







这两天看到一篇文章描述了由mybatis导致的oom,感觉有点懵了,这里还有坑?看的我是那个茅塞顿开啊,感觉自己下次换工作,好像又可以吹下自己实际工作中遇见的mybatis坑了,不过为了到时候描述的更逼真一下,还是自己干一下才行!
按照文章介绍,简单搭建一下环境,开始测试!
数据库连接
spring:
datasource:
driver-class-name: com.mysql.cj.jdbc.Driver
url: jdbc:mysql://localhost:3306/sys?characterEncoding=utf-8&autoReconnect=true&failOverReadOnly=false&useSSL=false
username: root
password: root
Mapper文件
public interface UserMapper extends BaseMapper<User> {
Long selectCnt(@Param("ids") List<Long> ids);
}
xml文件
<select id="selectCnt" resultType="java.lang.Long">
select count(*) from user
where id in <foreach collection="ids" item="id" separator="," open="(" close=")">
#{id}
</foreach>
</select>
jvm 堆内存设置(本地很关键,堆内存大了不好演示,调小一点)
-Xmx256m -XX:+PrintGCDetails -XX:+HeapDumpOnOutOfMemoryError
开启测试
这里主要是测试in条件在多线程环境下可能会出现oom的情况,sql很简单,就一个count(*)查询。
@Test
public void test2(){
AtomicInteger ai = new AtomicInteger(0);
for(int threadId =0;threadId <50;threadId++){
int finalThreadId = threadId;
new Thread(()->{
List<Long> ids = getIds(100000 + finalThreadId);
Long aLong = userMapper.selectCnt(ids);
ai.getAndIncrement();
System.out.println(finalThreadId +"::开始了");
}).start();
}
while (ai.get() <50){
}
System.out.println("结束。。。。。。。。。。");
}
private List<Long> getIds(int size){
List<Long> list =new ArrayList<>();
for(long i = 0;i<size;i++){
list.add(i);
}
return list;
}
控制台开始疯狂打印Full GC
[Full GC (Ergonomics) [PSYoungGen: 29696K->29394K(58368K)] [ParOldGen: 174877K->174877K(175104K)] 204573K->204271K(233472K), [Metaspace: 38486K->38486K(1085440K)], 0.0941873 secs] [Times: user=0.64 sys=0.00, real=0.09 secs]
[Full GC (Ergonomics) [PSYoungGen: 29696K->29407K(58368K)] [ParOldGen: 174877K->174877K(175104K)] 204573K->204284K(233472K), [Metaspace: 38486K->38486K(1085440K)], 0.0937098 secs] [Times: user=0.78 sys=0.00, real=0.09 secs]
[Full GC (Ergonomics) [PSYoungGen: 29696K->29417K(58368K)] [ParOldGen: 174877K->174877K(175104K)] 204573K->204294K(233472K), [Metaspace: 38486K->38486K(1085440K)], 0.0953067 secs] [Times: user=0.66 sys=0.00, real=0.10 secs]
[Full GC (Ergonomics) [PSYoungGen: 29696K->28788K(58368K)] [ParOldGen: 174877K->174797K(175104K)] 204573K->203585K(233472K), [Metaspace: 38486K->38486K(1085440K)], 0.1356401 secs] [Times: user=1.19 sys=0.00, real=0.13 secs]
Exception in thread "Thread-6" java.lang.OutOfMemoryError: Java heap space
[Full GC (Ergonomics) [PSYoungGen: 29696K->29219K(58368K)] [ParOldGen: 172152K->172152K(175104K)] 201848K->201372K(233472K), [Metaspace: 38536K->38536K(1085440K)], 0.0916355 secs] [Times: user=0.75 sys=0.00, real=0.09 secs]
[Full GC (Ergonomics) [PSYoungGen: 29696K->29236K(58368K)] [ParOldGen: 172152K->172152K(175104K)] 201848K->201389K(233472K), [Metaspace: 38536K->38536K(1085440K)], 0.0861813 secs] [Times: user=0.78 sys=0.00, real=0.09 secs]
Exception in thread "Thread-35" Exception in thread "Thread-16" java.lang.OutOfMemoryError: GC overhead limit exceeded
Dumping heap to java_pid463104.hprof ...
........
