
67b: 48 89 45 f8 mov %rax,-0x8(%rbp)
67f: 31 c0 xor %eax,%eax
681: c7 45 f4 64 00 00 00 movl $0x64,-0xc(%rbp)
688: 48 8d 45 f4 lea -0xc(%rbp),%rax
68c: 48 8d 35 7d 09 20 00 lea 0x20097d(%rip),%rsi # 201010 <shared> 重定位为7d 09 20 00
693: 48 89 c7 mov %rax,%rdi
696: b8 00 00 00 00 mov $0x0,%eax
69b: e8 1b 00 00 00 callq 6bb <swap> //调用swap
6a0: b8 00 00 00 00 mov $0x0,%eax
6a5: 48 8b 55 f8 mov -0x8(%rbp),%rdx
6a9: 64 48 33 14 25 28 00 xor %fs:0x28,%rdx
6b0: 00 00
6b2: 74 05 je 6b9 <main+0x4f>
6b4: e8 87 fe ff ff callq 540 <__stack_chk_fail@plt>
6b9: c9 leaveq
6ba: c3 retq
00000000000006bb <swap>:
6bb: 55 push %rbp
...我们可以看到,swap函数和shared的地址都被重定位了
那么链接器是怎么知道哪些指令是要被调整?这些指令应该怎么调整?事实上ELF文件中有一个叫做重定位表Relocation Table的结构,他在ELF文件中往往是一个或多个段。
重定位表
对于每一个要被重定位的ELF段都有一个对应的重定位表,比如代码段“.text”如有要被重定位的地方,就会有一个相应的叫“.ret.text”的段保存了代码段的重定位表;同样的,若数据段“.data”如有要被重定位的地方,就会有一个相应的叫“.ret.data”的段保存了数据段的重定位表,可以用如下命令查看:
ubuntu@VM-0-12-ubuntu:/home/chenjinan/sometest/elf$ objdump -r a.o
a.o: file format elf64-x86-64
RELOCATION RECORDS FOR [.text]:
OFFSET TYPE VALUE
0000000000000025 R_X86_64_PC32 shared-0x0000000000000004
0000000000000032 R_X86_64_PLT32 swap-0x0000000000000004
000000000000004b R_X86_64_PLT32 __stack_chk_fail-0x0000000000000004
RELOCATION RECORDS FOR [.eh_frame]:
OFFSET TYPE VALUE
0000000000000020 R_X86_64_PC32 .text每个要被重定位的地方叫一个重定位入口,我们可以看到a.o有三个重定位入口。重定位入口的便宜表示该入口在要被重定位的段中的位置
重定位表的结构很简单,它是一个Elf32_Rel结构的数组,每个元素对应一个重定位入口:
typedef struct elf32_rel {
Elf32_Addr r_offset;
Elf32_Word r_info;
} Elf32_Rel;
- 符号解析
之所以要链接是因为我们目标文件中用到的符号被定义在其他目标文件,所以要将他们链接起来。比如我们直接用ld来链接a.o而不将b.o作为输入,链接器就会发现shared和swap两个符号没有被定义:
ubuntu@VM-0-12-ubuntu:/home/chenjinan/sometest/elf$ ld a.o
ld: warning: cannot find entry symbol _start; defaulting to 00000000004000b0
a.o: In function `main':
a.c:(.text+0x25): undefined reference to `shared'
a.c:(.text+0x32): undefined reference to `swap'
a.c:(.text+0x4b): undefined reference to `__stack_chk_fail'链接时符号未定义是最常碰到的问题之一,常见原因是链接时缺少了某个库,或者输入目标文件路径不正确或符号的声明与定义不一样。
其实重定位的过程也伴随着符号的解析过程,每个目标文件都可能定义一些符号,也可能引用到定义在其他目标文件的符号。当链接器需要对某个符号的引用进行重定位时,它就要确定这个符号的目标地址,这时候链接器就会去查找由所有输入目标文件的符号表组成的全局符号表,找到相应的符号后进行重定位。
比如我们查看a.o的符号表:
ubuntu@VM-0-12-ubuntu:/home/chenjinan/sometest/elf$ readelf -s a.o
Symbol table '.symtab' contains 13 entries:
Num: Value Size Type Bind Vis Ndx Name
0: 0000000000000000 0 NOTYPE LOCAL DEFAULT UND
1: 0000000000000000 0 FILE LOCAL DEFAULT ABS a.c
2: 0000000000000000 0 SECTION LOCAL DEFAULT 1
3: 0000000000000000 0 SECTION LOCAL DEFAULT 3
4: 0000000000000000 0 SECTION LOCAL DEFAULT 4
5: 0000000000000000 0 SECTION LOCAL DEFAULT 6
6: 0000000000000000 0 SECTION LOCAL DEFAULT 7
7: 0000000000000000 0 SECTION LOCAL DEFAULT 5
8: 0000000000000000 81 FUNC GLOBAL DEFAULT 1 main
9: 0000000000000000 0 NOTYPE GLOBAL DEFAULT UND shared
10: 0000000000000000 0 NOTYPE GLOBAL DEFAULT UND _GLOBAL_OFFSET_TABLE_
11: 0000000000000000 0 NOTYPE GLOBAL DEFAULT UND swap
12: 0000000000000000 0 NOTYPE GLOBAL DEFAULT UND __stack_chk_failGLOBAL类型的符号,除了main函数是定义在代码段之外,其他两个shared和swap都是UND,即undefined未定义类型,这种未定义的符号都是因为该目标文件中有关于它们的重定位项。所以在链接器扫描完所有的输入目标文件之后,所有这些未定义的符号都应该能够在全局符号表中找到,否则链接器就报符号未定义错误。
- 指令修正方式
绝对寻址修正和相对寻址修正的区别就是绝对寻址修正后的地址为该符号的实际地址;相对寻址修正后的地址为符号距离被修正位置的地址差。
详见p110
c++的相关问题-静态链接时
c++的一些语言特性使之必须由编译器和链接器共同支持才能完成工作。最主要的有两个方面,一个是c++的重复代码消除,还有一个就是全局构造与析构。
- 重复代码消除
c++编译器在很多时候会产生重复的代码,比如模板、外部内联函数和虚函数表都有可能在不同的编译单元里生成相同的代码。最简单的情况就拿模板来说,模板从本质上来讲很像宏,当模板在一个编译单元里被实例化时,它并不知道自己是否在别的编译单元也被实例化了。所以当一个模板在多个编译单元同时实例化成相同的类型的时候,必然会生成重复的代码。当然最简单的方案就是不管这些,将这些重复的代码都保留下来,不过这样做的主要问题有以下几个方面:
1.空间浪费。可以想象一个有几百个编译单元的工程同时实例化了许多个模板,最后链接的时候必须将这些重复的代码消除掉,否则最终程序的大小肯定会膨胀得很厉害。
2.地址较易出错。有可能两个指向同一个函数的指针会不相等。
3.指令运行效率较低。因为现代CPU都会对指令和数据进行缓存,如果同样一份指令有多份副本,那么指令Cache的命中率就会降低。
一个比较有效的做法就是将每个模板的实例代码都单独地存放在一个段里,每个段只包含一个模板实例。比如有个模板函数是add<T>(),某个编译单元以int类型和float类型实例化了该模板函数,那么该编译单元的目标文件中就包含了这两个该模板实例的段如称为.temp.add<int>和.temp.add<float>。这样,当别的编译单元也以int或float类型实例化该模板函数后,也会生成同样的名字,这样链接器在最终链接的时候可以区分这些相同的模板实例段,然后将它们合并入最后的代码段。
