






在之前博客中,我们手动推导了一元线性回归的参数表示。在回归问题中,一元线性回归算是最简单的回归模型,但在实际应用中,真正满足线性分布的场景很少,只跟一个参数有关的一元线性回归场景就更少了(多元线性回归的推导思路与一元线性回归类似。无非就是参数维度变高),如果仍用线性回归去拟合分布,效果将会很差,模型也没有价值。此时,我们引入树模型来解决回归问题,树模型包含分类树(Classification Tree,里面按照分类准则不同又可细分为ID3、C4.5和CART)和回归树(Regression Tree)两种,这里自然是选择回归树。
1.回归树原理
在回归树的生成中,我们要考虑的核心问题就是:最优切分点和最优输出值的选择。确定一个切分点后,对训练样本进行划分,针对划分后的样本,确定一个最优输出值,作为该切分点特征下的输出预测值。如此递归生成下去,得到最终的树型结构。当预测新样本时,按照新样本特征选择相应分支,得到预测值。
切分点的选择一般采用启发式方法,并无定法。但是关于最优输出值,我们肯定希望该预测值能使得在训练样本下的误差最小。回归问题最常用的损失函数就是均方差损失,所以我们在此构建回归树的损失函数:

通过上述证明可以看出,同一子树下样本输出值的平均值就是该子树的最优输出值,因为该值是使该子树下所有训练样本均方误差最小的值。以此类推,求出各节点下的最优输出值,此时就得到一个回归树。在给定一个新样本做预测时,按照新样本特征选择不同分支走向,直至取到预测值。这也是回归树模型解决回归问题的做法。
在明确了最优输出值的求法之后,我们不妨回头来想一下最优切分点的选取。一个切分点会将样本分成两部分,在各自部分我们选择该部分下所有样本的平均值来作为最优输出值,使得该部分下的误差最小,将两个部分的误差加总就得到该回归树的总体误差。那么我们选择不同切分点得到不同的回归树,计算各回归树的误差,最后选择误差最小的那棵回归树,该树的切分点也就是最优切分点。
2.实际案例推导及代码实现
假设存在这样一组训练集样本:
| 样本序号 | (1) | (2) | (3) | (4) | (5) | (6) | (7) | (8) | (9) | (10) |
| X | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| Y | 5.56 | 5.7 | 5.91 | 6.4 | 6.8 | 7.05 | 8.9 | 8.7 | 9 | 9.05 |
其中X为样本特征取值,Y为样本输出值,这是一个回归类的训练样本集,我们以此来生成一个回归树:
按照上述解释,首先我们确认好切分点,这里选择为1.5、2.5、3.5...到10.5,切分点定好后,按照切分点就可将所有样本划分到不同子树,下面就是确认各子树的输出值,由上述证明可知,取平均值可使误差最小,即可得到这样的回归树:
| 切分点 | 1.5 | 2.5 | ... | 6.5 | 7.5 | 10.5 |
| 左子树输出值 | 5.56 | 5.63 | 6.2366 | 6.6171 | 7.307 | |
| 右子树输出值 | 7.5011 | 7.72625 | 8.9125 | 8.9166 | 0 | |
| 左子树误差 | 0 | 0.0049 | 0.3096 | 1.134 | 1.9114 | |
| 右子树误差 | 1.747 | 1.509 | 0.01796 | 0.02388 | 0 | |
| 整棵树总误差 | 1.747 | 1.5139 | 0.32756 | 1.15788 | 1.9114 |
对计算过程做简单介绍:假设现在切分点取6.5,样本(1)到(6)被划分到左子树,剩余样本被划分到右子树,对于左子树样本,最优输出值为:
(5.56+5.7+5.91+6.4+6.8+7.05)/6=6.2366
同理右子树输出值为:
(8.9+8.7+9+9.05)/4=8.9125
再计算各子树的损失,这里损失为均方误差:
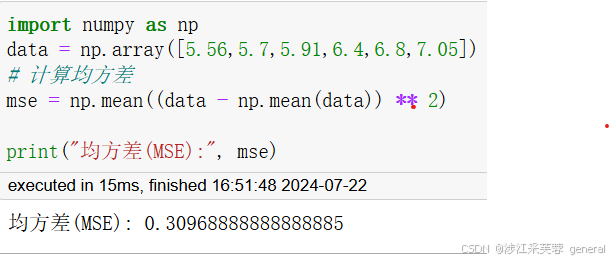

