




 本文探讨了如何使用SQL查询2025年内岗位投递简历数量按月降序及订单详情,涉及日期格式转换、分组聚合、子查询和窗口函数的应用。
本文探讨了如何使用SQL查询2025年内岗位投递简历数量按月降序及订单详情,涉及日期格式转换、分组聚合、子查询和窗口函数的应用。
1.日期格式转换函数 date_format(date,format)
查询在2025年内投递简历的每个岗位,每一个月内收到简历的数量,并且按先按月份降序排序,再按简历数目降序排序。
select job,date_format(date,'%Y-%m') as mon,sum(num) as cnt
from resume_info
where date like '2025%' -- 符合最左前缀匹配原则,也走索引
group by job,mon
order by mon desc,cnt desc;
2.请你写出一个sql语句查询在2025-10-15以后,同一个用户下单2个以及2个以上状态为购买成功的C++课程或Java课程或Python课程的user_id,并且按照user_id升序排序。

分析:按照user_id分组之后,统计条目个数,再加上一些条件即可。易错点在于,where不能筛选聚合函数,应该用having。
答案:
SELECT user_id
FROM order_info
where date>'2025-10-15'
-- and COUNT(*)>=2
and status='completed'
and product_name in ('C++','Java','Python')
GROUP BY user_id
HAVING COUNT(*)>1
ORDER BY user_id;
3.请你写出一个sql语句查询在2025-10-15以后,同一个用户下单2个以及2个以上状态为购买成功的C++课程或Java课程或Python课程的订单信息,并且按照order_info的id升序排序。
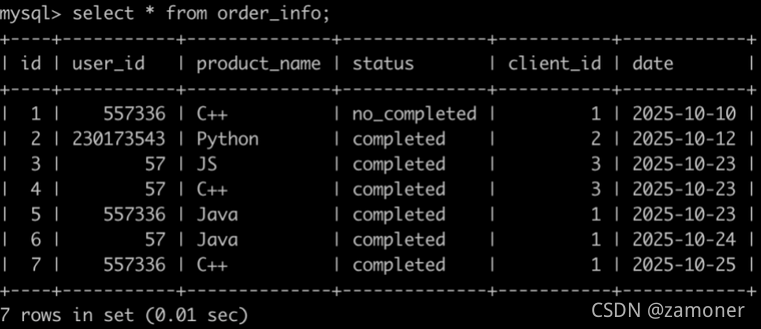
用mysql这样写会报出答案错误,输出数据不完整:
select *
from order_info
where date>'2025-10-15'
and status='completed'
and product_name in ('C++','Java','Python')
GROUP by user_id
having COUNT(*)>=2
order by id;

论坛说是group by出了问题,翻了下书(SQL必知必会):select语句中的每一列都必须在group by 子句中给出(groupby中不能出现聚集函数,但select语句中可以出现group by中未出现的聚集函数),所以就是要select多列数据,而仅仅只group by一列数据的话,就会报错或者结果不全。接着考虑两种思路:
一是子查询。先把符合条件的出来的user_id找出来(也可以考虑创建视图),然后外表再把符合该user_id的记录找出来。
select *
from order_info
where datediff(date,"2025-10-15")>0
and product_name in ("C++","Java","Python")
and status="completed"
and user_id in (
select user_id
from order_info
where datediff(date,"2025-10-15")>0
and product_name in ("C++","Java","Python")
and status ="completed"
group by user_id
having count(id)>1
)
order by id;
二是开窗函数。用count()作为窗口函数,根据user_id进行分组得到的结果作为内表的新列,外表再查询这个新列大于等于2的所有条目。
select t1.id, t1.user_id,t1.product_name,t1.status,t1.client_id,t1.date
from
(
select *,count(id) over(partition by user_id) as number
from order_info
where datediff(date,"2025-10-15")>0
and status ="completed"
and product_name in ("C++","Java","Python")
) t1
where t1.number >1
order by t1.id
总结:当遇到要取出来的列多余聚合用的列的时候,先考虑开窗函数。还有就是,查询出来的东西想要作为一个表的时候,记得命名。
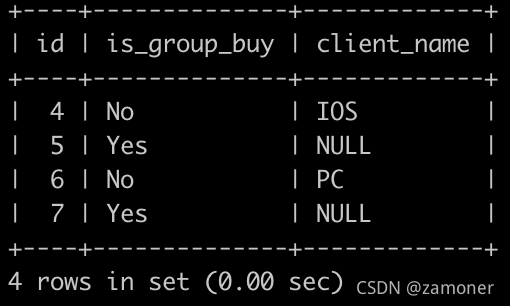
4.请你写出一个sql语句查询在2025-10-15以后,同一个用户下单2个以及2个以上状态为购买成功的C++课程或Java课程或Python课程的订单id,是否拼团以及客户端名字信息,最后一列如果是非拼团订单,则显示对应客户端名字,如果是拼团订单,则显示NULL,并且按照order_info的id升序排序。
两个表:
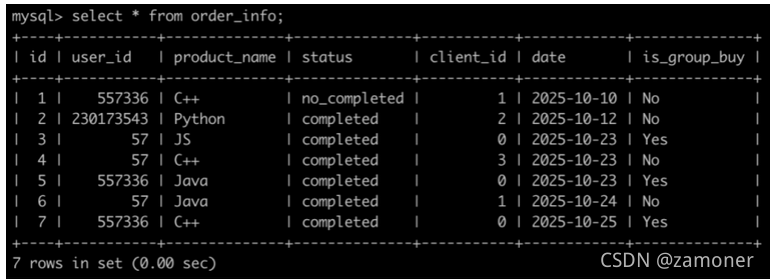
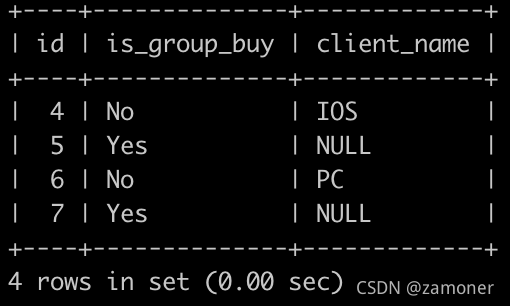
要求输出:
分析:为了理清思路和增加可读性,我一开始想的是先查一个表出来而不用临时表,再在这个表上操作。(后来查了下with as和视图的区别,说是可以对视图进行增删改查操作,不删除就会一直留在那,而with是一次性的,不能进行增删改查)如下图,但这段代码漏洞百出。首先第一个字符左括号就是错的,不能这样写。应该用with as 或者创建视图,接着having 语句出错,报错内容如下,因为having之前必须使用groupby语句。而且,窗口函数使用完之后还不能用where进行过滤,应该再写一个查询使用where。
(select *,count(id) over(partition by user_id) as number
from order_info
where date>"2025-10-15"
and product_name in ('C++', 'Python', 'Java')
and status = 'completed'
having number>1) as t1;
SELECT o.id,is_group_buy,client_name
FROM t1 o left join client c on o.client_id=c.id
order by t1.id;
SQL_ERROR_INFO: a GROUP BY clause is required before HAVING
正确答案:
with t1 as
(select *,count(id) over(partition by user_id) as number
from order_info
where date>"2025-10-15"
and product_name in ('C++', 'Python', 'Java')
and status = 'completed'
)
SELECT t1.id,t1.is_group_buy,c.name as client_name
FROM t1 left join client c on t1.client_id=c.id
where t1.number>1
order by t1.id;

















 1027
1027

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