GCC把这种类似的需要在最终链接时合并的段叫“Link Once”,它的做法是将这种类型的段命名为“.gnu.linkonce.name”,其中.name是该模板函数实例的修饰后名称。
对于外部内联函数和虚函数表的做法也类似。比如对于一个有虚函数的类来说,有一个与之相对应的虚函数表,编译器会会在用到该类的多个编译单元生成虚函数表,造成代码重复;外部内联函数、默认构造函数、默认拷贝构造函数和赋值操作符也有类似的问题。它们的解决方式基本跟模板的重复代码消除类似。
这种方法虽然能够基本上解决代码重复问题,但仍存在一些问题,比如相同名称的段可能拥有不同的内容,这可能由于不同的编译单元使用了不同的编译器版本或者编译优化选项,导致同一个函数编译出来的实际代码有所不同。那么这种情况下链接器可能会做出一个选择,就是随意选择其中任一个副本作为链接的输入,然后同时提供一个警告信息。
函数级别链接
由于现在的都程序和库通常来说都非常胖法,一个目标文件可能包含成百上千个函数或者变量,当我们需要用到某个目标文件中的任意一个函数和变量时,必须要把它整个链接进来。这样的后果是输出文件会变得很大,因为很多没用到的变量和函数都一起塞到了输出文件中。
VISUAL C++编译器提供了一个编译选项叫函数级别链接(functional-level linking,/Gy),这个选项的作用就是让所有的函数都像前面的模板函数一样,单独保存到一个段里面,当链接器需要用到某个函数时,它就将它合并到输出文件中,对于那些没有用的函数则将它们抛弃。这个优化选项会减慢编译和链接过程,因为链接器需要计算各个函数之间的依赖关系,并且所有的函数都保存到独立的段中,目标函数的段的数量大大增加,重定位的过程也会因为段的数目增加而变得复杂。
GCC编译器也提供了类似的机制,它有两个选择分别是“-ffunction-section”和“-fdata-sections”,这两个选项的作用就是将每个函数或变量分别保持到独立的段中。
- 全局构造与析构
Linux系统下一般程序的入口是“_start”,这个函数是Linux系统库(Glibc)的一部分。当我们的程序与Glibc库链接在一起形成最终可执行文件以后,这个函数就是程序的初始化部分的入口,初始化部分完成一系列初始化过程之后,会调用main函数来执行程序的主体。在main函数执行完成以后,返回到初始化部分,它进行一些清理工作,然后结束进程。对于有些场合,程序的一些特定的操作必须在main函数之前被执行,还有一些操作必须在main函数之后被执行,其中很有代表性的就是C++的全局对象的构造和析构函数,因此ELF文件还定义了两种特殊的段。
1. .init 该段保存的是可执行指令,它构成了进程的初始化代码。因此,当一个程序开始运行时,在main函数被调用之前,Glibc的初始化部分安排执行这个段中的代码。
2. .fint 该段保存着进程终止代码指令。因此,当一个程序的main函数正常退出时,Glibc会安排执行这个段中的代码
这两个段的存在有着特别的目的,如果一个函数放到.init段或.fint段,则在main函数执行前或者返回后该函数就会被执行。利用这两个特性,C++的全局构造和析构函数就由此实现,后文中会详细介绍。
可执行文件的装载与进程
- 1.进程的建立
事实上,从操作系统的角度来看,一个进程最关键的特征是它拥有独立的虚拟地址空间,这使得它有别于其他进程。很多时候一个程序被执行的同时都伴随着一个新的进程的创建,那么我们就来看看这种最通常的情形:创建一个进程,然后装载相应的可执行文件并且执行。在有虚拟存储的情况下,上述过程最开始只需要做三件事情:
- 创建一个独立的虚拟地址空间
一个虚拟空间由一组页映射函数将虚拟空间的各个页映射至相应的物理空间,那么创建一个虚拟空间实际上是创建映射函数所需要的数据结构。在i386的linux下,此操作实际上只是分配一个页目录就可以了,甚至不设置页映射关系,这些映射关系等到后面程序发生页错误的时候再进行设置。
- 读取可执行文件头,并且建立虚拟空间与可执行文件的映射关系
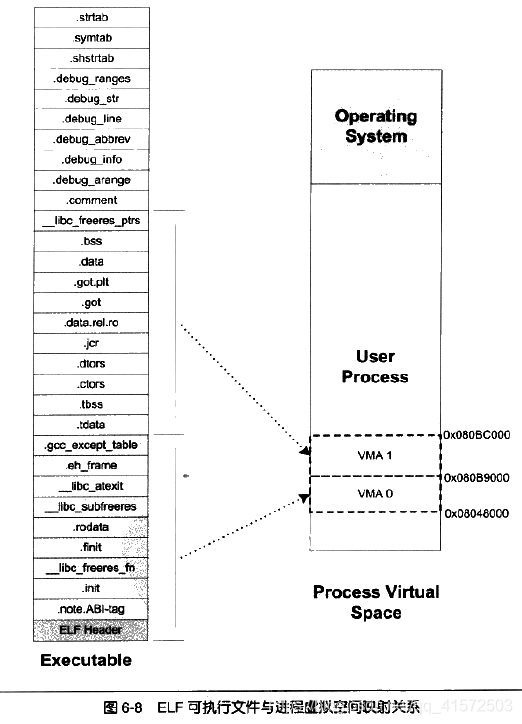
上一步的页映射关系函数是虚拟空间到物理内存的映射关系,这一步所做的是虚拟空间与可执行文件的映射关系。我们知道,当程序执行发生页错误时,操作系统将从物理内存中分配一个物理页,然后将该“缺页”从磁盘中读取到内存中,再设置缺页的虚拟页和内存页的映射关系,这样程序才得以正常运行。但是很明显的一点是,当操作系统捕获到缺页错误时,它应该知道程序当前所需要的页在可执行文件中的哪一个位置,这就是虚拟空间与可执行文件之间的映射关系。从某种角度来看,这一步是整个装载过程中最重要的一步,也是传统意义上“装载”的过程。
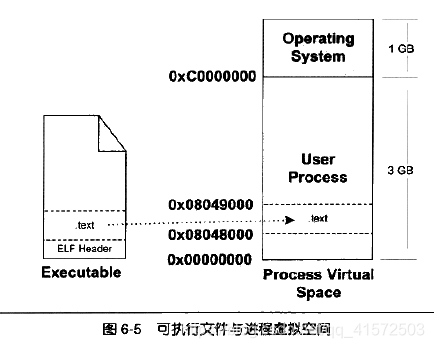
这种映射关系只是保存在操作系统内部的一个数据结构,linux将进程虚拟空间中的一个段叫做虚拟内存区域VMA。比如上图,操作系统创建进程后,会在进程相应的数据结构中设置有一个.text段的VMA:他在虚拟空间的地址为0x08048000~0x08049000(这是因为操作系统的页大小为4096bytes,则对齐粒度为0x1000),它对应ELF文件中的偏移为0的.text,它的属性为只读(一般代码段都是只读的)
- 将CPU的指令寄存器设置成可执行文件的入口地址,启动运行
涉及到内核堆栈和用户堆栈的切换、CPU运行权限的切换。不过从进程的角度来看这一步可以简单地认为操作系统执行了一条跳转指令,直接跳转到可执行文件的入口地址,即ELF文件头中保存的入口地址。
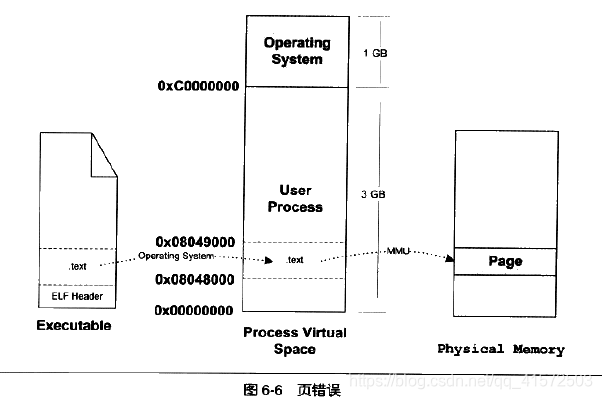
- 2.页错误
上述步骤执行完成后,其实可执行文件的真正指令和数据都没有被转入到内存中。操作系统只是通过可执行文件头部的信息建立起可执行文件和进程虚存之间的映射关系而已。假设在上面例子中,程序的入口地址为0x08048000,即刚好是.text段的起始地址。当CPU开始执行这个地址的指令时,发现页面0x08048000~0x08049000是个空页面,于是它就认为这是一个页错误。CPU将控制权交给操作系统,操作系统有专门的页错误处理例程来处理这种情况。这时候我们前面提到的第二步建立的数据结构(task_struct中)起到了很关键的作用,操作系统将查询这个数据结构,然后找到空页面所在的VMA,计算出相应的页面在可执行文件中的偏移,然后在物理内存中分配一个物理页面,将进程中该虚拟页与分配的物理页之间建立映射关系,然后把控制权再还给进程,进程从刚才的页错误的位置重新开始执行。
- 3.进程虚存空间分布
从上面的例子我们可以看出,在映射时是以页作为单位的,因此在ELF文件中段的数量很多的情况下,由于划分粒度是页即4096bytes,就会产生很多的内部碎片。为了解决这个问题,ELF可执行文件引入了一个概念叫做“segment”,一个“segment”包含一个或多个属性类似的“section”,例如将.text 和.init段合并在一起看做一个“segment”,那么在装载的时候就可以将它们看做一个整体一起映射,也就是说映射以后再进程的虚存空间中只有一个相对应的VMA,而不是两个。
如图:
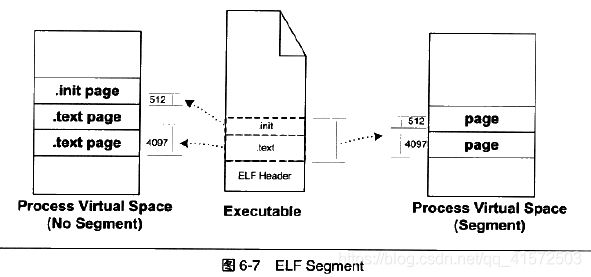
例子:有这样一个程序
#include <stdlib.h>
int main()
{
while(1){
sleep(1000);
}
return 0;
}编译后: $ readelf -S sectionmapping.elf
$ readelf -S sectionmapping.elf
There are 33 section headers, starting at offset 0xcdbd0:
Section Headers:
[Nr] Name Type Address Offset
Size EntSize Flags Link Info Align
[ 0] NULL 0000000000000000 00000000
0000000000000000 0000000000000000 0 0 0
[ 1] .note.ABI-tag NOTE 0000000000400190 00000190
0000000000000020 0000000000000000 A 0 0 4
[ 2] .note.gnu.build-i NOTE 00000000004001b0 000001b0
0000000000000024 0000000000000000 A 0 0 4
readelf: Warning: [ 3]: Link field (0) should index a symtab section.