由上述计算可得到,当切分点选择6.5时,整个回归树的误差最小,得到一个深度为1的二叉回归树,左右子树输出值分别为6.2366和8.9125。同时上文也说过,回归树的生成是递归的,在得到这样一个回归树后,我们还可以接着对左右子树再做切分,再各自生成一个回归树。这时得到的回归树,相较于初始,复杂度提升,对样本的拟合程度也进一步提高,误差也进一步减小。生成过程如下:
对于样本(1)到(6)的进一步划分
| 切分点 | 1.5 | 2.5 | 3.5 | 4.5 | 5.5 | 6.5 |
| 左子树输出值 | 5.56 | 5.63 | 5.723 | 5.8925 | 6.074 | 6.2366 |
| 右子树输出值 | 6.372 | 6.54 | 6.75 | 6.925 | 7.05 | 0 |
| 左子树误差 | 0 | 0.0049 | 0.020689 | 0.101369 | 0.21286 | 0.309689 |
| 右子树误差 | 0.2617 | 0.18605 | 0.071667 | 0.015625 | 0 | 0 |
| 整棵树总误差 | 0.2617 | 0.19095 | 0.092356 | 0.116994 | 0.21286 | 0.309689 |
对于样本(7)到(10)的进一步划分
| 切分点 | 7.5 | 8.5 | 9.5 | 10.5 |
| 左子树输出值 | 8.9 | 8.8 | 8.866 | 8.9125 |
| 右子树输出值 | 8.9166 | 9.025 | 9.05 | 0 |
| 左子树误差 | 0 | 0.01 | 0.0155 | 0.01769 |
| 右子树误差 | 0.02388 | 0.000625 | 0 | 0 |
| 整棵树总误差 | 0.02388 | 0.010625 | 0.0155 | 0.01769 |
下面利用sklearn中的回归树库函数做简单验证:
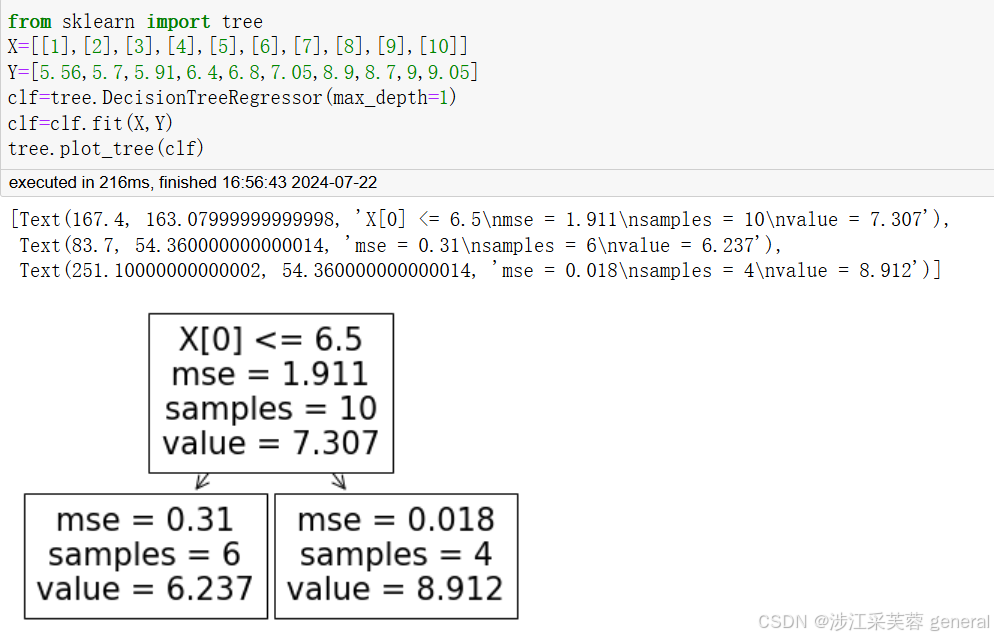
这里可以看出,在限定树的深度为1时,得到以6.5为切分点的一棵回归树,左子树输出值value为6.237,samples为6,即样本(1)到(6),左子树误差MSE为0.31,与我们计算结果很接近;同理右子树输出值为8.912,samples为4,即剩余四个样本全部分在右子树,右子树误差为0.018。至于根节点,样本还未进行划分,整体训练样本的最优输出值为整体样本的平均值,value为7.307,MSE为1.911,我们计算结果为1.9114,也很接近。

这里加深树的深度,回归树会对做左右子树再次进行划分,对于左子树的样本(1)到(6),可以看到切分点选择为3.5时误差最小,即样本(1)到(3)分到一个子树下,样本(4)到(6)分到一个子树,各自输出值也是样本值的平均值。与我们计算过程得到的结果也很吻合。这样我们就得到一个深度为2的回归树,假如节点足够多,回归树就可以一直生成下去。
最后照例要说的就是回归树模型的优缺点了,在回归树的整个生成过程中,最优输出值的选择是通过损失函数计算得到,最佳切分点是通过比较不同切分点生成的树的误差得到,可解释性高且易于理解。但它的缺点也十分明显。首先对于异常数据较敏感,假如某个样本值明显超出其余样本,在回归树生成中,异常值对于最终输出值的影响也会变大,导致最终的输出结果错误。另外就是泛化性能不强,容易陷入过拟合的局面。比如下面例子:

在给到一个新样本特征值为500时,按照生成的回归树,500>6.5,走右子树,500>8.5,再走右子树,此时输出预测值为9.025,常理来看,这个预测值肯定不对,但由于该树只能预测于此,陷入过拟合的局面。
3.总结
以上就是关于回归树生成时涉及到的所有相关理论和证明过程,可以看出原理不复杂,生成过程的每一步也是有据可循,这就是它的优点所在,可解释性和易于理解,但囿于训练集和异常数据,在应用中往往会陷入过拟合问题,这就需要我们在解决处理实际问题时灵活运用。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









