







动态规划之投资分配问题(python)
投资分配问题
现有数量为a(万元)的资金,计划分配给n 个工厂,用于扩大再生产。
假设:
xi 为分配给第i 个工厂的资金数量(万元);
gi(xi)为第i 个工厂得到资金后提供的利润值(万元)。
问题:如何确定各工厂的资金数,使得总的利润为最大。
下表为各工厂获得投资后可以产生的利润:
| 利润\投资 | 0 | 10 | 20 | 30 | 40 | 50 | 60 |
|---|---|---|---|---|---|---|---|
| g1(x) | 0 | 20 | 50 | 65 | 80 | 85 | 85 |
| g2(x) | 0 | 20 | 40 | 50 | 55 | 60 | 65 |
| g3(x) | 0 | 25 | 60 | 85 | 100 | 110 | 115 |
| g4(x) | 0 | 25 | 40 | 50 | 60 | 65 | 70 |
问题分析
根据上述的问题可知我们需要求解最大的目标收益Z

用fk(x) 表示 以数量为 x 的资金分配给前k 个工厂,所得到的最大利润值。
用动态规划求解,就是求 fn(a) 的问题。
当K=1时,
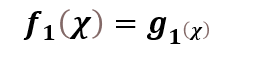
当1<K≤𝒏时,
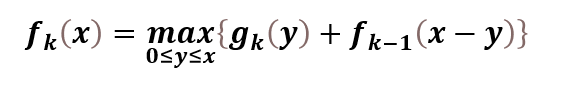
代码设计
数据初始化
由于这里是一个mn的二维表,所以采用一个二维列表values(维度:47)来存储各个工厂接受投资后产生的收益
values = [
[0, 20, 50, 65, 80, 85, 85],
[0, 20, 40, 50, 55, 60, 65],
[0, 25, 60, 85, 100, 110, 115],
[0, 25, 40, 50, 60, 65, 70]
]
函数设计
- 动态规划函数,
- 在动态规划函数中,首先获取投资项目数以及投资金额数目。
- 构造一个三维列表(4X7X4)s和一个二维列表(4X7)dp,来分别存储最优投资组合和对应的投资组合的收益。
- 函数具体实现是通过一个三层for循环结构,外面两层for循环是遍历二维列表s,dp的,第三个for循环是实现寻找上一次组合和这一次的投资项目与进行新的组合的最大值。
值的注意的是下面的这行
s[i][j] = s[i - 1][j - k].copy()
这里涉及到python列表的直接赋值是引用赋值,所以为了避免引用赋值而导致的程序错误,这里使用了浅拷贝来完成对数组的复制
# 实现动态规划的函数
def invest_f(values):
m = len(values) # 投资项目数
n = len(values[0]) # 投资金额
dp = [[0 for i in range(n)] for j in range(m)]
s = [[[0] for i in range(n)] for j in range(m)]
for i in range(m):
for j in range(n):
if i == 0:
dp[i][j] = values[i][j]
s[i][j] = [j * 10]
else:
for k in range(j + 1):
if dp[i][j] < dp[i - 1][j - k] + values[i][k]:
dp[i][j] = dp[i - 1][j - k] + values[i][k]
s[i - 1][j - k].append(k * 10)
s[i][j] = s[i - 1][j - k].copy()
s[i - 1][j - k].pop()
return dp, s
- 为了使得矩阵输出得比较好看,这里单独写了一个矩阵输出函数
# 矩阵输出的更加好看
def print_matrix(p):
print("[")
for i in range(len(p)):
print(p[i])
print("]")
- 函数调用以及结果输出
dp, s = invest_f(values)
print("最大的投资收益矩阵为:")
print_matrix(dp)
print("最大的投资组合矩阵为:")
print_matrix(s)
print("最大的投资收益为:", dp[-1][-1])
问题最优化结果