[ 3] .rela.plt RELA 00000000004001d8 000001d8
0000000000000228 0000000000000018 AI 0 20 8
[ 4] .init PROGBITS 0000000000400400 00000400
0000000000000017 0000000000000000 AX 0 0 4
[ 5] .plt PROGBITS 0000000000400418 00000418
00000000000000b8 0000000000000000 AX 0 0 8
[ 6] .text PROGBITS 00000000004004d0 000004d0
000000000008f590 0000000000000000 AX 0 0 16
[ 7] __libc_freeres_fn PROGBITS 000000000048fa60 0008fa60
0000000000001523 0000000000000000 AX 0 0 16
[ 8] __libc_thread_fre PROGBITS 0000000000490f90 00090f90
000000000000108f 0000000000000000 AX 0 0 16
[ 9] .fini PROGBITS 0000000000492020 00092020
0000000000000009 0000000000000000 AX 0 0 4
[10] .rodata PROGBITS 0000000000492040 00092040
000000000001924c 0000000000000000 A 0 0 32
[11] .stapsdt.base PROGBITS 00000000004ab28c 000ab28c
0000000000000001 0000000000000000 A 0 0 1
[12] .eh_frame PROGBITS 00000000004ab290 000ab290
000000000000a530 0000000000000000 A 0 0 8
[13] .gcc_except_table PROGBITS 00000000004b57c0 000b57c0
000000000000008e 0000000000000000 A 0 0 1
[14] .tdata PROGBITS 00000000006b6120 000b6120
0000000000000020 0000000000000000 WAT 0 0 8
[15] .tbss NOBITS 00000000006b6140 000b6140
0000000000000040 0000000000000000 WAT 0 0 8
[16] .init_array INIT_ARRAY 00000000006b6140 000b6140
0000000000000010 0000000000000008 WA 0 0 8
[17] .fini_array FINI_ARRAY 00000000006b6150 000b6150
0000000000000010 0000000000000008 WA 0 0 8
[18] .data.rel.ro PROGBITS 00000000006b6160 000b6160
0000000000002d94 0000000000000000 WA 0 0 32
[19] .got PROGBITS 00000000006b8ef8 000b8ef8
00000000000000f8 0000000000000000 WA 0 0 8
[20] .got.plt PROGBITS 00000000006b9000 000b9000
00000000000000d0 0000000000000008 WA 0 0 8
[21] .data PROGBITS 00000000006b90e0 000b90e0
0000000000001af0 0000000000000000 WA 0 0 32
[22] __libc_subfreeres PROGBITS 00000000006babd0 000babd0
0000000000000048 0000000000000000 WA 0 0 8
[23] __libc_IO_vtables PROGBITS 00000000006bac20 000bac20
00000000000006a8 0000000000000000 WA 0 0 32
[24] __libc_atexit PROGBITS 00000000006bb2c8 000bb2c8
0000000000000008 0000000000000000 WA 0 0 8
[25] __libc_thread_sub PROGBITS 00000000006bb2d0 000bb2d0
0000000000000008 0000000000000000 WA 0 0 8
[26] .bss NOBITS 00000000006bb2e0 000bb2d8
00000000000016f8 0000000000000000 WA 0 0 32
[27] __libc_freeres_pt NOBITS 00000000006bc9d8 000bb2d8
0000000000000028 0000000000000000 WA 0 0 8
[28] .comment PROGBITS 0000000000000000 000bb2d8
000000000000002b 0000000000000001 MS 0 0 1
[29] .note.stapsdt NOTE 0000000000000000 000bb304
00000000000014cc 0000000000000000 0 0 4
[30] .symtab SYMTAB 0000000000000000 000bc7d0
000000000000a998 0000000000000018 31 678 8
[31] .strtab STRTAB 0000000000000000 000c7168
00000000000068ed 0000000000000000 0 0 1
[32] .shstrtab STRTAB 0000000000000000 000cda55
0000000000000176 0000000000000000 0 0 1
Key to Flags:
W (write), A (alloc), X (execute), M (merge), S (strings), I (info),
L (link order), O (extra OS processing required), G (group), T (TLS),
C (compressed), x (unknown), o (OS specific), E (exclude),
l (large), p (processor specific)可以看到共有33个段(section)
描述section属性的结构叫做段表,而描述segment的结构叫做程序头program header(readelf -l 命令可查看),他描述了ELF文件该如何被操作系统映射到进程的虚拟空间:
$ readelf -l sectionmapping.elf
Elf file type is EXEC (Executable file)
Entry point 0x400a30
There are 6 program headers, starting at offset 64
Program Headers:
Type Offset VirtAddr PhysAddr
FileSiz MemSiz Flags Align
LOAD 0x0000000000000000 0x0000000000400000 0x0000000000400000
0x00000000000b584e 0x00000000000b584e R E 0x200000
LOAD 0x00000000000b6120 0x00000000006b6120 0x00000000006b6120
0x00000000000051b8 0x00000000000068e0 RW 0x200000
NOTE 0x0000000000000190 0x0000000000400190 0x0000000000400190
0x0000000000000044 0x0000000000000044 R 0x4
TLS 0x00000000000b6120 0x00000000006b6120 0x00000000006b6120
0x0000000000000020 0x0000000000000060 R 0x8
GNU_STACK 0x0000000000000000 0x0000000000000000 0x0000000000000000