额。。。。。。。。。。。。。。。。
为啥呢?不就是sql中in的数量多点么?肯定是多线程的问题、、、
去掉多线程,改为单线程操作!
@Test
public void test2(){
AtomicInteger ai = new AtomicInteger(0);
for(int threadId =0;threadId <50;threadId++){
List<Long> ids = getIds(100000);
Long aLong = userMapper.selectCnt(ids);
ai.getAndIncrement();
System.out.println("::开始了");
// int finalThreadId = threadId;
// new Thread(()->{
// List<Long> ids = getIds(100000 + finalThreadId);
// Long aLong = userMapper.selectCnt(ids);
// ai.getAndIncrement();
// System.out.println(finalThreadId +"::开始了");
// }).start();
}
while (ai.get() <50){
}
System.out.println("结束。。。。。。。。。。");
}
控制台打印:
::开始了
::开始了
::开始了
::开始了
::开始了
::开始了
::开始了
::开始了
::开始了
::开始了
::开始了
结束。。。。。。。。。。
没问题,没有oom,说明单个查询是没有问题的,那为啥多线程环境下就不行?显示情况下不可能是单线程查询的啊,因为接口qps你不能线程成1.。。。。。
为什么多线程下会导致OOM
我们看到Full GC的时候的detail
[Full GC (Ergonomics) [PSYoungGen: 29696K->29696K(58368K)] [ParOldGen: 170834K->170833K(175104K)] 200530K->200529K(233472K), [Metaspace: 38543K->38543K(1085440K)], 0.1151393 secs]
java.lang.OutOfMemoryError: GC overhead limit exceeded
PSYoungGen:回收前29696K,回收后29696K,没有变化
ParOldGen: 回收前170834K,回收后170833K,回收了1K
堆内存:200530K->200529K(233472K)
GC overhead limit exceeded: jvm判定垃圾回收效率过低,执行垃圾收集的时间比例太大, 有效的运算量太小. 默认情况下, 如果GC花费的时间超过 98%, 并且GC回收的内存少于 2%, JVM就会抛出这个错误。
mybatis的原因
这里很多文章都归结于mybatis,Mybatis会带来OOM,主要是因为Mybatis拼接SQL的时候生成的占位符和参数对象,存放在Map里,当SQL的参数多导致SQL太长的时候,Map持有这些SQL时间较长,并且多线程同时操作,这时候内存占用就很高,从而发生OOM。
对DynamicContext类源码查看,DynamicContext又一个ContextMap 类型的参数bindings,继承了HashMap相当于一个Map集合,接着看这个类中的getBindings方法,看到了ForEachSqlNode这类调用了getBindings方法,简单的说就是ForEachSqlNode通过getBindings方法,将SQL参数和参数的占位符统一put到ContextMap这个集合里面,主要是这里面的参数和占位符无法被GC回收,并发查询量多的情况下就会导致OOM。