投资分配问题代码错误改进
从上述两张表中对比可以发现:
在求F4(x)的时候,代码显示的F4(x)策略是[0,10,0]而最终问题的答案却是[0,0,10,0]
在代码中显示的[0,10,0]的意思应理解为,
- 第一,三,四项目均为投0元,第二个项目投10万元
而根据手动计算得知应为[0,0,10,0]
- 第一,二,四项目均为投0元,第三个项目投10万元
函数重构
在原有的基础上,添加了一个f标志,记录在k循环过程中。
是否添加了元素进入列表,若没有添加新元素,需要补0操作
def invest_f(values):
m = len(values) # 投资项目数
n = len(values[0]) # 投资金额
dp = [[0 for i in range(n)] for j in range(m)]
s = [[[0] for i in range(n)] for j in range(m)]
for i in range(m):
for j in range(n):
if i == 0:
dp[i][j] = values[i][j]
s[i][j] = [j * 10]
else:
f = 0
for k in range(1, j + 1):
if dp[i][j] < dp[i - 1][j - k] + values[i][k]:
f += 1
dp[i][j] = dp[i - 1][j - k] + values[i][k]
s[i - 1][j - k].append(k * 10)
s[i][j] = s[i - 1][j - k].copy()
s[i - 1][j - k].pop()
if f == 0:
s[i - 1][j - k].append(0)
s[i][j] = s[i - 1][j - k].copy()
s[i - 1][j - k].pop()
return dp, s
结果对比

由上图对比可知,重构后代码与手动计算结果已经一样了
投资问题代码优化
优化分析
实际上我们需要的只是最后的投资方案以及对应的投资收益而已,那么我们其实只需要记录添加第i个项目时的最优投资方案以及最大收益和第i-1个项目的最优投资方案以及最大收益。
那么如何实现只有添加第i个项目和第i-1个项目的结果呢?
- 双列表
第一个列表记录第i-1个项目的结果,第二个列表记录第i个项目的结果。然后再将第i个项目的结果值引用赋值给第1个列表,然后i++,实现下层迭代计算。
这样的话可以将原有的二维列表dp,三维列表s的各维度分别由原来的(4X7)和(4X7X4)降至(2X7)和(2X7X4)
这里我偷懒一下我觉得这种方法没有第二种方法好,所以没有具体实现。 - 第二层for循环从后至前遍历
根据问题分析里面的递推公式可知
当K=1时,
当1<K≤𝒏时,
当添加第k个项目且当前投资为jX10时,该项目的最优方案计算,只与添加第k-1个项目的前j个值有关。
从后往前遍历,当更新dp[j]时,dp[1],dp[2],…,dp[j-1]都是未更新的,也就是添加第i-1个项目时的最优值,根据未更新的dp[1],dp[2],…,dp[j-1]来更新dp[j],然后j–,更新下一个dp[j]
这样我们就可以再次将s,dp进行简化。将原本的三维(4X7X4)的s列表精简至二维的(7X4)列表,将二维的(4X7)精简为的一维的含有7元素的列表。
具体修改后的代码如下所示:
def invest_f(values):
n = len(values)
m = len(values[0])
dp = [0 for _ in range(m)]
s = [[0] for _ in range(m)]
for i in range(n):
for j in range(m - 1, -1, -1):
if i == 0:
dp[j] = values[i][j]
s[j] = [j * 10]
else:
f = 0
for k in range(j, 0, -1):
if dp[j] < dp[j - k] + values[i][k]:
f += 1
dp[j] = dp[j - k] + values[i][k]
s[j - k].append(k * 10)
s[j] = s[j - k].copy()
s[j - k].pop()
if f == 0:
s[j].append(0)
return dp, s
更改后的函数调用以及输出
# 将各工厂投资0-5万的收益放进一个二维数组
values = [
[0, 20, 50, 65, 80, 85, 85],
[0, 20, 40, 50, 55, 60, 65],
[0, 25, 60, 85, 100, 110, 115],
[0, 25, 40, 50, 60, 65, 70]]
dp, s = invest_f(values)
print("最大的投资收益矩阵为:\n", dp)
print("最大的投资组合矩阵为:\n")
print_matrix(s)
print("最大的投资收益为:{0}\n最大的投资组合:{1}".format(dp[-1], s[-1]))
结果对比

由于我这一次的dp列表和s只存储了最后的方案,所以前几项的方案都看不了。
但是最后一行的结果是绝对正确的。
总结
问题
- python列表的引用传递产生的问题
- 投资组合更新时的未找到k时产生的组合数缺失
解决办法
- 使用python列表的浅拷贝函数
- 创建变量f,标志在k循环中,是否找到合适的k。若没有找到则执行在对应的投资组合中进行补0操作














 1348
1348











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









