







一、前言
最近在看崔庆才先生编写的《Python3网络爬虫开发实战》这本书,学习了requests库和正则表达式,爬取猫眼电影top100榜单是这本书的第一个实例,主要目的是要掌握requests库和正则表达式在实际案例中的使用。
二、开发环境
运行平台: Windows 10
Python版本: Python3.6
IDE: PyCharm
三、爬取思路
- 抓取单页内容
- 正则表达式提取有用信息
- 保存信息
- 下载TOP100所有电影信息
- 多线程抓取
爬取单页内容
首先打开Chrome浏览器,打开猫眼电影网站(http://maoyan.com/)然后点击榜单,点击TOP100榜。
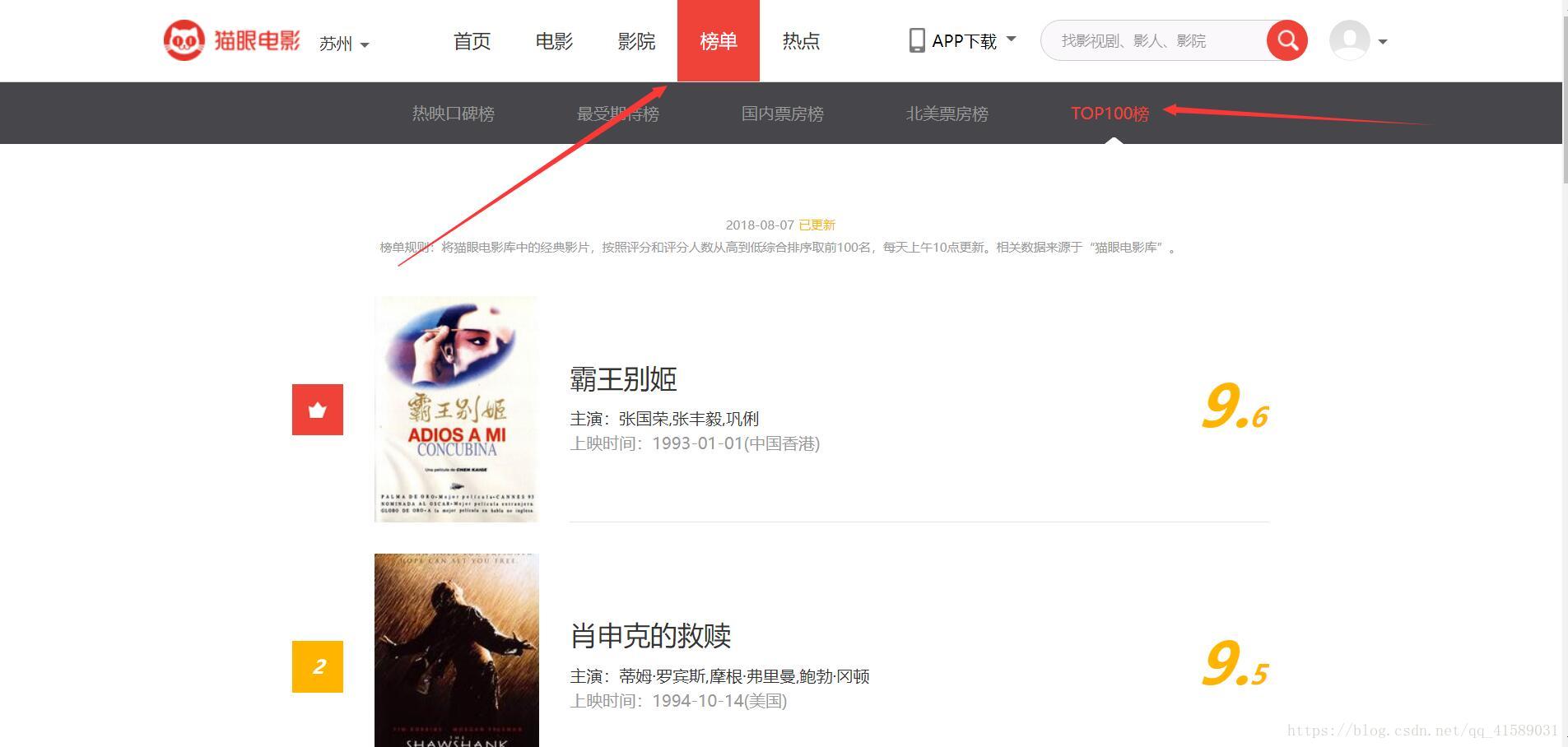
然后通过requests库将整个HTML代码获取下来:
import requests
from requests.exceptions import RequestException #捕捉异常
def get_one_page(url):
'''
获取网页html内容并返回
'''
try:
# 获取网页html内容
response = requests.get(url)
# 通过状态码判断是否获取成功
if response.status_code == 200:
return response.text
return None
except RequestException:
return None
def main():
url = 'http://maoyan.com/board/4'
html = get_one_page(url)
print(html)
if __name__ == '__main__':
main()正则表达式提取有用信息
然后按F12,查看网页的源代码,
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章















 4385
4385











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