0x0000000000000000 0x0000000000000000 RW 0x10
GNU_RELRO 0x00000000000b6120 0x00000000006b6120 0x00000000006b6120
0x0000000000002ee0 0x0000000000002ee0 R 0x1
Section to Segment mapping:
Segment Sections...
00 .note.ABI-tag .note.gnu.build-id .rela.plt .init .plt .text __libc_freeres_fn __libc_thread_freeres_fn .fini .rodata .stapsdt.base .eh_frame .gcc_except_table
01 .tdata .init_array .fini_array .data.rel.ro .got .got.plt .data __libc_subfreeres __libc_IO_vtables __libc_atexit __libc_thread_subfreeres .bss __libc_freeres_ptrs
02 .note.ABI-tag .note.gnu.build-id
03 .tdata .tbss
04
05 .tdata .init_array .fini_array .data.rel.ro .got 我们可以看到,这个可执行文件共有5个segment。从装载的角度看,我们目前只关心两个LOAD类型的segment,因为只有它是需要被映射的,其他类型的都是在装载时起辅助作用的。
见图:
前文提到的程序头:
typedef struct {
Elf32_Word p_type; /* Segment type*/
Elf32_Off p_offset; /* Segment file offset */
Elf32_Addr p_vaddr; /* Segment virtual address */
Elf32_Addr p_paddr; /* Segment physical address */
Elf32_Word p_filesz; /* Segment size in file */
Elf32_Word p_memsz; /* Segment size in memery */
Elf32_Word p_flags; /* Segment flags */
Elf32_Word p_align; /* Segment alignment */
} Elf32_Phdr;结构体各个成员的含义:

- 堆和栈
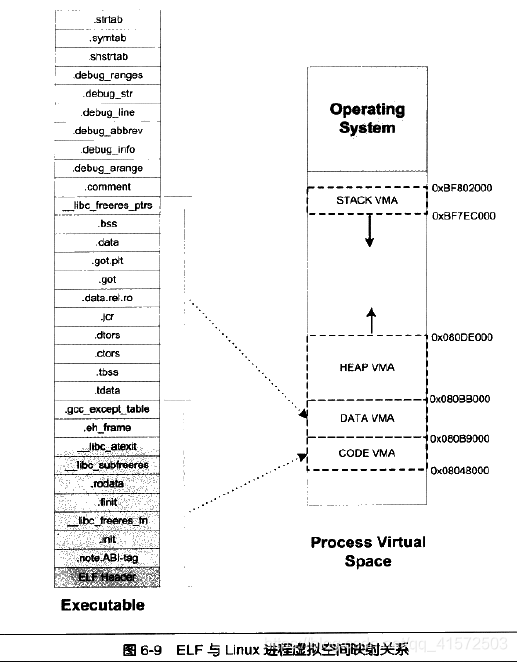
查看一个运行中程序的内存分布情况 cat /proc/pid/maps 即可
$ ./sectionmapping.elf &
[1] 11607
ubuntu@VM-0-12-ubuntu:/home/chenjinan/sometest/elf$ cat /proc/11607/maps
00400000-004b6000 r-xp 00000000 fc:01 266869 /home/chenjinan/sometest/elf/sectionmapping.elf
006b6000-006bc000 rw-p 000b6000 fc:01 266869 /home/chenjinan/sometest/elf/sectionmapping.elf
006bc000-006bd000 rw-p 00000000 00:00 0
00c34000-00c57000 rw-p 00000000 00:00 0 [heap]
7fff0e1e8000-7fff0e209000 rw-p 00000000 00:00 0 [stack]
7fff0e34f000-7fff0e352000 r--p 00000000 00:00 0 [vvar]
7fff0e352000-7fff0e354000 r-xp 00000000 00:00 0 [vdso]
ffffffffff600000-ffffffffff601000 r-xp 00000000 00:00 0 [vsyscall]

图片如下:
- 4.进程栈初始化
我们知道进程刚开始启动的时候,需要知道一些进程运行的环境,最基本的就是系统环境变量和进程运行参数。很常见的一种做法是操作系统在进程启动前将这些信息提前保存到进程的虚拟空间的栈中(也就是VMA中的stack VMA)。让我们来看看linux的进程初始化后栈的结构,我们假设系统中有两个环境变量:
HOME=/home/user
PATH=/usr/bin
比如我们运行该程序的命令行是:
& proc 123
并且我们假设堆栈段底部地址为0xBF802000,那么进程初始化后的堆栈就如图所示:

栈顶寄存器esp指向的位置是初始化以后堆栈的顶部,最前面的4个字节表示命令行参数的数量,此例子里面是两个,即proc和123,紧接着就是分布指向这两个参数字符串的指针;后面跟了一个0;接着是两个指向环境变量字符串的指针,它们分别指向字符串“HOME=/home/user”, “PATH=/usr/bin”;后面紧跟一个0表示结束。
进程启动以后,程序的库部分会把堆栈里的初始化信息中的参数信息传递给main()函数,也就是我们熟知的main函数的两个argc和argv参数,这两个参数分别对应这里的命令行参数数量和命令行参数字符串指针数组。
- 与静态库链接
有如下两个模块:
1 int addcnt = 0;
2
3 void addvec(int* x,int* y,int* z,int n){
4 int i;
5 addcnt++;
6
7 for(i=0;i<n;i++){
8 z[i] = x[i] + y[i];
9 }
10 }
1 int multcnt = 0;
2
3 void multvec(int* x,int* y,int* z,int n){
4 int i;
5 multcnt++;
6
7 for(i=0;i<n;i++){
8 z[i] = x[i] * y[i];
9 }
10 }
创建两个静态库,
要创建这些函数的一个静态库,我们将使用AR工具,如下:
ubuntu@VM-0-12-ubuntu:/home/chenjinan/deepincomputer/static_lib$ gcc -c addvec.c multvec.c
ubuntu@VM-0-12-ubuntu:/home/chenjinan/deepincomputer/static_lib$ ar rcs libvector.a addvec.o multvec.o为了使用这个库,我们可以编写一个应用:
它调用了addvec库,包含(头)文件vector.h,其中定义了这两个函数的原型。
1 void addvec(int* x,int* y,int* z,int n){}
2
3 void multvec(int* x,int* y,int* z,int n){} 1 #include<stdio.h>
2 #include "vector.h"
3
4 int x[2] = {1,2};
5 int y[2] = {3,4};
6 int z[2];
7
8 int main(){
9 addvec(x,y,z,2);
10 printf("z = [%d %d]\n" ,z[0],z[1]);
11 return 0;
12 }为创建这个可执行文件,我们要编译和链接输入文件main.o和libvector.a
ubuntu@VM-0-12-ubuntu:/home/chenjinan/deepincomputer/static_lib$ gcc -c main2.c
ubuntu@VM-0-12-ubuntu:/home/chenjinan/deepincomputer/static_lib$ gcc -static -o proc main2.o ./libvector.a 或者等价地使用
ubuntu@VM-0-12-ubuntu:/home/chenjinan/deepincomputer/static_lib$ gcc -c main2.c
ubuntu@VM-0-12-ubuntu:/home/chenjinan/deepincomputer/static_lib$ gcc -static -o proc main2.o -L. lvector下图概括了链接器的行为。-static 参数告诉编译器驱动程序,链接器应该构建一个完全链接的可执行目标文件,它可以加载到内存并运行,在加载时无须更进一步的链接。-lvector 参数是libvector.a 的缩写,-L.参数告诉链接器在当前目录下査找libvector.a。
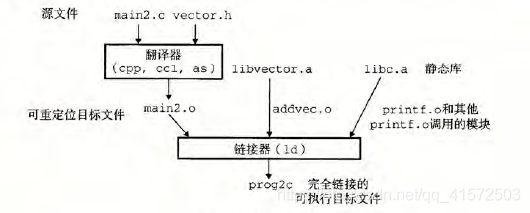
