






该部分贴一些原博主的关于CV和图像相关的题目
三、图像处理
(1)opencv遍历像素的方式?
1.使用at<dtype>(ij)[c]来访问
2.使用ptr<dtpye>(col)[c]来访问,若图像存储连续,可以直接展开成一行来应用指针遍历
3.使用迭代器begin<dtype>, end<dtype>来访问,用法与指针一样
(2)LBP原理?
原始的LBP算子定义为在3*3的窗口内,以窗口中心像素为阈值,将相邻的8个像素的灰度值与其进行比较,若周围像素值大于中心像素值,则该像素点的位置被标记为1,否则为0。这样,3*3邻域内的8个点经比较可产生8位二进制数(通常转换为十进制数即LBP码,共256种),即得到该窗口中心像素点的LBP值,并用这个值来反映该区域的纹理信息。如下图所示:

LBP对光照具有很强的鲁棒性
LBP的应用中,如纹理分类、人脸分析等,一般都不将LBP图谱作为特征向量用于分类识别,而是采用LBP特征谱的统计直方图作为特征向量用于分类识别。
(3)HOG特征计算过程,还有介绍一个应用HOG特征的应用?
HOG特征计算过程:
1、标准化gamma空间和颜色空间,即对整个图像归一化,然后转至灰度空间。
2、计算图像梯度,首先按式计算得每个像素的横纵向梯度,在求平方和开根号得梯度赋值与梯度方向:

3、构建cell的梯度方向直方图,即先确定直方图的bin数,也就是把360平分为bin分,将cell内梯度方向位于某bin范围的像素的梯度幅值按一定规则加入到该区域对应的bin中,从而得到一个cell中的梯度方向直方图。
4、构建块的梯度直方图,一个块中可能有若干个cell,将这些cell的直方图串联起来,并做归一化后就是块的直方图。
5、构建图像的梯度直方图,一副图像中又有若干个块,再将若干块的直方图串联拼接起来,即为一副图像的HOG特征。
HOG特征+SVM做图像识别
(4)opencv里面mat有哪些构造函数
1、Mat::Mat()
无参数构造方法;
2、Mat::Mat(int rows, int cols, int type)
创建行数为 rows,列数为 col,类型为 type 的图像;
3、Mat::Mat(Size size, int type)
创建大小为 size,类型为 type 的图像;
4、Mat::Mat(int rows, int cols, int type, const Scalar& s)
创建行数为 rows,列数为 col,类型为 type 的图像,并将所有元素初始化为值 s;
5、Mat::Mat(Size size, int type, const Scalar& s)
创建大小为 size,类型为 type 的图像,并将所有元素初始化为值 s;
6、Mat::Mat(const Mat& m)
将m赋值给新创建的对象,此处不会对图像数据进行复制,m和新对象共用图像数据,属于浅拷贝;
7、Mat::Mat(int rows, int cols, int type, void* data, size_t step=AUTO_STEP)
创建行数为rows,列数为col,类型为type的图像,此构造函数不创建图像数据所需内存,而是直接使用data所指内存,图像的行步长由 step指定。
8、Mat::Mat(Size size, int type, void* data, size_t step=AUTO_STEP)
创建大小为size,类型为type的图像,此构造函数不创建图像数据所需内存,而是直接使用data所指内存,图像的行步长由step指定。
9、Mat::Mat(const Mat& m, const Range& rowRange, const Range& colRange)
创建的新图像为m的一部分,具体的范围由rowRange和colRange指定,此构造函数也不进行图像数据的复制操作,新图像与m共用图像数据;
10、Mat::Mat(const Mat& m, const Rect& roi)
创建的新图像为m的一部分,具体的范围roi指定,此构造函数也不进行图像数据的复制操作,新图像与m共用图像数据。
(5)边缘检测算法
Reboerts算子是一种利用局部差分来寻找边缘的算子,Roberts 梯度算子所采用的是对角方向相邻两像素值之差
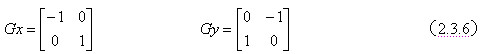
Sobel算子在边缘检测算子扩大了其模版,在边缘检测的同时尽量削弱了噪声。其模版大小为3×3,其将方向差分运算与局部加权平均相结合来提取边缘。在求取图像梯度之前,先进行加权平均,然后进行微分,加强了对噪声的一致
Prewitt算子则是与Sobel类似的,不加权只求平均的方式来求得梯度,即将下图的2都改成1。
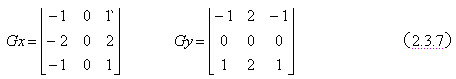
Laplace算子是不依赖于边缘方向的二阶导数算子,即求得二阶导数过0点,也就是对应的一阶微分局部变化率峰值来作为边缘。
Canny算子检测边缘的土体算法如下:
1用式所示的高斯函数h(r)对图像进行平滑滤波,去除图像中的噪声。
2在每一点计算出局部梯度和边缘方向,可以利用Sobel算子、Roberts算子等来计算。边缘点定义为梯度方向上其强度局部最大的点。
3对梯度进行“非极大值抑制”。在第二步中确定的边缘点会导致梯度幅度图像中出现脊。然后用算法追踪所有脊的顶部,并将所有不在脊的顶部的像素设为零,以便在输出中给出一条细线。
4双阈值化和边缘连接。脊像素使用两个闽值Tl和T2做阈值处理,其中Tl<T2.值大于T2的脊像素称为强边缘像素,Tl和T2之间的脊像素称为弱边缘像素。由于边缘阵列是用高阈值得到的,因此它含有较少的假边缘,但同时也损失了一些有用的边缘信息。而边缘阵列Tl的阈值较低,保留了较多信息。因此,可以以边缘阵列为基础,用边缘阵列Tl进行补充连接,最后得到边缘图像。这里是不是补充完其实就是相当于只用到了T1?
(6)opencv里面为啥是bgr存储图片而不是人们常听的rgb
据说一开始是bgr比较流行,然后就一直用到现在
也有说官方文档里写的这样效率比较高
(7)opencv如何读取png格式的图片?
首先先说png图片有什么特殊,png图片不同于其他格式的图片,png图片具有4个通道,也就是说,除了常规大家都有的BGR三通道(彩色图片)外,png图片还多了个A通道,即alpha,透明度。
在读入时,imread的标志位置为-1即可读入四通道图片,另外说明,置为0则读入黑白图片,1为三通道彩色图。
(8)opencv如何读取内存图片
利用imencode和imdecode函数可以编码和解码一张图片,比如我们可以将一张图片编码之后作为string写入txt, 也可以从txt中读出编码后的内容解码成图片。
下面是在https://blog.csdn.net/tt_ren/article/details/53227900博客中,看到的源码,可以用来理解两个函数的应用。
#include <boost/filesystem.hpp>
#include <boost/filesystem/fstream.hpp>
#include <iostream>
#include <sstream>
#include <string>