貌似是这个原因?
mat分析hprof文件
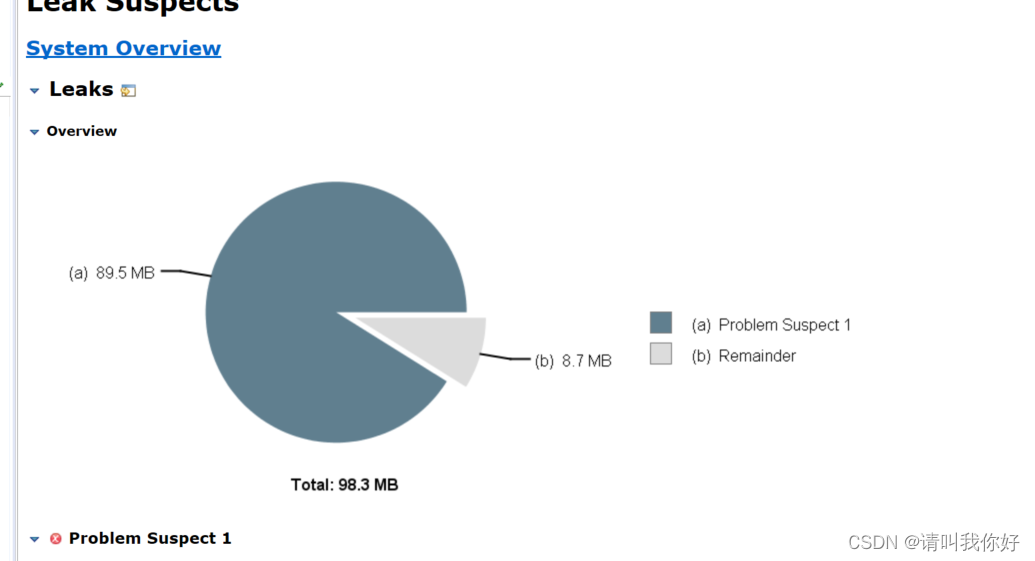
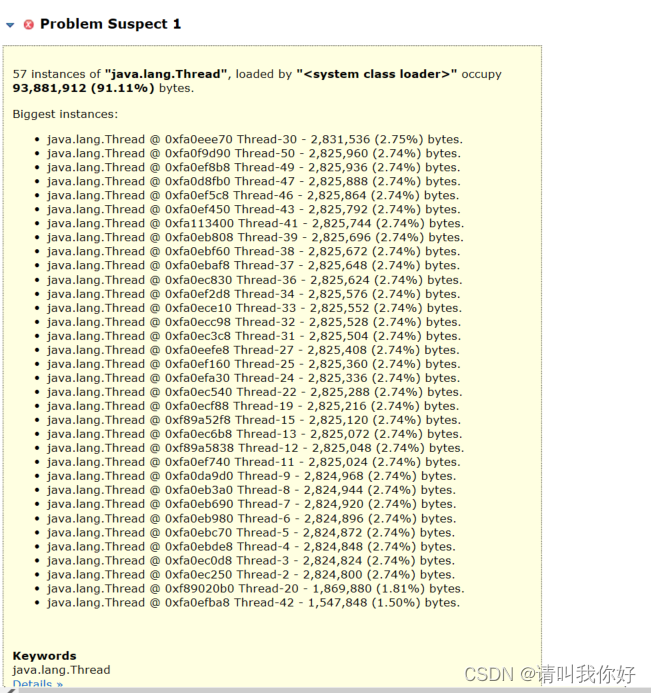
从hprof文件分析好像没看到mybatis的类啊,可以看到是因为线程持有内存太大,导致内存分配不够。难道说另有玄机?
测试用例分析
想了想,线程分配空间不够导致的oom,那测试用例里面哪里占用内存太大?
List ids = getIds(100000 + finalThreadId)-》掐指一算,java中Long类型占8个字节,按100000个算,1000008/1024=781.25M,而我分配了Xmx256m,新生代大小2560.33*0.8=67.584M,omg!!!
按照这个理论,我不使用mybatis的那个查询,好像也会OOM。
@Test
public void test2() {
AtomicInteger ai = new AtomicInteger(0);
for (int threadId = 0; threadId < 50; threadId++) {
int finalThreadId = threadId;
new Thread(() -> {
List<Long> ids = new ArrayList<>();
for (long i = 0; i < 1000000; i++) {
ids.add(i);
}
// Long aLong = userMapper.selectCnt(ids);
try {
//为了让线程持有
TimeUnit.SECONDS.sleep(100);
} catch (Exception e) {
e.printStackTrace();
}
ai.getAndIncrement();
System.out.println(finalThreadId + "::开始了");
}).start();
}
while (ai.get() < 50) {
}
System.out.println("结束。。。。。。。。。。");
}
[Full GC (Ergonomics) [PSYoungGen: 29695K->29695K(58368K)] [ParOldGen: 174696K->174696K(175104K)] 204392K->204392K(233472K), [Metaspace: 38142K->38142K(1085440K)], 0.1527073 secs] [Times: user=1.25 sys=0.00, real=0.15 secs]
[Full GC (Ergonomics) [PSYoungGen: 29695K->29695K(58368K)] [ParOldGen: 174697K->174697K(175104K)] 204393K->204393K(233472K), [Metaspace: 38142K->38142K(1085440K)], 0.1420339 secs] [Times: user=1.09 sys=0.00, real=0.14 secs]
java.lang.OutOfMemoryError: GC overhead limit exceeded
Dumping heap to java_pid500480.hprof ...
好像也是OOM了!
可以看到我将代码中的mapper查询给去掉,只是在里面new了1000000个Long数字,报的是一样的错。。。所以导致oom的真凶其实不是mybatis?