当链接器运行时,它判定main2.o引用了addvec.o定义的addvec 符号,所以复制addvec.o 到可执行文件。因为程序不引用任何由multvec.o 定义的符号,所以链接器就不会复制这个模块到可执行文件。链接器还会复制libc.a 中的printf.o 模块,以及许多C 运行时系统中的其他模块。
- 补充说明
在进行静态链接时一定要注意命令行中库文件放在后面,被依赖的文件也要放在后面,这里的a依赖于b是指b中定义了a中所引用的一个符号。如果文件之间依赖关系复杂,可以将 多个依赖关系复杂的文件放在一个静态库中,或者在命令行中根据依赖关系多次指明被依赖文件也是可以的,比如说x.o依赖于y.a,同时y.a依赖于z.a,并且z.a又依赖于y.a,那么此时这三个文件在命令行中的链接顺序就可以是x.o y.a z.a y.a。
之所以这样,是因为在符号解析过程中,链接器维护一个可重定位目标文件的集合E,这个集合中的文件最终合并为可执行文件;一个未解析符号集合U,该集合中存放着被引用但是未被定义的符号;以及一个一个已经被定义的符号D,在初始状态下,三个集合均为空。所谓符号,就像变量名、函数名都是符号。
然后链接器从左到右按照各个可重定位目标文件(.o)和静态库文件(.a)在命令行上出现的顺序来对每个文件进行扫描,如果输入文件为可重定位目标文件,那么链接器就会将该文件放到集合E中,并且将该输入文件中的符号定义和引用情况反应在集合U和集合D中;
如果输入文件为静态库文件,那么链接器就会扫描该静态库文件中的各成员文件(.o),将成员文件中的符号与U中已被引用但是未定义的符号进行匹配,如果该静态库中某个成员文件定义了U中某个已被引用但未被定义的符号,那么链接器就将该成员文件放到集合E中,然后在U中删除该符号,D中添加该符号,再继续扫描下一个成员文件,这样一直反复进行扫描下去,直到U和D中集合都不再变化,就将多余的成员文件抛弃,然后就继续扫描下一个输入文件了。
若文件a依赖于b,那么就说明a中存在某一符号的引用,b中存在该符号的定义。如果先扫描到符号的定义,那么就会将该符号放到D中,而由于每次扫描都是与U中的符号进行匹配,因此即使后面再扫描到该符号的引用,也会直接将该符号又放入U中,由于符号的定义已经在D中了,因此到最后该符号依然存在于U中,U中非空,说明链接中存在被引用但是未定义的符号,从而该符号被认为是未定义的符号而报错。
也可参见这篇博文:https://blog.csdn.net/qq_28114615/article/details/87274134
注:
Linux ar命令用于建立或修改备存文件,或是从备存文件中抽取文件。
ar可让您集合许多文件,成为单一的备存文件。在备存文件中,所有成员文件皆保有原来的属性与权限。
ar用来管理一种文档。这种文档中可以包含多个其他任意类别的文件。这些被包含的文件叫做这个文档的成员。ar用来向这种文档中添加、删除、解出成员。成员的原有属性(权限、属主、日期等)不会丢失。
实际上通常只有在开发中的目标连接库是这种格式的,所以尽管不是,我们基本可以认为ar是用来操作这种目标链接库(.a文件)的。
语法
ar[-dmpqrtx][cfosSuvV][a<成员文件>][b<成员文件>][i<成员文件>][备存文件][成员文件]参数:
必要参数:
- -d 删除备存文件中的成员文件。
- -m 变更成员文件在备存文件中的次序。
- -p 显示备存文件中的成员文件内容。
- -q 将文件附加在备存文件末端。
- -r 将文件插入备存文件中。
- -t 显示备存文件中所包含的文件。
- -x 自备存文件中取出成员文件。
选项参数:
- a<成员文件> 将文件插入备存文件中指定的成员文件之后。
- b<成员文件> 将文件插入备存文件中指定的成员文件之前。
- c 建立备存文件。
- f 为避免过长的文件名不兼容于其他系统的ar指令指令,因此可利用此参数,截掉要放入备存文件中过长的成员文件名称。
- i<成员文件> 将文件插入备存文件中指定的成员文件之前。
- o 保留备存文件中文件的日期。
- s 若备存文件中包含了对象模式,可利用此参数建立备存文件的符号表。
- S 不产生符号表。
- u 只将日期较新文件插入备存文件中。
- v 程序执行时显示详细的信息。
- V 显示版本信息
动态链接
静态链接的方式对于计算机内存和磁盘的空间浪费非常严重。特别是多进程操作系统的情况下,。想象一下每个程序内部除了都保留着printf()函数,scanf()函数、strlen()等这样的公用库函数,还有数量相当可观的其他库函数及它们所需要的辅助数据结构。在现在的linux系统中,一个普通程序会用到的c语言静态库至少在1MB以上,那么,如果机器中运行着100个这样的程序,就要浪费近100MB的内存;如果磁盘中有2000个这样的程序,就要浪费近2GB的磁盘空间,很多linux机器中,/usr/bin下就有数千个可执行文件。
例子:program1和program2分别包含program1.o和program2.o两个模块,并且他们还共用lib.o这个模块:
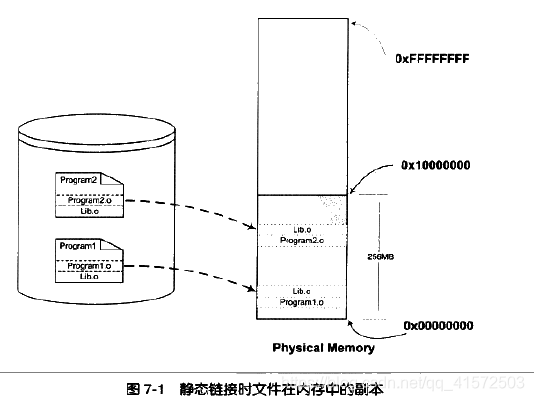
那么在静态链接的情况下,可执行文件program1,program2运行时,lib.o在磁盘中和内存中都有两份副本。当系统中存在大量的类似于lib.o的被多个程序共享的目标文件时,其中很大一部分空间就被浪费了。
另一个问题是静态链接对程序的更新、部署和发布也会带来很多麻烦。比如lib.o是由一个第三方厂商提供的,当该厂商更新了lib.o的时候(比如修正了里面包含的一个bug),那么program1的厂商就需要拿到最新版的lib.o,然后将其与program1.o链接后,将新的program1整个发布给用户。这样做的缺点很明显,即一旦程序中有任何模块更新,整个程序就要重新链接、发布给用户。
动态链接
要解决空间浪费和更新困难这两个问题最简单的办法就是把程序的模块相互分隔开来,形成独立的文件,而不再将它们静态地链接在一起。简单地将,就是不对那些组成程序的目标文件进行链接,等到程序要运行时才进行链接,也就是说,把链接这个过程推迟到了运行时再进行,这就是动态链接的基本思想。
当一个程序产品的规模很大的时候,往往会分割成多个子系统及多个模块,每个模块都由独立的小组开发,甚至会使用不同的编程语言。动态链接的方式使得开发过程中各个模块更加独立,耦合度更小,便于不同的开发者和开发组织之间独立进行开发和测试。
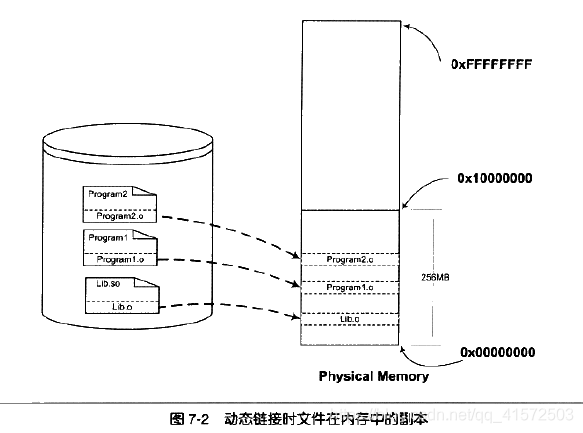
linux系统中,ELF动态链接文件被称为动态共享对象,简称共享对象,他们一般是以.so为扩展名的一些文件,而在windows系统中,动态链接文件被称为动态链接库,就是常见的dll文件
linux中,常用的C语言库的运行库glibc,它的动态链接形式的版本保存在/lib目录下,文件名叫做libc.so。整个系统只保留一份。所有c语言编写的、动态链接的程序都可以在运行时使用它,当程序被装载的时候,系统的动态链接器会将程序所需要的所有动态链接库装载到进程的地址空间,并且将程序中所有未决议的符号绑定到相应的动态链接库中,并进行重定位工作。
地址无关代码
分析见:https://blog.csdn.net/wuhui_gdnt/article/details/51094732
gcc -fPIC -shared -o Lib.so Lib.c
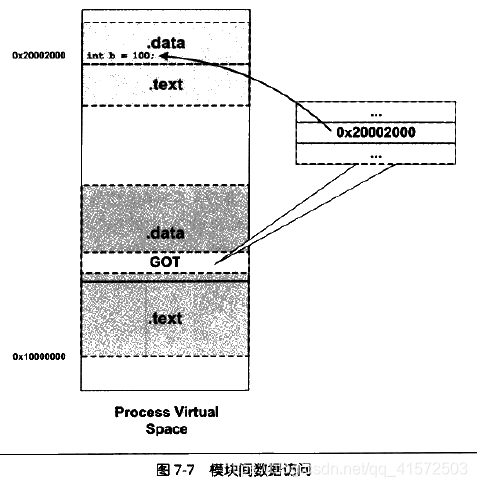
在编译共享对象时使用“-fPIC”参数,表示产生地址无关的代码段。如果代码不是地址无关的,它就不能被多个进程之间共享,于是也就失去了节省内存的优点,但是装载时重定位的共享对象的运行速度要比使用地址无关代码的共享对象快,因为它省去了地址无关代码中每次访问全局数据和函数时需要做一次计算当前地址以及间接寻址的过程。
这里有一个概念:global offset table 即GOT ,是ELF在数据段里面建立一个指向其他模块的全局变量、函数的指针数组,称为全局偏移表:
动态链接的步骤与实现
这篇博客摘录得很好 https://www.cnblogs.com/linhaostudy/p/10544917.html
库与运行库
带着问题看书:
- malloc是如何分配出内存的?
- 为什么一个编译好的简单的helloworld程序也需要占据好几kb的空间?
- 为什么程序一启动就有堆、IO或异常系统可用?
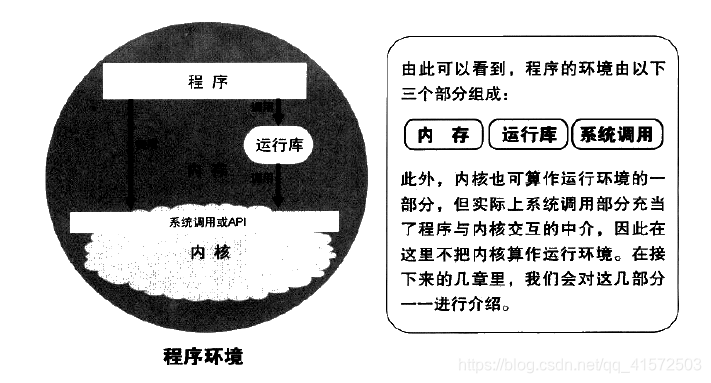
典型32位机器下的程序内存分布:
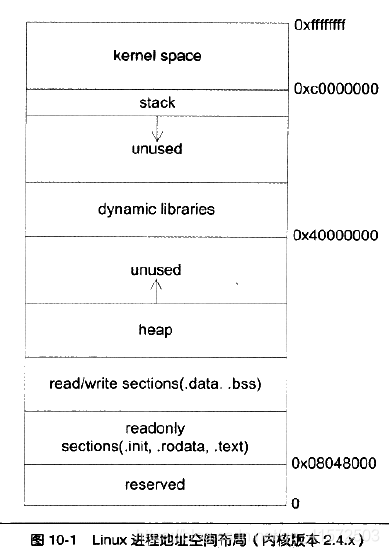
- 保留区: 并不是一个单一的内存区域,而是对内存中受到不保护而禁止访问的内存区域的总称,例如,大多数操作系统里,极小的地址通常都是不允许访问的,如NULL。通常c语言将无效指针赋值为0也是出于这个考虑,因为0地址上正常情况下不可能有有效的可访问数据。
栈
栈保存了一个函数调用所需要的维护信息,这常常被称为堆栈帧或活动记录。堆栈帧一般包括如下几方面内容:
函数的返回地址和参数
临时变量:包括函数的非静态局部变量以及编译器自动生成的其他临时变量
保存的上下文:包括在函数调用前后需要保持不变的寄存器