#include <opencv2/opencv.hpp>
#include <vector>
using namespace boost::filesystem;
namespace newfs = boost::filesystem;
using namespace cv;
int main(int argc, char ** argv)
{
cv::Mat img_encode;
img_encode = imread("../res/test.png", CV_LOAD_IMAGE_COLOR);
//encode image and save to file
std::vector<uchar> data_encode;
imencode(".png", img_encode, data_encode);
std::string str_encode(data_encode.begin(), data_encode.end());
path p("../res/imgencode_cplus.txt");
newfs::ofstream ofs(p);
assert(ofs.is_open());
ofs << str_encode;
ofs.flush();
ofs.close();
//read image encode file and display
newfs::fstream ifs(p);
assert(ifs.is_open());
std::stringstream sstr;
while(ifs >> sstr.rdbuf());
ifs.close();
Mat img_decode;
std::string str_tmp = sstr.str();
std::vector<uchar> data(str_tmp.begin(), str_tmp.end());
img_decode = imdecode(data, CV_LOAD_IMAGE_COLOR);
imshow("pic",img_decode);
cvWaitKey(10000);
return 0;
}
(9)如何求一张图片的均值
可以考虑使用积分图,但是这里有个问题就是这么多的数据加一起溢出了怎么办,原作者采取的是分块计算
(10)求一张图片的方差
这里先贴出来方差公式:
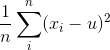
这里我们把平方打开,然后根据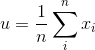
![\frac{1}{n} [\sum_{i}^{n} x_{i}^{2} - \frac{1}{n}(\sum_{i}^{n}x_{i})^{2}]](https://img-blog.csdnimg.cn/20181218172003544)
看到这里就很明白了,我们先预先针对一副图片做出来其像素值和像素平方值的积分图,然后按这个公式计算即可,时间复杂度为O(n)。
(11)如何写程序将图像放大缩小
笼统的讲就是插值法,而插值法又有如下几种:
这里主要是学习了https://blog.csdn.net/fengbingchun/article/details/17335477
原文中还写了很多的实现代码,非常利于理解
1、最近邻插值:
简单的讲就是,先计算出来图片扩大比例alpha,然后依据这个比例将新图中的一个点(xnew,ynew)换算到原图中的坐标(xnew/alpha,ynew/alpha),当然这是通过一定的取整原则不会有小数出现,然后再取原图中坐标下的像素值赋给新图。
2、双线性插值:
简单的讲,首先使用与最近邻方法类似的方法来换算出坐标,然后利用下面的公式求取新图中的像素值:
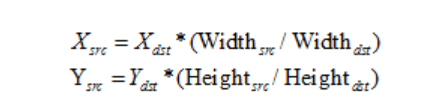
这个地方的u,v两参数是什么呢,看一下上面博客的内容就可以大概能明白, 白话说就是,假如我换算出来的坐标是(1.3,1.6)那这个取整之后可能就是(1,2),那肯定有偏差,毕竟只是取整过去的,于是取了个折中的办法,我用前一个像素的0.3和后一个像素的0.7,上面一个像素的0.6和下面一个像素的0.4做个加权和,来得到当前位置的像素,这样就按比例偏谁多点就取谁相应的多点。
3、双三次线性插值:
类似于双线性,只不过把波及范围扩大了,现在一个新点的像素由,以其换算坐标为中心的附近4*4,16个点来加权决定。
4、基于像素区域关系:
这个算法其实就是综合了前面几个,首先分为图片放大和缩小两个情况,放大就直接使用双线性插值,缩小的话又分为两个情况,缩放比是整数还是小数,整数的话直接使用最近邻方法,小数的话还是使用了类似双线性插值的方法,只不过偏重系数定义有改变。
5、兰索斯插值:
这次是64个点的类似双线性插值的方法了。
(12)Graphcut的原理与应用
这里是看了大神博客得出的总结:https://blog.csdn.net/zouxy09/article/details/8532111
算法理论上比较复杂,需要先按照一定规则将一副图片转变为一个连接图,所有的像素点都作为图的顶点,相邻的像素点之间存在连接,连接的权值由下式定义:
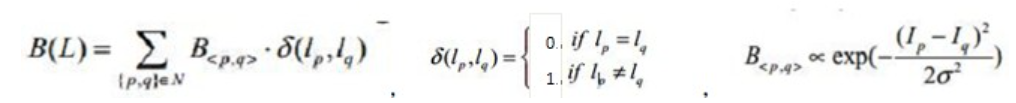
这里的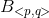
这样就完成了像素间的连接图构造,但是在该算法中,还需要额外建立两个顶点,即源节点S和汇节点T,现在再将每个像素顶点与S,T顶点连接起来,连接权分别为:
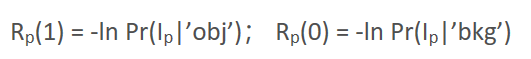
这里的公式通俗的讲就是,每个像素和S的连接权与其属于前景的概率成正比,每个像素和T的连接权与其属于后景的概率成正比。
这样就构建完成了一个完整的连接图,大体形状如下所示,类似于一个菱形,这里不要想成立体图形,要想成平面图:

那么我们现在需要一个切线,来将这个连接图切开,切成两部分,其中S,T分别位于两部分,而与S,T在同一部分的像素点则分别属于前景和后景,那么如何切呢?
我们切的时候要保持下式最小的要求:

其中:
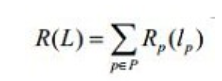
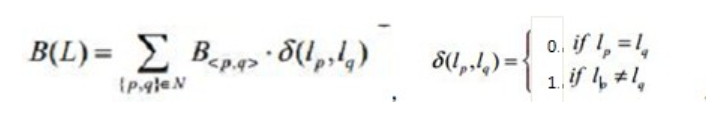
R(L),B(L)就是对于我们切断的连接边的权重和,分别是像素顶点与ST点间的和像素顶点间的权重和。
这样我们分开来看的话,对于R(L),我们选择那些不属于前景的像素顶点与S点的连接边,以及不属于后景的像素顶点与T点的连接边来作为切点的话,可以让R(L)最小。
而对于B(L),选择差异最大的相邻像素顶点间的连接边可使其最小。
以上图为例,应该这样切:

注意我们切开了相差大的相邻像素的连接线,以及蓝黑色虚线也是按上述原则切开的。
这样我们就锁定了切面,与T保持链接的像素是后景像素,与S保持连接的像素是前景像素,也就分开了前后景像素达到了图片切割的工作,当然这里只是一些个人理解
(13)EM算法与GMM混合模型
EM算法网上有很多的推导,主要是从概率论的角度出发推演EM算法,这里就写一个白话版本,忽略公式推导,直接看应用,用我觉得比较直观的语言逻辑来看这个算法,首先我们要知道做参数估计现在选择的多是最大似然函数,但是像GMM这种多个分布叠加在一起的混合模型,我们使用最大似然函数就存在一定的弊端,先看一下GMM混合模型的定义:

看到这里,我们就有个问题,假如有很多样本x1,x2.......xn,那么哪几个样本是由第一个分模型为主产生的?哪几个样本是由第k个分模型为主产生的呢?这个不知道就无法使用最大似然来估计高斯分布中的miu和theta。那么就可以这样来做:
引入EM算法,EM算法的本质就是分两步循环迭代直到收敛,这两步也就是E步和M步,E步就是期望步,即在当前我们估计的一系列参数下,产生这些样本的概率,M步是最大步,就是对于某些样本,我们的分布产生这些样本有最大概率时,对应的分布参数。
看GMM的公式我们就知道,我们要估计的参数有三块,即每个分模型的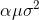
这里先看E步,为了知道某个x由第k个分模型产生的概率是多少,我们有了下式:
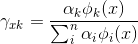
这个公式得到的就是,某个样本x属于第k个分模型的概率,也可以理解为:样本x中,由第k个分模型生成的部分占有多大比例
这样我们就可以解决刚刚说的,不知道每一个样本xi具体属于哪个分模型的问题,由式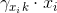
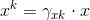
然后是M步,在E步中得到了专属每个分模型的新样本集,那么就可以根据这个新样本集利用最大似然来刷新分模型的参数:
在这里对于第k个分模型的三个参数,有最大似然估计:
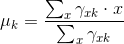
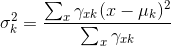
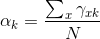
这样不停的迭代EM步,等到每一个分模型的参数都收敛于一个定值之后,结束迭代。
这里贴一个辅助理解的实例:https://blog.csdn.net/u011300443/article/details/46763743?utm_source=blogxgwz3
(14)随机森林的随机性体现在哪里
首先随机森林是由多个决策树构成的分类器,将决策树作为bagging中的模型,利用bootstrap方法来生成新的数据集,在训练每一颗决策树时,在树节点的选择上也是先随机选择一部分特征,再从这部分特征中选择最优信息增益的特征作为节点。
所以随机森林的随机性主要表现在生成新样本时的随机性,以及每颗决策树模型训练中节点选择的随机性














 871
871











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