测试一下把sql填长一点,看看是不是mybatis的锅?
<select id="selectCnt" resultType="java.lang.Long">
select count(*) from (
<foreach collection="ids" item="id" separator=" union all ">
select count(*) from user where id = #{id}
</foreach>) t
</select>
for (int threadId = 0; threadId < 50; threadId++) {
int finalThreadId = threadId;
new Thread(() -> {
List<Long> ids = new ArrayList<>();
for (long i = 0; i < 10000; i++) {
ids.add(i);
}
Long aLong = userMapper.selectCnt(ids);
ai.getAndIncrement();
System.out.println(finalThreadId + "::开始了");
}).start();
}
Cause: java.sql.SQLException: Thread stack overrun: 246176 bytes used of a 262144 byte stack, and 16000 bytes needed. Use 'mysqld --thread_stack=#' to specify a bigger stack.
; uncategorized SQLException; SQL state [HY000]; error code [1436]; Thread stack overrun: 246176 bytes used of a 262144 byte stack, and 16000 bytes needed. Use 'mysqld --thread_stack=#' to specify a bigger stack.; nested exception is java.sql.SQLException: Thread stack overrun: 246176 bytes used of a 262144 byte stack, and 16000 bytes needed. Use 'mysqld --thread_stack=#' to specify a bigger stack.
好家伙,没有OOM,直接Thread stack overrun了,,这个错误很明显。sql拼接的太多了,直接超过sql语句线程的上限了,好家伙,先不管这个错,拼接短点,接着测OOM!!
for (int threadId = 0; threadId < 50; threadId++) {
int finalThreadId = threadId;
new Thread(() -> {
List<Long> ids = new ArrayList<>();
for (long i = 0; i < 10000; i++) {
ids.add(i);
}
Long aLong = userMapper.selectCnt(ids);
ai.getAndIncrement();
try {
TimeUnit.SECONDS.sleep(10);
} catch (Exception e) {
e.printStackTrace();
}
System.out.println(finalThreadId + "::开始了");
}).start();
}
[Full GC (Ergonomics) [PSYoungGen: 49152K->44109K(66560K)] [ParOldGen: 173371K->175100K(175104K)] 222523K->219210K(241664K), [Metaspace: 38548K->38548K(1085440K)], 0.0577932 secs] [Times: user=0.33 sys=0.00, real=0.06 secs]
[Full GC (Ergonomics) [PSYoungGen: 49152K->44505K(66560K)] [ParOldGen: 175100K->175013K(175104K)] 224252K->219518K(241664K), [Metaspace: 38548K->38548K(1085440K)], 0.0672780 secs] [Times: user=0.47 sys=0.00, real=0.07 secs]
[Full GC (Ergonomics) [PSYoungGen: 49047K->44798K(66560K)] [ParOldGen: 175013K->175013K(175104K)] 224060K->219811K(241664K), [Metaspace: 38548K->38548K(1085440K)], 0.0446176 secs] [Times: user=0.27 sys=0.02, real=0.05 secs]
java.lang.OutOfMemoryError: Java heap space
Dumping heap to java_pid503928.hprof ...
Caused by: java.sql.SQLException: Thread stack overrun: 246176 bytes used of a 262144 byte stack, and 16000 bytes needed. Use 'mysqld --thread_stack=#' to specify a bigger stack.
疯狂fullGC,顺便oom了。这结果好像我懂了?
结论:
其他文章中说的ContextMap确实在多线程环境下,且参数过多、查询时间较久的情况下会导致OOM,这是因为你的查询一直没有结束,那在进行垃圾回收的时候,是不会对正在运行的线程中存在的变量进行垃圾回收的(参考gcRoots节点),这就导致OOM,其他文章中说的减少sql拼接确实可以一定程度的避免OOM,但我认为问题的关键不是在ContextMap,而是在你的查询时间太长,导致不能进行垃圾回收,从而导致OOM。
但是导致OOM的原因是有很多的,比如上面的测试例子中没有进行mapper查询,依然会导致oom,所以究竟问题在哪,还是要分情况来看的,如果是入参多、查询慢,那你改了sql可能确实就没有oom了,因为是你直接缩短了查询时间,也就导致线程结束,从而垃圾进行回收。














 404
404











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