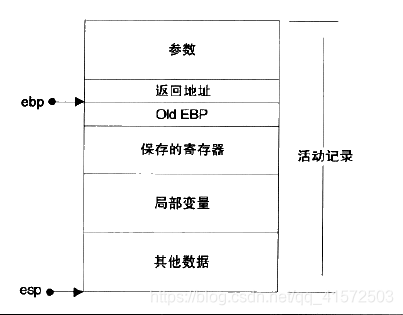
在i386中,一个函数的活动记录用ebp和esp这两个寄存器划定范围,esp寄存器始终指向栈的顶部,同时也就指向了当前函数的活动记录的顶部,而相对的ebp寄存器指向了函数活动记录的一个固定位置,ebp寄存器又被称为帧指针。
在参数之后的数据(包括参数)即是当前函数的活动记录,ebp固定在图中所示的位置,不随这个函数的的执行而发生变化。相反的,esp始终指向栈顶,因此随着函数的执行,esp会不断变化。固定不变的ebp可以用来定位函数活动记录中的各个数据。在ebp之前首先是这个函数的返回地址,他的地址是ebp-4再往前是压入栈中的参数,他们的地址分别是ebp-8、ebp-12等,视参数数量和大小而定。ebp所指向的数据是调用该函数前ebp的值,这样在函数返回的时候,ebp可以通过读取这个值恢复到调用前的值。函数调用过程:
1.把所有或一部分参数压入栈中,如果有其他参数没有入栈,那么使用某些特定的寄存器传递
2.把当前指令的下一条指令的地址压入栈中
3.跳转到函数体执行
其中第2步和第3步由指令call一起执行。跳转到函数体之后开始执行函数,而i386函数体的标准开头一般是这样的:
1.push ebp:把ebp压入栈中(称为old ebp)
2.mov ebp,esp:ebp=esp(这时ebp指向栈顶,而此时栈顶就是old ebp)
【可选】sub exp,XXX:在栈上分配XX字节的临时空间
【可选】push XXX:如有必要,保存名为XXX寄存器(可重复多个)
把ebp压入栈中,是为了在函数返回时便于恢复以前的ebp值。之所以可能要保存一些寄存器,在于编译器可能要求某些寄存器在调用前后保持不变,那么函数就可以在调用开始时将这些寄存器的值压入栈中,结束后再取出。不难想象,在函数返回时所进行的标准结尾与开头正好相反:
【可选】pop XXX:如有必要,恢复保存过的寄存器
1.mov esp,ebp:恢复esp同时回收局部变量空间
2.pop ebp:从栈中恢复保存的ebp值。
3.ret:从栈中取得返回地址,并跳转到该位置
例子:
#include<stdio.h>
int func()
{
return 123;
}
int main()
{
int a = func();
printf("%d",a);
return 0;
}gcc -c func_call.c
//然后反汇编
objdump -s -d func_call.o
0000000000000000 <func>:
0: 55 push %rbp
1: 48 89 e5 mov %rsp,%rbp
4: b8 7b 00 00 00 mov $0x7b,%eax
9: 5d pop %rbp
a: c3 retq
000000000000000b <main>:
b: 55 push %rbp
c: 48 89 e5 mov %rsp,%rbp
f: 48 83 ec 10 sub $0x10,%rsp
13: b8 00 00 00 00 mov $0x0,%eax
18: e8 00 00 00 00 callq 1d <main+0x12>
1d: 89 45 fc mov %eax,-0x4(%rbp)
20: 8b 45 fc mov -0x4(%rbp),%eax
23: 89 c6 mov %eax,%esi
25: 48 8d 3d 00 00 00 00 lea 0x0(%rip),%rdi # 2c <main+0x21>
2c: b8 00 00 00 00 mov $0x0,%eax
31: e8 00 00 00 00 callq 36 <main+0x2b>
36: b8 00 00 00 00 mov $0x0,%eax
3b: c9 leaveq
3c: c3 retq
当一个函数带有参数时,根据c语言默认的调用惯例cdecl,参数的入栈顺序为从右至左,例如有如下函数
int foo(int n , float m)那么在调用foo的时候,堆栈操作如下:
1.将m入栈
2.将n入栈
3.调用foo,此步又分为两个步骤:
将返回地址(即调用foo之后的下一条指令地址)入栈
跳转到foo执行
当函数返回后:sp=sp+8(参数出栈,由于不需要得到出栈的数据,所以直接调整栈顶位置就可以了。)因此调用foo的栈构成会如图(包含寄存器和局部变量等)

对于不同的编译器,由于分配局部变量和保存寄存器的策略不同,这个结果可能有出入。在以上布局中,如果想访问变量n,实际的地址是ebp+8,当foo返回的时候,程序首先会使用pop恢复保存在栈里的寄存器,然后从栈里取得返回地址,返回到调用方。调用方再调整esp将堆栈恢复。
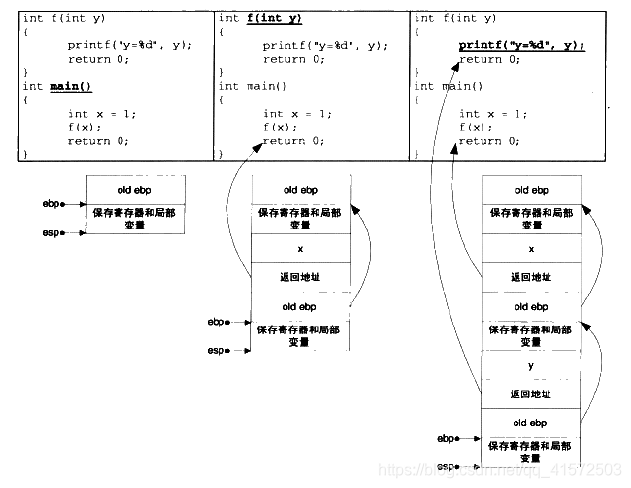
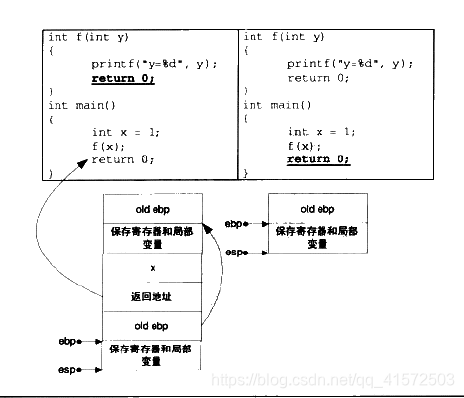
对于多级函数调用的情况,如
void f(int y)
{
printf("y=%d,"y);
}
int main()
{
int x = 1;
f(x);
return 0;
}这些代码形成的堆栈格局如图:
几个常用的调用惯例如下:

函数返回值的传递
除了参数的传递之外,函数与调用方的交互还有一个渠道就是返回值。在之前的例子中,我们发现eax是传递返回值的通道。函数将返回值存储在eax中,返回后函数的调用方再读取eax。但是eax本身只有4个字节,那么大于4字节的返回值是如何传递的呢?
对于返回5~8字节对象的情况,几乎所有的调用惯例都是采用eax和edx联合返回的方式进行的。其中eax存储返回值低4字节,edx存储返回值高1~4字节。而对于超过8字节的返回值如结构体,eax存储的是指向它的指针。
例如如下程序:返回值是一个结构体,
typedef struct big_thing
{
char buf[128];
}big_thing;
big_thing return_test()
{
big_thing b;
b.buf[0] = 0;
return b;
}
int main()
{
big_thing n = return_test();
return 0;
}反汇编之:
0000000000000000 <return_test>:
0: 55 push %rbp
1: 48 89 e5 mov %rsp,%rbp
4: 48 81 ec a0 00 00 00 sub $0xa0,%rsp
b: 48 89 bd 68 ff ff ff mov %rdi,-0x98(%rbp)
12: 64 48 8b 04 25 28 00 mov %fs:0x28,%rax
19: 00 00
1b: 48 89 45 f8 mov %rax,-0x8(%rbp)
1f: 31 c0 xor %eax,%eax
21: c6 85 70 ff ff ff 00 movb $0x0,-0x90(%rbp)
28: 48 8b 85 68 ff ff ff mov -0x98(%rbp),%rax
2f: 48 8b 95 70 ff ff ff mov -0x90(%rbp),%rdx
36: 48 8b 8d 78 ff ff ff mov -0x88(%rbp),%rcx
3d: 48 89 10 mov %rdx,(%rax)
40: 48 89 48 08 mov %rcx,0x8(%rax)
44: 48 8b 55 80 mov -0x80(%rbp),%rdx
48: 48 8b 4d 88 mov -0x78(%rbp),%rcx
4c: 48 89 50 10 mov %rdx,0x10(%rax)
50: 48 89 48 18 mov %rcx,0x18(%rax)
54: 48 8b 55 90 mov -0x70(%rbp),%rdx
58: 48 8b 4d 98 mov -0x68(%rbp),%rcx
5c: 48 89 50 20 mov %rdx,0x20(%rax)
60: 48 89 48 28 mov %rcx,0x28(%rax)
64: 48 8b 55 a0 mov -0x60(%rbp),%rdx
68: 48 8b 4d a8 mov -0x58(%rbp),%rcx
6c: 48 89 50 30 mov %rdx,0x30(%rax)
70: 48 89 48 38 mov %rcx,0x38(%rax)
74: 48 8b 55 b0 mov -0x50(%rbp),%rdx
78: 48 8b 4d b8 mov -0x48(%rbp),%rcx
7c: 48 89 50 40 mov %rdx,0x40(%rax)
80: 48 89 48 48 mov %rcx,0x48(%rax)
84: 48 8b 55 c0 mov -0x40(%rbp),%rdx
88: 48 8b 4d c8 mov -0x38(%rbp),%rcx
8c: 48 89 50 50 mov %rdx,0x50(%rax)
90: 48 89 48 58 mov %rcx,0x58(%rax)
94: 48 8b 55 d0 mov -0x30(%rbp),%rdx
98: 48 8b 4d d8 mov -0x28(%rbp),%rcx
9c: 48 89 50 60 mov %rdx,0x60(%rax)
a0: 48 89 48 68 mov %rcx,0x68(%rax)
a4: 48 8b 55 e0 mov -0x20(%rbp),%rdx
a8: 48 8b 4d e8 mov -0x18(%rbp),%rcx
ac: 48 89 50 70 mov %rdx,0x70(%rax)
b0: 48 89 48 78 mov %rcx,0x78(%rax)
b4: 48 8b 85 68 ff ff ff mov -0x98(%rbp),%rax
bb: 48 8b 4d f8 mov -0x8(%rbp),%rcx
bf: 64 48 33 0c 25 28 00 xor %fs:0x28,%rcx
c6: 00 00
c8: 74 05 je cf <return_test+0xcf>
ca: e8 00 00 00 00 callq cf <return_test+0xcf>
cf: c9 leaveq
d0: c3 retq
00000000000000d1 <main>:
d1: 55 push %rbp
d2: 48 89 e5 mov %rsp,%rbp
d5: 48 81 ec 90 00 00 00 sub $0x90,%rsp
dc: 64 48 8b 04 25 28 00 mov %fs:0x28,%rax
e3: 00 00
e5: 48 89 45 f8 mov %rax,-0x8(%rbp)
e9: 31 c0 xor %eax,%eax
eb: 48 8d 85 70 ff ff ff lea -0x90(%rbp),%rax
f2: 48 89 c7 mov %rax,%rdi
f5: b8 00 00 00 00 mov $0x0,%eax
fa: e8 00 00 00 00 callq ff <main+0x2e>
ff: b8 00 00 00 00 mov $0x0,%eax
104: 48 8b 55 f8 mov -0x8(%rbp),%rdx
108: 64 48 33 14 25 28 00 xor %fs:0x28,%rdx
10f: 00 00
111: 74 05 je 118 <main+0x47>
113: e8 00 00 00 00 callq 118 <main+0x47>
118: c9 leaveq
119: c3 retq 传递返回值的操作如下:
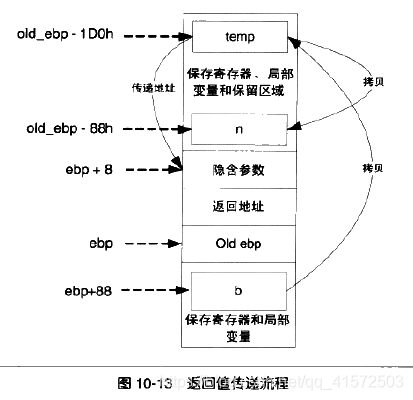
1.首先main函数在栈上额外开辟了一片空间,并将这块空间的一部分作为传递返回值的临时对象,这里称为temp
2.将temp对象的地址作为隐藏参数传递给return_test函数
3.return_test函数将数据拷贝给temp对象,并将temp对象的地址用eax传出
4.return_test返回后,main函数将eax指向的temp对象的内容拷贝给n
整个流程的伪代码如下:
void return_test(void* temp)
{
big_thing b;
b.buf[0] = 0;
memcpy(temp,&b,sizeof(big_thing));
eax = temp;
}
int main()
{
big_thing temp;
big_thing n;
return_test (&temp);
memcpy(&n,eax,sizeof(big_thing));
return 0;
}流程图:
cpp为了解决返回值时要拷贝构造和赋值构造的问题,使用了移动赋值构造,来减少一次构造:
#include <iostream>
using namespace std;
//构造函数与赋值运算符的区别是,构造函数在创建或初始化对象的时候调用,而赋值运算符在更新一个对象的值时调用。
class A {
public:
A(int a):x(a) { cout << "调用了构造函数" << endl; }
A& operator=(const A& a) { cout << "调用了赋值构造函数" << endl; this->x = a.x; return *this; }
A(const A& a):x(a.x){ cout << "调用了拷贝构造函数" << endl; }
A(const A&& a):x(a.x){ cout << "调用了移动构造函数" << endl; }
A& operator=(const A&& a) { cout << "调用了移动赋值构造函数" << endl; this->x = a.x; return *this; }
~A(){ cout << "调用了析构函数" << endl; }
int x;
};
A func() {
A a(1);
cout<<"before return in func"<<endl;
return a;
}
int main() {
A qq(0);
qq = func();
//system("pause");
return 0;
}运行结果:
调用了构造函数
调用了构造函数
before return in func
调用了移动赋值构造函数
调用了析构函数
调用了析构函数
堆
malloc到底是怎么实现的?若把进程的内存管理交给操作系统内核去做(因为内核管理着进程的地址空间),每次申请内存的时候通过系统调用来实现,这样做的话性能比较差,因为每次程序申请或者释放堆空间都需要进行系统调用,开销较大。比较好的做法是程序向操作系统申请一块适当大小的堆空间,然后由程序自己管理这块空间,而具体来讲,管理着堆空间分配的往往是程序的运行库。
运行库相当于是向操作系统批发了一块较大的堆空间,然后零售给程序用。当全部售完或者程序有大量的内存需求时,再根据实际需求向操作系统进货。当然运行库在向程序零售堆空间时,必须管理它批发来的堆空间,不能把同一块地址出售两次,导致地址的冲突。(要讲到内存池的算法了)
- 在这里先讲一讲linux的进程堆管理:
linux进程堆管理有两种分配方式,即两个系统调用:brk()和mmap()
brk的c语言形式声明如下:
int brk(void* end_data_segment)brk的作用实际上就是设置进程数据段(data和bss段)的结束地址,即它可以扩大或者缩小数据段。若我们将数据段的结束地址向高地址移动,那么扩大的部分空间就可以被我们使用。
mmap()的作用是想操作系统申请一段虚拟地址空间,当然这块虚拟地址空间可以映射到某个文件(这也是这个系统调用的最初作用),当它不将地址空间映射到某个文件时,我们又称这块空间为匿名空间,匿名空间就可以拿来作为堆空间。它的生声明如下:
void *mmap(
void *start;
size_t length;
int prot;
int flag;
int fd;
off_t offset
);mmap的前两个参数分别用于指定需要申请的空间的起始地址和长度,如果起始地址设置为0,那么linux系统会自动挑选合适的起始地址。prot/flag这两个参数用于设置申请的空间的权限(可读、可写、可执行)以及映射类型(文件映射、匿名空间等),最后两个参数是用于文件映射时指定文件描述符和文件偏移的。
glibc的malloc函数是这样处理用户的空间请求的:对于小于128KB的请求来说,他会在现有的堆空间里面,按照堆分配算法为他分配一块空间并返回,对于大于128KB的请求来说,他会使用mmap()函数为他分配一块匿名空间,然后再这个匿名空间中为用户分配空间。当然我们直接使用mmap也可以轻而易举地实现malloc函数:
void *malloc(size_t nbytes)
{
void* ret = mmap(0,nbytes, PROT_READ | PROT_WRITE, MAP_PRIVATE | MAP_ANONYMOUS,0,0);
if(ret==MAP_FAILED)
return 0;
return ret;
}
- 堆分配算法
如何管理一大块连续的内存空间,能够按照需求分配、释放其中的空间,这就是堆分配算法。
1. 空闲链表
空闲链表( Free List)的方法实际上就是把堆中各个空闲的块按照链表的方式连接起来,当用户请求一块空间时,可以遍历整个列表,直到找到合适大小的块并且将它拆分;当用户释放空间时将它合并到空闲链表中。
我们首先需要一个数据结构来登记堆空间里所有的空闲空间,这样才能知道程序请求空间的时候该分配给它哪一块内存。这样的结构有很多种,这里介绍最简单的一种空闲链表空闲链表是这样一种结构,在堆里的每一个空闲空间的开头(或结尾)有一个头( header),头结构里记录了上一个(prev)和下一个(next)空闲块的地址,也就是说,所有的空闲块形成了一个链表。如图
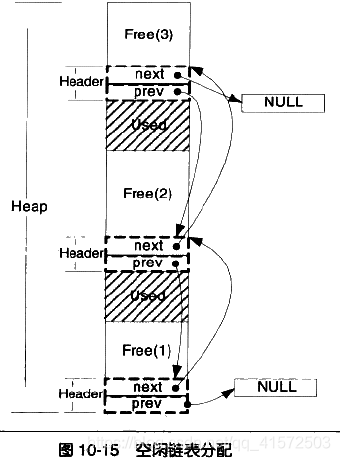
在这样结构下如何分配空间呢?
首先在空闲链表中查找足够容纳大小的一个空闲块,然后将这个块分为两个部分,一部分为程序请求的空间,另一部分为剩余的空闲空间。下面将链表里对应的原来的空闲块的结构更新为新的剩下来的空闲块,如果剩下的空闲块大小为0,则直接将这个结构从链表里删除。图10-16演示了用户请求了一块和空闲块2恰好相等的内存空间的堆的状态
这样的空闲链表实现尽管简单,但在释放空间的时候,给定一个已分配块的指针,堆无法确定这个块的大小。一个简单的解决方法是当用户请求k个字节空间的时候,我们实际分配k+4个字节,这4个字节用于存储该分配的大小,即k+4。这样释放该内存的时候只要看看这4个字节的值,就能知道该内存块的大小,然后将其插入到空闲链表里就可以了。
当然这仅仅是最简单的一种分配策略,这样的思路存在很多问题。例如,一旦链表被破坏,或者记录长度的那4字节被破坏,整个堆就无法正常工作,而这些数据恰恰很容易被越界读写所接触到。
2. 位图
针对空闲链表的弊端,另一种分配方式显得更加稳健。这种方式称为位图( Bitmap),其核心思想是将整个堆划分为大量的块( block),每个块的大小相同。当用户请求内存的时候,总是分配整数个块的空间给用户,第一个块我们称为已分配区域的头(Head),其余的称为己分配区域的主体(Body)。而我们可以使用一个整数数组来记录块的使用情况,由于每个块只有头/主体空闲三种状态,因此仅仅需要两位即可表示一个块,因此称为位图。
假设堆的大小为1MB,那么我们让一个块大小为128字节,那么总共就有1M/128=8k个块,可以用8k/(32/2)=512个int来存储。这有512个int的数组就是一个位图,其中每两位代表一个块。当用户请求300字节的内存时,堆分配给用户3个块,并将位图的相应位置
标记为头或躯体。
图10-17为一个这样的堆的实例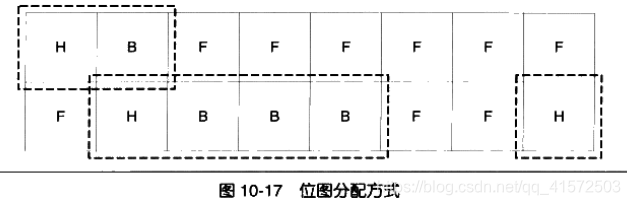
这个堆分配了3片内存,分别有2/4/1个块,用虚线框标出。其对应的位图将是:
(HIGH) 11 00 00 10 10 10 11 00 00 00 00 00 00 00 10 11 (LOW)
其中11表示H(HEAD),10表示主体(Body),00表示空闲(Free)
这样的实现方式有几个优点:
- 速度快:由于整个堆的空闲信息存储在一个数组内,因此访问该数组时cache容易命中;
- 稳定性好:为了避免用户越界读写破坏数据,我们只须简单备份一下位图即可,而且即使部分数据被破坏,也不会导致整个堆无法工作
- 块也不需要额外信息,易于管理
当然缺点也是显而易见的
- 分配内存的时候容易产生碎片。例如分配300字节的时候,实际分配了3块即384个字节,浪费了84个字节
- 如果堆很大,或者设定的一个块很小(这样可以减少碎片),那么位图将会很大,可能会失去cache命中率很高的优势,而且也会浪费一定的空间。针对这种情况,我们可以使用多级的位图。
3. 对象池
以上介绍的堆管理方法是最为基本的两种,实际上在一些场合,被分配对象的大小是较为固定的几个值,这时候我们可以针对这样的特征设计一个更为高效的堆算法,称为对象池。
对象池的思路很简单,如果每一次分配的空间大小都一样,那么就可以按照这个每次请求分配的大小作为一个单位,把整个堆空间划分为大量的小块,每次请求的时候只需要找到个小块就可以了
对象池的管理方法可以采用空闲链表,也可以采用位图,与它们的区别仅仅在于它假定了每次请求的都是一个固定的大小,因此实现起来很容易。由于每次总是只请求一个单位的内存,因此请求得到满足的速度非常快,无须查找一个足够大的空间。
实际上很多现实应用中,堆的分配算法往往是采取多种算法复合而成的。比如对于 glibc来说,它对于小于64字节的空间申请是采用类似于对象池的方法;而对于大于512字节的空间申请采用的是最佳适配算法:对于大于64字节而小于512字节的,它会根据情况采取上述方法中的最佳折中策略:对于大于128KB的申请,它会使用mmap机制直接向操作系统申请空间。
内存池的设计:链表+hash和大顶堆两种方式https://blog.csdn.net/shawngucas/article/details/6574863
有一个特殊场景:维护一个内存池,池中每个块的大小都相等,用什么样的方案实现O1申请和O1释放内存?
方案:整个内存池其实就是一个单链表,表头指向第一个没有使用节点,我们可以把这个单链表想象成一段链条,调用方法New就是从链条的一端(单链表表头)取走一节点,调用方法Delete就是在链条的一端(单链表表头)前面插入一个节点,新插入的节点就是链表的表头,这样New和Delete的时间复杂度都是O(1)。
系统调用
linux的系统调用:
在X86系统下,系统调用由0x80中断完成,各个通用寄存器用于传递参数,eax寄存器用于表示系统调用的接口号,比如eax=1表示退出进程exit,eax=2表示创建进程fork,eax=3表示读取文件或IO即read,eax=4表示写文件或IO即write等。每个系统调用都对应于内核源代码中的一个函数,他们都是以“sys_”开头的,比如exit调用对应内核中的sys_exit函数。当系统调用返回时,eax又作为调用结果的返回值。此处列举一部分系统调用:


运行时库将不同的操作系统里的系统调用包装为统一固定的接口,使得同样的代码,在不同的操作系统下都可以直接编译,并产生一致的效果,这就是源代码级上的可移植性。
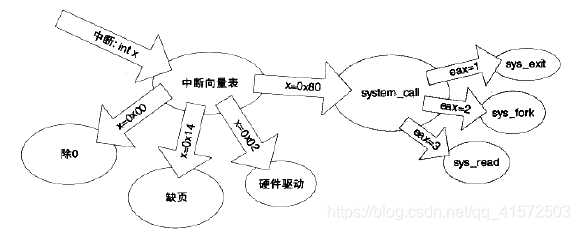
操作系统一般是通过中断来从用户态切换到内核态。中断一般有两个属性,一个称为中断号(从0开始),一个称为中断处理程序interrupt service routing 。不同的中断具有不同的中断号,而同时一个中断处理程序一一对应一个中断号。内核中有一个数组称为中断向量表,这个数组的第n项包含了指向第n号中断处理程序的指针。当中断到来时,CPU会暂停当前执行的代码,根据中断号在中断向量表中找到对应的中断处理程序,并调用它。中断处理程序执行完成后,CPU会继续执行之前的代码,如图:
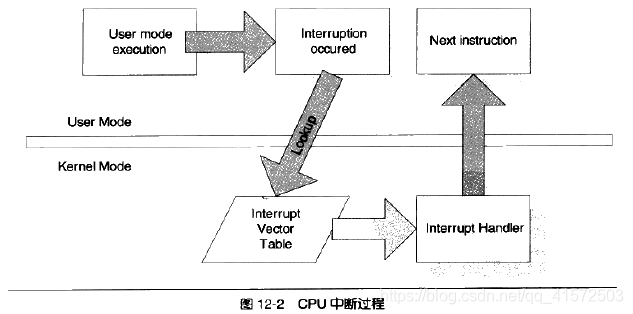
通常意义上,中断有两种类型,一种称为硬件中断,这种中断来自于硬件的异常或其他事件的发生,如电源掉电、键盘被按下等。另一种称为软件中断,通常是一条指令,带有一个参数记录中断号,使用这条指令用户可以手动出发某个中断并执行其中断处理程序,例如在i386下,int 0x80这条指令会调用第0x80号中断的处理程序。
由于中断号是很有限的,操作系统不会舍得用一个中断号来对应一个系统调用,。例如linux的int0x80,系统调用号是由eax来传入的。用户将系统调用号放入eax,然后使用int 0x80调用中断,中断服务程序就可以从eax里取得系统调用号,进而调用对应的函数。例如fork的过程:
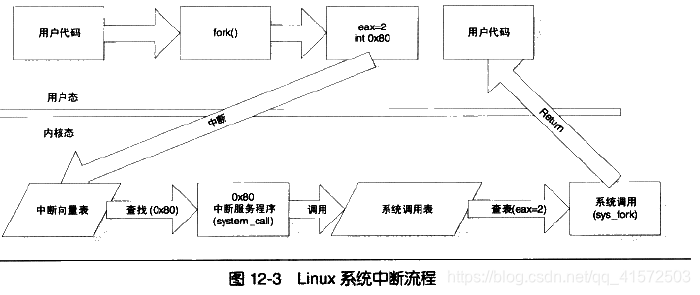
系统调用的参数可通过6个寄存器来传递:ebx,ecx,edx,esi,edi和ebp,若参数太多或者参数为结构体,则只在寄存器中存放参数的地址。
中断号和系统调用的关系如图:
- 切换堆栈
在实际执行中断向量表中第0x80号元素所对应的函数之前,CPU首先还要进行栈的切换。在linnux中,用户态和内核态使用的是不同的栈,两者各自负责各自的函数调用,互不干扰。
所谓的“当前栈”指的是ESP的值所在的栈空间,如果ESP的值位于用户栈的范围内,那么程序的当前栈就是用户栈,反之亦然。此外,寄存器SS的值还应该指向当前栈所在的页。所以,将当前栈由用户栈切换为内核栈的实际行为就是:
1.保存当前的ESP、SS值
2.将ESP、SS值设置为内核栈的相应值。
反之则将ESP、SS值恢复为用户栈的相应值。
因此,当0x80号中断发生的时候,CPU除了切入内核态之外,还会自动完成下列几件事:
- 1.找到当前进程的内核栈(每一个进程都有自己的内核栈)
- 2.在内核栈中依次压入用户态的寄存器SS、ESP、EFALGS、CS、EIP
而当内核从系统调用中返回的时候,须要调用iret指令来回到用户态,iret指令则会从内核栈里弹出寄存器SS、ESP、EFALGS、CS、EIP的值,使得栈恢复到用户态的状态。过程如图:
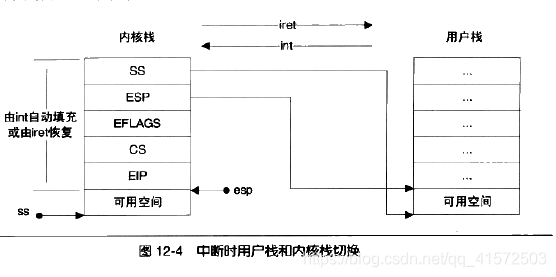
插入一下
-------------------------------------------------------
在c程序中执行shell命令:
int ret = system("echo hacker | nc.exe -u 127.1 22");
//ret==0说明没有开启22端口
if (ret == 0 ) printf("nc: Write error: Connection refused.\n");
---------------------------------------------------------


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









